Facebook извинился за нецензурный перевод имени Си Цзиньпина
- 19.01.20 12:16 msk
- Китай
- СМИ и интернет
Си Цзиньпин. Фото с сайта English.gov.cn
Facebook извинился за техническую ошибку, в результате которой имя китайского лидера Си Цзиньпина было нецензурно переведено на английский язык. Об этом сообщает Reuters.
Ошибка была допущена на фоне визита лидера КНР в Мьянму, в ходе которого он встретился с главой правительства Аун Сан Су Чжи. Сообщение о визите было размещено на ее официальной странице в Facebook, но при переводе с бирманского на английский там появлялись многочисленные упоминания «Mr Shithole» (варианты перевода – «свинарник» или «задница»). Это слово также появилось при переводе заголовка новости одного из местных изданий.
Представители Facebook заявили, что техническая ошибка уже устранена, пообещав принять меры, чтобы подобное не повторилось.
В компании уточнили, что имени Си Цзиньпина не было в базе данных бирманского словаря, так что система сочла его незнакомым словом и попыталась перевести. При переводе схожих слов, как оказалось, также предлагался вариант «Shithole».
МИД Китая, по информации агентства, отказался комментировать инцидент.
Ранее Facebook уже сталкивался с трудностями при переводе с бирманского. В 2018 году, как отмечает агентство, эта функция была временно отключена.
Несколько лет назад компания также принесла извинения, после того как ошибочный перевод поста палестинского строителя привел к его задержанию израильскими полицейскими. Палестинец тогда опубликовал фото на фоне бульдозера с пожеланием доброго утра на арабском. Однако система перевела запись на английский как «призыв к атаке».
Читайте также
-
06 марта
06.03
Казахстанский Мориарти или козел отпущения?
Кто такой Аркадий Клебанов (Маневич), объявленный организатором атак на представителей СМИ
-
27 февраля
27.
 02
02Охота на журналистов
Кто стоит за нападениями на представителей независимых СМИ в Казахстане
-
22 декабря
22.12
Фото
«Выгодное использование транзитных возможностей»
Казахстан построит под Ташкентом транспортно-логистический терминал
-
16 сентября
16.09
Александр Рыбин
Долгожданная встреча — на фоне боевых действий
Как прошел саммит ШОС в Самарканде
-
15 сентября
15.09
ШОС. Прибытие
В Самарканде для участия в мероприятиях саммита ШОС соберутся руководители почти 20 государств
-
20 августа
20.08
«Ярое проявление русофобии»
Как Казахстан оказался в эпицентре информационной войны
 02
02-
Год при талибах
Что изменилось в Афганистане после повторного захвата власти радикалами
-
Родина следит за тобой
Зачем журналисты усложнили жизнь выигравшей Уимблдон казахстанской теннисистке Елене Рыбакиной
-
Общественность осуждает, МВД защищается
В Узбекистане участились конфликты между журналистами и сотрудниками МВД
-
Занимается ядерной безопасностью и пишет мемуары
В Telegram-канале казахстанского политолога внезапно появилось интервью с Нурсултаном Назарбаевым
Facebook начал тестировать автоматический перевод сообщений в Messenger
Режим чтения включен
Режим чтения увеличивает текст, убирает всё лишнее со страницы и даёт возможность сосредоточиться на материале. Здесь вы можете отключить его в любой момент.
Здесь вы можете отключить его в любой момент.
Режим чтения
Facebook тестирует автоматический перевод сообщений в Messenger, сообщает CNET. Опция работает схоже с тем, как работает перевод постов и комментариев в соцсети.
Сейчас опцию M Translations тестируют американские и мексиканские пользователи — им доступен перевод с английского на испанский и наоборот. Переводчик станет частью искусственного интеллекта M Suggestions.
- При получении сообщения на испанском M Translations спрашивает у пользователя, желает ли он перевести сообщение. Можно настроить автоматический перевод для всех сообщений.
- В будущем Facebook добавит в M Translations больше языков и стран.
Нашли ошибку? Выделите ее и нажмите Ctrl+Enter
#Facebook #IT #Messenger #Test #Translation #Америка #Интеллект #Коммент #Оборот #Общение #Сети #Сообщения
Расширение автоматического машинного перевода на другие языки
Часть миссии Facebook по сближению мира состоит в преодолении языковых барьеров и предоставлении каждому возможности взаимодействовать с контентом на предпочитаемом им языке.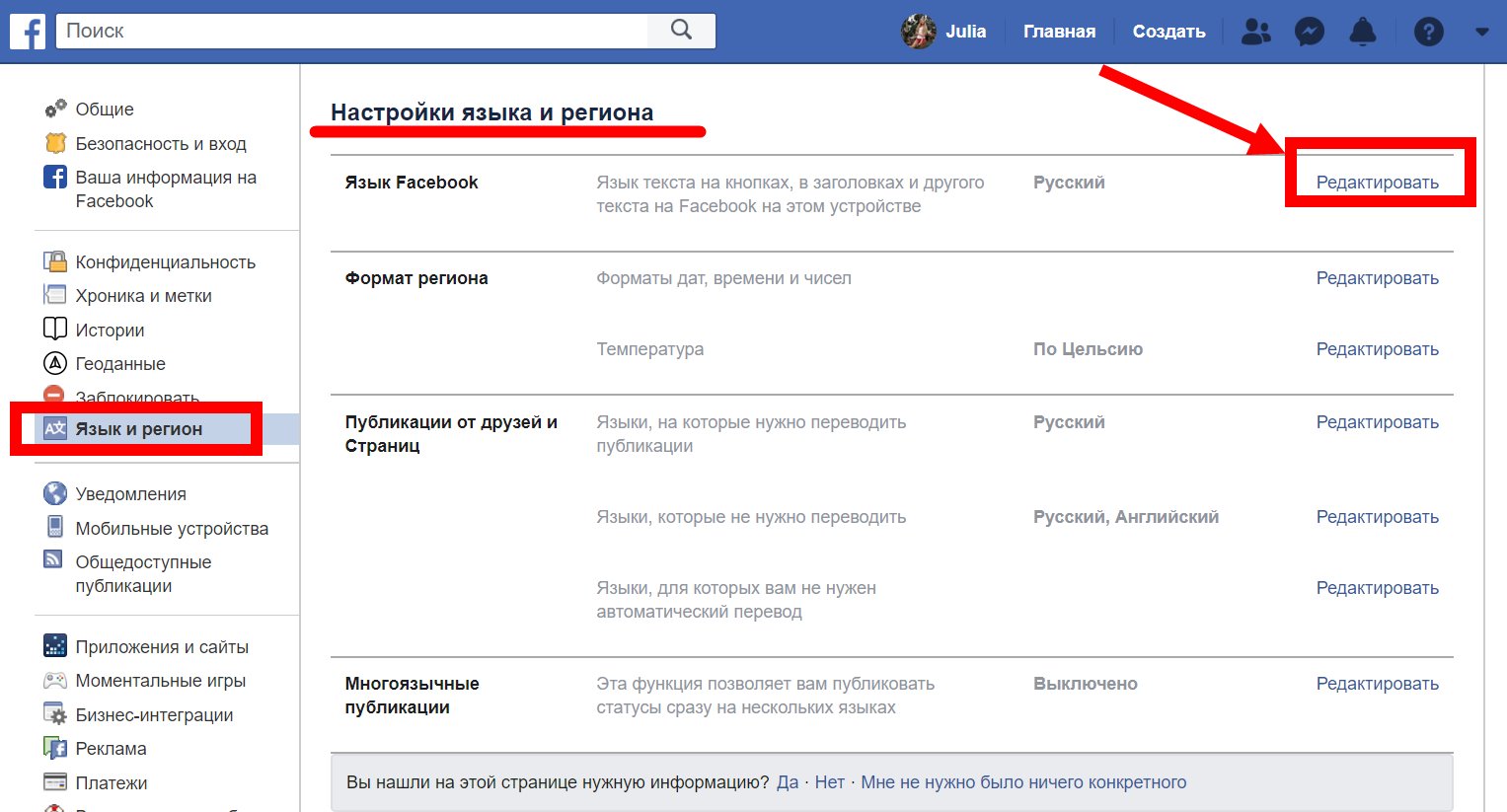 Перевод большего количества контента на большее количество языков также помогает нам лучше выявлять контент, нарушающий политику, и расширять доступ к продуктам и услугам, предлагаемым на наших платформах. Если учесть количество используемых языков и объем контента на этих платформах, мы обслуживаем наше сообщество почти 6 миллиардов переводов в день. При использовании традиционных методов на профессиональный перевод контента одного дня могут уйти годы. Предоставление автоматического перевода в нашем масштабе и объеме требует использования искусственного интеллекта (ИИ) и, в частности, нейронного машинного перевода (NMT).
Перевод большего количества контента на большее количество языков также помогает нам лучше выявлять контент, нарушающий политику, и расширять доступ к продуктам и услугам, предлагаемым на наших платформах. Если учесть количество используемых языков и объем контента на этих платформах, мы обслуживаем наше сообщество почти 6 миллиардов переводов в день. При использовании традиционных методов на профессиональный перевод контента одного дня могут уйти годы. Предоставление автоматического перевода в нашем масштабе и объеме требует использования искусственного интеллекта (ИИ) и, в частности, нейронного машинного перевода (NMT).
Качество наших моделей перевода улучшилось с тех пор, как мы перешли на нейронные сети, но до недавнего времени технические проблемы не позволяли нам увеличить количество языков, которые мы обслуживаем. В 2018 году группа Facebook Language and Translation Technologies (LATTE) решила изменить это и достичь цели «ни один язык не остается без внимания». Наши основные проблемы включали нехватку ресурсов для обучения (большинство этих языков не имеют достаточного количества готовых человеческих переводов) и необходимость найти способ достаточно быстро обучать системы для быстрого создания пригодных для использования переводов.
Сегодня мы с гордостью делимся результатами этих усилий и объявляем о добавлении 24 новых языков в наши службы автоматического перевода. В настоящее время мы обслуживаем переводы в общей сложности для 4504 языковых направлений (пара языков, между которыми мы предлагаем перевод, например, с английского на испанский).
Новые поддерживаемые языки в 2018 году:
- Сербский
- Белорусский
- маратхи
- сингальский
- Телугу
- Непальский
- Каннада
- Гуджарати
- Пенджаби
- Урду
- Малаялам
- Камбоджийский
- пушту
- Монгольский
- Хауса
- Зулу
- Коса
- Амхарский
- Сомалийский
- Суахили
- Романизированный арабский
- Романизированный бенгальский
- Романизированный хинди
- Романизированный урду
Ранний прогресс
Системы перевода для многих из этих языков находятся на начальном этапе, и производимые ими переводы далеки от профессионального качества. Тем не менее, системы производят полезные переводы, которые передают суть исходного значения, и они дают нам возможность итеративно улучшать качество.
Тем не менее, системы производят полезные переводы, которые передают суть исходного значения, и они дают нам возможность итеративно улучшать качество.
Примеры переводов на каждом этапе по шкале качества.
Малоресурсные эксперименты по переводу
Большинству систем перевода требуются параллельные данные или парные переводы для использования в качестве обучающих данных. В Интернете доступны большие коллекции переводов, в основном из международных организаций, таких как Организация Объединенных Наций, Европейский союз и парламент Канады. К сожалению, эти легкодоступные параллельные корпуса существуют только для нескольких языков.
Основная проблема, с которой мы столкнулись при создании систем перевода для новых языков, заключалась в достижении такого уровня качества перевода, который позволял бы получать пригодные для использования переводы при отсутствии большого количества параллельных корпусов. Отсутствие данных также является проблемой для NMT, который использует модели с большим количеством параметров и более чувствителен к качеству данных. Чтобы лучше понять, что помогает в условиях ограниченных ресурсов, мы провели несколько экспериментов. Мы использовали баллы BLEU (метрика, которая измеряет степень совпадения между сгенерированным переводом и профессиональным эталоном) для измерения качества перевода. Мы обучили модели NMT с помощью фреймворка PyTorch Translate с открытым исходным кодом, преобразовали их в формат ONNX и использовали в производственной среде Caffe2. В целом, мы экспериментировали с тремя основными стратегиями:
Чтобы лучше понять, что помогает в условиях ограниченных ресурсов, мы провели несколько экспериментов. Мы использовали баллы BLEU (метрика, которая измеряет степень совпадения между сгенерированным переводом и профессиональным эталоном) для измерения качества перевода. Мы обучили модели NMT с помощью фреймворка PyTorch Translate с открытым исходным кодом, преобразовали их в формат ONNX и использовали в производственной среде Caffe2. В целом, мы экспериментировали с тремя основными стратегиями:
1) Увеличение помеченных данных в домене
Сообщения и сообщения Facebook сильно отличаются от других типов текста: они обычно короче, менее формальны и содержат сокращения, сленг и опечатки. Чтобы научиться их переводить, нам нужно предоставить алгоритмам хорошие примеры перевода постов в социальных сетях. С этой целью мы вручную помечаем (профессионально переводим) общедоступные сообщения. Чтобы масштабироваться на все языки, которые мы охватывали, мы автоматизировали несколько наших процессов. Например, мы автоматизировали подбор и подготовку этих постов. Затем мы ранжировали их, чтобы максимизировать охват (т. е. убедиться, что мы получаем переводы, которых у нас еще нет). Затем мы автоматически еженедельно отправляли их на профессиональный перевод различным поставщикам переводов. В общей сложности мы вручную разметили миллионы слов на 25 языках.
Например, мы автоматизировали подбор и подготовку этих постов. Затем мы ранжировали их, чтобы максимизировать охват (т. е. убедиться, что мы получаем переводы, которых у нас еще нет). Затем мы автоматически еженедельно отправляли их на профессиональный перевод различным поставщикам переводов. В общей сложности мы вручную разметили миллионы слов на 25 языках.
Чтобы измерить эффективность данных обучения в предметной области, мы обучили системы с ними и без них, а также измерили баллы BLEU с ними и без них. В среднем мы получили +7,2 BLEU для каждого из 15 языков в эксперименте (результаты варьируются от направления к направлению). В среднем мы видим увеличение BLEU на +1,5 на каждые дополнительные 10 000 пар предложений исходных данных.
2) Исследование NMT с полуучителем
В дополнение к получению большего количества данных в предметной области мы исследовали методы с полууправлением и дополнением данных для создания дополнительных обучающих данных. Эти методы основаны на моделях с более низкой точностью, которые используются для создания искусственных обучающих данных. Например, чтобы обучить амхарско-английскую систему, мы можем обучить базовую систему перевода для англо-амхарского языка и использовать ее для перевода больших объемов одноязычных английских данных на амхарский. Затем мы используем искусственно созданные англо-амхарские данные в качестве дополнительного источника обучающих данных для амхарско-английских переводов. Это известно как обратный перевод, и он помогает в 88 процентах случаев, при общем среднем +2,5 BLEU.
Например, чтобы обучить амхарско-английскую систему, мы можем обучить базовую систему перевода для англо-амхарского языка и использовать ее для перевода больших объемов одноязычных английских данных на амхарский. Затем мы используем искусственно созданные англо-амхарские данные в качестве дополнительного источника обучающих данных для амхарско-английских переводов. Это известно как обратный перевод, и он помогает в 88 процентах случаев, при общем среднем +2,5 BLEU.
Точно так же мы исследовали использование одноязычных данных в технике, известной как копирование-цель. Здесь мы делаем копии частей наших обучающих данных и используем целевую сторону корпусов для замены исходной стороны . Для системы английский-хауса это означает, что мы возьмем данные английского языка-хауса и заменим английскую часть данных данными хауса (например, данные хауса-хауса), а затем будем использовать этот искусственный корпус в качестве дополнительного источника обучения. данные. В наших экспериментах в 88 процентах случаев это приводило к среднему улучшению +2,7 BLEU.
Интуиция, стоящая за этими двумя методами, заключается в том, что они помогают моделям с низким уровнем ресурсов лучше обучать свой декодер (компонент, который производит перевод) и производить более плавные переводы. Однако в условиях ограниченных ресурсов эти два метода имеют незначительные взаимодополняющие эффекты. Таким образом, добавление обратного перевода поверх цели копирования дает лишь умеренный выигрыш (+0,1 BLEU).
Другой метод, который мы использовали, заключался в создании детектора перевода, который может определить, когда два предложения на разных языках являются переводами друг друга. Затем мы можем использовать этот детектор для поиска переводов с многоязычных веб-страниц. Например, мы можем просмотреть страницы Википедии о Facebook на английском и камбоджийском (кхмерском) языках и автоматически сделать вывод, что មូលដ្ឋាន-ស្នាក់ការកណ្ដាល — это перевод слова «штаб-квартира». Мы использовали этот детектор перевода в CommonCrawl для поиска пар перевода на нескольких языках. Данные, полученные из CommonCrawl в качестве обучения, помогли в 70 процентах экспериментов (средний прирост +0,4 BLEU).
Данные, полученные из CommonCrawl в качестве обучения, помогли в 70 процентах экспериментов (средний прирост +0,4 BLEU).
Одно из предостережений при использовании полуконтролируемых методов заключается в том, что они могут вносить шум, когда генерируемые ими данные неточны. Это особенно вредно для NMT . Это было очевидно в наших результатах, где мы наблюдали четкое различие между ценностью, обеспечиваемой переводами, созданными человеком, и целевым копированием, обратным переводом и добытыми данными. Другим побочным эффектом полуконтролируемых методов является то, что они генерируют большие объемы данных, большая часть которых находится вне домена. То есть эти техники производят приблизительные переводы, непохожие на то, как люди пишут на Facebook. При использовании для обучения эти методы могут привести к предвзятости и сделать полученные переводы менее похожими на сообщения в социальных сетях. Поэтому мы также внедрили повышающую выборку данных в домене. То есть мы взяли те части наших данных, которые представляют собой сообщения в социальных сетях (внутри домена), и сделали несколько копий, чтобы они были хорошо представлены в наших общих обучающих данных. Это помогло создать переводы более высокого качества и более соответствующие тому, как люди пишут на Facebook. Эта техника дала дополнительные +0,4 BLEU в дополнение к целевому копированию + обратному переводу и привела к улучшениям в 100 процентах наших экспериментов.
Это помогло создать переводы более высокого качества и более соответствующие тому, как люди пишут на Facebook. Эта техника дала дополнительные +0,4 BLEU в дополнение к целевому копированию + обратному переводу и привела к улучшениям в 100 процентах наших экспериментов.
3) Использование многоязычного моделирования
Одним из найденных нами наиболее эффективных способов повышения качества системы перевода для определенного диалектного направления было ее объединение с другими родственными направлениями. Например, чтобы улучшить переводы с белорусского на английский, мы использовали связь между белорусским и украинским языками и построили многоязычную систему. В общей сложности мы протестировали семь различных систем перевода, которые имели многоязычные комбинации, каждая из которых объединяла в общей сложности от двух до четырех исходных языков в единую систему (например, с белорусского на украинский и с украинского на английский). Для языков с разными алфавитами мы применили транслитерацию ICU (International Components for Unicode) к исходной стороне, чтобы мы могли совместно использовать словари между всеми исходными языками в многоязычной системе.
Многоязычные системы, с которыми мы экспериментировали, смогли использовать сходство диалектов из одних и тех же языковых семей. Многоязычные системы превзошли двуязычные базовые показатели в среднем на +4,6 BLEU, улучшив семь из 10 направлений, с которыми мы экспериментировали. Обратите внимание, что из 15 направлений, которые мы протестировали для целей этого отчета об эксперименте, пять не подходили для нашей многоязычной установки и были протестированы только в двуязычных экспериментах, описанных выше.
Что дальше?
Мы продолжаем двигаться к нашей цели: «Ни одного языка не останется без внимания». Это означает улучшение качества переводов на все языки, переход от просто полезных к высокоточным, беглым и более человечным переводам. В долгосрочной перспективе это также означает расширение наших поддерживаемых направлений для охвата всех языков, используемых на Facebook. Это потребует сосредоточения внимания на улучшении переводов для языков с низким уровнем ресурсов .
Мы уже инвестируем в долгосрочные усилия по улучшению перевода в условиях ограниченных ресурсов посредством исследований неконтролируемых переводов и ускоренного обучения, а также сотрудничества с академическим сообществом. Мы продолжим работать с получателями грантов Facebook по NMT с низким уровнем ресурсов, чтобы продолжать продвигать современное состояние в этой области.
Как Facebook использует перевод для улучшения взаимодействия с пользователем
По состоянию на 2018 год у Facebook более 2 миллиардов пользователей по всему миру. С такой разнообразной глобальной аудиторией перевод стал неотъемлемой частью бизнес-модели Facebook. Вот 5 способов, которыми Facebook использует перевод, чтобы улучшить свои услуги и предложить пользователям новый и лучший опыт.
Перевод помогает facebook выйти на новые рынки
Если вы хотите, чтобы люди во всем мире пользовались вашим веб-сайтом, важно, чтобы они понимали слова на экране. В настоящее время Facebook доступен на 101 языке. Предлагая Facebook на стольких разных языках, компания смогла продолжить экспансию на новые рынки.
Предлагая Facebook на стольких разных языках, компания смогла продолжить экспансию на новые рынки.
Насколько хорошо окупилась эта стратегия? Вам судить — цифры не лгут:
- 22% всего населения мира зарегистрированы на Facebook.
- Примерно 85% людей, которые используют Facebook в любой день, находятся за пределами США и Канады.
- В США по-прежнему самая большая аудитория Facebook, но Индия быстро наверстывает упущенное, за ней следуют Бразилия и Индонезия.
перевод помогает компаниям лучше ориентировать свою рекламу на Facebook
Исследования постоянно показывают, что люди с большей вероятностью купят продукт, если информация о продукте доступна на их родном языке. Даже люди, хорошо владеющие английским как вторым языком, часто чувствуют себя более комфортно, когда говорят на своем родном языке.
Facebook позволяет рекламодателям создавать кампании на нескольких языках, поэтому пользователям показываются объявления на их родном языке. Существует также функция автоматического перевода с самообслуживанием, хотя мы рекомендуем, чтобы переводчик вычитывал вывод перед публикацией.
Существует также функция автоматического перевода с самообслуживанием, хотя мы рекомендуем, чтобы переводчик вычитывал вывод перед публикацией.
перевод помогает Facebook модерировать контент
Если вы читали новости, то знаете, что Facebook подвергся критике за то, что не делает больше для модерации контента, доступного на платформе. В дополнение к разногласиям на выборах в США их также призвали не делать больше, чтобы остановить распространение ложной информации в Мьянме, где слухи, распространяемые через Facebook, способствовали трагедии рохинджа.
Тем не менее, у них есть значительный объем контента для мониторинга на разных языках. Их процессы нуждаются в улучшении, но они улучшаются. Все это было бы невозможно без помощи как машинного перевода, так и лингвистов.
Команда модераторов контента Facebook состоит из 7500 человек, нанятых по всему миру за их языковые знания. Они также используют искусственный интеллект (ИИ) и машинный перевод (МП) для выявления сообщений, которые могут быть проблематичными.
Facebook использует машинный перевод, чтобы быстрее выпускать новые функции
С таким количеством пользователей по всему миру неудивительно, что Facebook вложил значительные средства в разработку улучшенного машинного перевода. В этом году MT на базе искусственного интеллекта Facebook начал использовать сверточные нейронные сети. Эти сети способны анализировать сразу целые предложения, а не по одному слову. Это приводит к более быстрому и точному машинному переводу, что повышает эффективность.
Согласно The Next Web, более эффективный перевод полезен не только по очевидной причине, но и потому, что он означает, что Facebook может выпускать функции быстрее, поскольку ему не нужно долго ждать перевода».
facebook использует машинный перевод в мессенджере, чтобы помочь пользователям общаться без общего языка
В этом году Facebook начал предлагать автоматически переводить сообщения на своей платформе Messenger.Новая функция особенно полезна для пользователей Facebook Marketplace.
