1) Как вставить пропущенный символ в тексте? 2) Как заменить неправильный символ в тексте? 3)…
1) Как вставить пропущенный символ в тексте?
А) Подвести указатель (курсор) «мыши» (он в поле текстового редактора меняет вид со стрелки на заглавную I) к тому месту, где нужно вставить символ, и кликнуть левой кнопкой мыши (ЛКМ).
Б) В тексте появится мигающая вертикальная черта, это текстовый курсор или место вставки.
В) Ввести с клавиатуры нужный символ.
2) Как заменить неправильный символ в тексте?
Вариант 1. Использовать одну из двух клавиш: Backspace или Delete. При этом следует хорошо запомнить: клавиша Delete удаляет символ, стоящий справа от текстового курсора (или после него), а клавиша Backspace удаляет символ, стоящий слева от текстового курсора (или перед ним). Решив, каким способом вам будет удобнее удалить неправильный символ, ставите текстовый курсор либо до, либо после этого символа и, соответственно, используете либо Delete, либо Backspace. После удаления неправильного символа вводите правильный.
После удаления неправильного символа вводите правильный.
Вариант 2. Использовать режим замены. Текстовый редактор MS Office Word по умолчанию работает в режиме вставки, то есть если текстовый курсор помещен в середину строки и вы начинаете вводить какой-то текст, символы справа от курсора никуда не исчезают, а сдвигаются вправо по строке. Но есть возможность переключиться на режим замены — нажатием клавиши Ins. В этом режиме символ, введенный в текущую позицию текстового курсора занимает место символа, стоящего справа от курсора, как бы «съедает» его. Если клавиша Ins не переключает режим ввода на режим замены и обратно, нужно выполнить Файл – Параметры – Дополнительно и поставить галочку в соответствующем пункте.
Вариант 3. Использовать встроенный словарь. Неправильный символ означает ошибочно написанное слово. Если кликнуть по этому слову правой кнопкой мыши (ПКМ), то в появившемся контекстом меню появятся варианты написания этого слова. Выбираете правильный вариант, выполняете по нему клик ЛКМ, и текстовый редактор заменит слово с ошибкой на правильное.
3) Как удалить лишний символ в тексте? Смотри в ответе на предыдущий вопрос Вариант 1.
4) Как разрезать абзац на два? Поставить текстовый курсор перед тем словом, с которого должен начинаться новый абзац, и нажать клавишу Enter
5) Как соединить два абзаца в один? Используя Delete или Backspace. Допустим, вы разделили один абзац на два, а затем передумали. Текстовый курсор находится после нажатия клавиши Enter перед первой буквой первого слова нового абзаца. Если вы нажмете Delete, удалите эту букву. Но если нажмете Backspace, вы удалите символ абзаца (его не видно на печати, но он есть!) и два абзаца вновь объединятся в один.
6) Как вставить пустую строку в текст? Текстовый редактор переносит символы на следующую строку автоматически. Нажимать Enter нужно только тогда, когда вы хотите создать новый абзац. Для перевода текстового курсора на новую строку без создания абзаца используется сочетание Shift + Enter.
7) Как удалить пустую строку? Для удаления пустой строки используются Delete или Backspace.
Строки в Python: методы и функции
Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
>>> stroka = 'Python'
>>> type(stroka)
<class 'str'>
>>> stroka2 = "code"
>>> type(stroka2)
<class 'str'>
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
stroka = ''
Или:
stroka2 = ""
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
>>> print("'Самоучитель Python' - возможно, лучший справочник по Питону.
SyntaxError: invalid syntax

Кроме двойных " и одинарных кавычек ', в Python используются и тройные ''' – в них заключают текст, состоящий из нескольких строк, или программный код:
>>> print('''В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.''')
В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
>>> stroka = 'python'
>>> print(len(stroka))
6
>>> stroka1 = ' '
>>> print(len(stroka1))
1
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
>>> number1 = 55 >>> number2 = 55.
 5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
>>> str1 = 'Python'
>>> str2 = ' - '
>>> str3 = 'самый гибкий язык программирования'
>>> print(str1 + str2 + str3)
Python - самый гибкий язык программирования
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
>>> stroka = '*** '
>>> print(stroka * 5)
*** *** *** *** ***
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор
Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in:
>>> stroka = 'abrakadabra'
>>> print('abra' in stroka)
True
>>> print('zebra' in stroka)
False
Индексация строк в Python
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
>>> stroka = 'программирование'
>>> print(stroka[7])
м
>>> print(stroka[-1])
е
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк.
>>> stroka = 'программирование'
>>> print(stroka[7:10])
мир
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
>>> stroka = 'программa'
>>> print(stroka[3:8])
грамм
Если не указать первый элемент диапазона [:b], срез будет выполнен с начала строки до позиции второго элемента b:
>>> stroka = 'программa'
>>> print(stroka[:4])
прог
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
>>> stroka = 'программa'
>>> print(stroka[3:])
граммa
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
>>> stroka = 'позиции не заданы'
>>> print(stroka[:])
позиции не заданы
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
>>> stroka = 'Python лучше всего подходит для новичков.'
>>> print(stroka[1:15:3])
yoлшв
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
>>> stroka = 'это пример отрицательного шага'
>>> print(stroka[-1:-15:-4])
а нт
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
>>> stroka = 'А роза упала на лапу Азора'
>>> print(stroka[::-1])
арозА упал ан алапу азор А
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
>>> stroka = 'mall'
>>> stroka[0] = 'b'
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией.
>>> stroka = 'mall'
>>> stroka = 'b' + stroka[1:]
>>> print(stroka)
ball
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
>>> spisok = ['Я', 'изучаю', 'Python']
>>> stroka = ' '.join(spisok)
>>> print(stroka)
Я изучаю Python
При объединении списка или кортежа в строку можно использовать любые разделители:
>>> kort = ('Я', 'изучаю', 'Django')
>>> stroka = '***'.join(kort)
>>> print(stroka)
Я***изучаю***Django
Метод split() используется для обратной манипуляции – преобразования строки в список:
>>> text = 'это пример текста для преобразования в список'
>>> spisok = text.split()
>>> print(spisok)
['это', 'пример', 'текста', 'для', 'преобразования', 'в', 'список']
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
>>> text = 'цвет: синий; вес: 1 кг; размер: 30х30х50; материал: картон' >>> spisok = text.
 split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
Метод partition() поможет преобразовать строку в кортеж:
>>> text = 'Python - простой и понятный язык'
>>> kort = text.partition('и')
>>> print(kort)
('Python - простой ', 'и', ' понятный язык')
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
>>> text = '12345'
>>> print(min(text))
1
>>> print(max(text))
5
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
>>> text = 'abracadabra123456'
>>> print(text.isalnum())
True
>>> text1 = 'a*b$ra cadabra'
>>> print(text1.isalnum())
False
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
>>> text = 'программирование'
>>> print(text.isalpha())
True
>>> text2 = 'password123'
>>> print(text2.isalpha())
False
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
>>> text = '1234567890'
>>> print(text.isdigit())
True
>>> text2 = '123456789o'
>>> print(text2.isdigit())
False
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
>>> text = '5.
 55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
>>> text = '½⅓¼⅕⅙'
>>> print(text.isdigit())
False
>>> print(text.isnumeric())
True
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
>>> text = 'abracadabra'
>>> print(text.islower())
True
>>> text2 = 'Python bytes'
>>> print(text2.islower())
False
>>> text3 = 'PYTHON'
>>> print(text3.isupper())
True
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
>>> stroka = ' ' >>> print(stroka.
 isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
>>> text = 'этот текст надо написать заглавными буквами'
>>> print(text.upper())
ЭТОТ ТЕКСТ НАДО НАПИСАТЬ ЗАГЛАВНЫМИ БУКВАМИ
>>> text = 'зДесь ВСе букВы рАзныЕ, а НУжнЫ проПИСНыЕ'
>>> print(text.lower())
здесь все буквы разные, а нужны прописные
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
>>> text = 'предложение должно начинаться с ЗАГЛАВНОЙ буквы.
 '
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
'
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
>>> text = 'пРИМЕР иСПОЛЬЗОВАНИЯ swapcase'
>>> print(text.swapcase())
Пример Использования SWAPCASE
>>> text2 = 'тот случай, когда нужен метод title'
>>> print(text2.title())
Тот Случай, Когда Нужен Метод Title
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
>>> text = 'пример текста, в котором нужно найти текстовую подстроку' >>> print(text.
 find('текст'))
7
>>> print(text.rfind('текст'))
37
find('текст'))
7
>>> print(text.rfind('текст'))
37
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
>>> text = 'Съешь еще этих мягких французских булок!'
>>> print(text.index('еще'))
6
>>> print(text.rindex('чаю'))
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
ValueError: substring not found
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
>>> text = 'Жила-была курочка Ряба'
>>> print(text.startswith('Жила'))
True
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
>>> text = 'В конце всех ждал хэппи-енд' >>> print(text.
 endswith('енд'))
True
endswith('енд'))
True
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
>>> text = 'Съешь еще этих мягких французских булок, да выпей же чаю!'
>>> print(text.count('е'))
5
>>> print(text.count('е', 5, 25))
2
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
>>> text = ' здесь есть пробелы и слева, и справа '
>>> print('***', text.strip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.lstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text. rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
 rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
>>> text = 'В этой строчке нужно заменить только одну "ч"'
>>> print(text.replace('ч', '', 1))
В этой строке нужно заменить только одну "ч"
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.

Решение:
text = input()
print(len(text))
print(text.isalpha())
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор ==.
Решение:
text = input().lower()
print(text == text[::-1])
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин.
Решение:
text = input() print(text.
 title())
title())
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Решение:
text = '12361573928167047230472012'
print(text.replace('1', 'один'))
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Пример ввода:
Алексей
Константинович
Романов
бухгалтер
Вывод:
А. К. Романов, бухгалтер
Решение:
first_name, patronymic, last_name, position = input(), input(), input(), input() print(first_name[0] + '.
 ', patronymic[0] + '.', last_name + ',', position)
', patronymic[0] + '.', last_name + ',', position)
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Пример ввода:
ЗонтИК
к
Вывод:
True
Решение:
text = input().lower()
letter = input()
print(letter in text)
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Решение:
vowels = 'аиеёоуыэюя' letter = input().
 lower()
print(letter in vowels)
lower()
print(letter in vowels)
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Пример ввода:
Шесть шустрых мышат в камышах шуршат
ша
Вывод:
16 33
Решение:
text, letter = input().lower(), input()
print(text.find(letter), text.rfind(letter))
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Пример ввода:
В роще, травы шевеля, мы нащиплем щавеля
Вывод:
Количество пробелов: 6, количество других символов: 34
Решение:
text = input() nospace = text.
 replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Пример ввода:
Программирование на Python - лучшее хобби
про
про
Вывод:
True
False
Решение:
text, start, end = input().lower(), input(), input()
print(text.startswith(start))
print(text.endswith(end))
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
В следующей статье будем разбирать методы работы со списками.
***
📖 Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
***
Материалы по теме
- ТОП-15 трюков в Python 3, делающих код понятнее и быстрее
на наличие пустых строк и отсутствующих значений — MATLAB & Simulink
Open Live Script
Массивы строк могут содержать как пустые строки, так и отсутствующие значения. Пустые строки содержат ноль символов и отображаются в виде двойных кавычек, между которыми ничего нет (
Пустые строки содержат ноль символов и отображаются в виде двойных кавычек, между которыми ничего нет ( "" ). Вы можете определить, является ли строка пустой строкой, используя оператор == . Пустая строка является подстрокой любой другой строки. Поэтому такие функции, как , содержат , всегда находят пустую строку внутри других строк. Строковые массивы также могут содержать пропущенные значения. Отсутствующие значения в строковых массивах отображаются как <отсутствует> . Чтобы найти пропущенные значения в массиве строк, используйте функцию ismissing вместо оператора == .
Тест на наличие пустых строк
Вы можете проверить массив строк на наличие пустых строк с помощью оператора == .
Вы можете создать пустую строку, используя двойные кавычки, между которыми ничего нет ( "" ). Обратите внимание, что размер str равен 1 на 1, а не 0 на 0. Однако
Однако str содержит ноль символов.
стр = ""
стр = ""
Создайте пустой вектор символов, используя одинарные кавычки. Обратите внимание, что размер chr равен 0 на 0. Массив символов chr на самом деле является пустым массивом, а не просто массивом с нулевыми символами.
символов = ''
символов = 0x0 пустой массив символов
Создайте массив пустых строк, используя функцию строк . Каждый элемент массива представляет собой строку без символов.
str2 = строки (1,3)
строка2 = строка 1x3
""""""
Проверить, является ли str пустой строкой, сравнив ее с пустой строкой.
если (стр == "")
disp 'str имеет ноль символов'
end str не содержит символов
Не используйте функцию isempty для проверки наличия пустых строк. Строка с нулевыми символами по-прежнему имеет размер 1 на 1. Однако вы можете проверить, имеет ли массив строк хотя бы одно измерение с нулевым размером, используя
Однако вы можете проверить, имеет ли массив строк хотя бы одно измерение с нулевым размером, используя пустая функция .
Создайте массив пустых строк, используя функцию строк . Чтобы массив был пустым, хотя бы одно измерение должно иметь нулевой размер.
строка = строки (0,3)
строка = 0x3 массив пустых строк
Проверка str с помощью функции isempty .
isempty(str)
ans = логическое 1
Проверить массив строк на наличие пустых строк. Оператор == возвращает логический массив того же размера, что и массив строк.
строка = ["Меркурий","","Аполлон"]
строка = 1x3 строка
"Меркурий" "" "Аполлон"
str == ''
ans = Логический массив 1x3 0 1 0
Поиск пустых строк в других строках
Строки всегда содержат пустую строку в качестве подстроки. На самом деле пустая строка всегда находится как в начале, так и в конце каждой строки. Кроме того, пустая строка всегда находится между любыми двумя последовательными символами в строке.
Кроме того, пустая строка всегда находится между любыми двумя последовательными символами в строке.
Создать строку. Затем проверьте, содержит ли он пустую строку.
str = "Привет, мир"; TF = содержит (str, "")
TF = логический 1
Проверить, начинается ли str с пустой строки.
TF = начинает с(str,"")
TF = логический 1
Подсчитать количество символов в str . Затем подсчитайте количество пустых строк в str . Функция count подсчитывает пустые строки в начале и в конце числа 9.0005 str и между каждой парой символов. Следовательно, если str содержит N символов, то он также содержит N+1 пустых строк.
стр = "Привет, мир"
strlength(str)
анс = 12
количество(строка,"")
число = 13
Заменить подстроку пустой строкой. Когда вы вызываете
Когда вы вызываете , замените пустой строкой, она удалит подстроку и заменит ее строкой, содержащей ноль символов.
заменить(ул,"мир","")
анс = "Привет, "
Вставка подстроки после пустых строк с помощью функции insertAfter . Поскольку между каждой парой символов есть пустые строки, insertAfter вставляет подстроки между каждой парой.
вставить после (стр, "","-")
анс = "-Привет, мир-"
Как правило, строковые функции, которые заменяют, стирают, извлекают или вставляют подстроки, позволяют указывать пустые строки в качестве начала и конца изменяемых подстрок. При этом эти функции работают с началом и концом строки, а также между каждой парой символов.
Проверка пропущенных значений
Вы можете проверить массив строк на пропущенные значения, используя функцию ismissing . Отсутствующая строка — это строка, эквивалентная NaN для числовых массивов. Он указывает, где в массиве строк есть пропущенные значения. Отсутствующая строка отображается как
Он указывает, где в массиве строк есть пропущенные значения. Отсутствующая строка отображается как <отсутствует> .
Чтобы создать отсутствующую строку, преобразуйте отсутствующее значение с помощью функции строка .
строка = строка (отсутствует)
строка = <отсутствует>
Вы можете создать массив строк как с пустыми, так и с отсутствующими строками. Используйте функцию ismissing , чтобы определить, какие элементы являются строками с пропущенными значениями. Обратите внимание, что пустая строка не является отсутствующей строкой.
стр(1) = ""; ул(2) = "Близнецы"; str(3) = строка (отсутствует)
str = строка 1x3
"""Близнецы" <пропал без вести>
ismissing(str)
ans = Логический массив 1x3 0 0 1
Сравнить str на отсутствующую строку. Сравнение всегда 0 ( false ), даже когда вы сравниваете отсутствующую строку с другой отсутствующей строкой.
str == строка (отсутствует)
ans = Логический массив 1x3 0 0 0
Чтобы найти отсутствующие строки, используйте функцию ismissing . Не используйте оператор == .
См. также
строка | строк | длина строки | отсутствует | содержит | начинается с | заканчивается | стереть | экстрактМежду | Экстракт До | экстрактПосле | вставка после | вставкаДо | заменить | заменитьМежду | стеретьМежду | экв. | все | любой
См. также
- Создание массивов строк
- Анализ текстовых данных с помощью массивов строк
- Поиск и замена текста
- Сравнение текста
Пустая строка считается вредной способ поддержать это приведет к ошибкам и сложному сопровождению кода.
 Следует избегать пустых строк, за очень немногими исключениями.
Следует избегать пустых строк, за очень немногими исключениями.Несколько раз за свою карьеру я демонстрировал коллегам проблему использования пустых строк, поэтому я подумал, что пришло время написать об этом всем вам, чтобы, надеюсь, поучиться.
Возьмем простой пример. Я собираюсь использовать TypeScript для этой статьи, но это , а не машинописная статья : она применима к любому языку, который имеет систему типов, и эта система типов может выражать, что значение имеет тип «строка» или «неопределенное»/ «null»/»nil»/»необязательный»/»может быть» и т.д.
Итак, давайте рассмотрим метод, возвращающий имя, которое поддерживает человека с псевдонимом. Вспомните Дуэйна «СКАЛУ» Джонсона .
функция printName1 (имя: строка, фамилия: строка, псевдоним: строка) { return `${firstName} "${nickName.toUpperCase()}" ${lastName}`; }
Для простого вызова это работает нормально. Я могу назвать это так:
printName1('Дуэйн', 'Джонсон', 'Скала') И я получаю ожидаемый результат: Дуэйн «СКАЛ» Джонсон.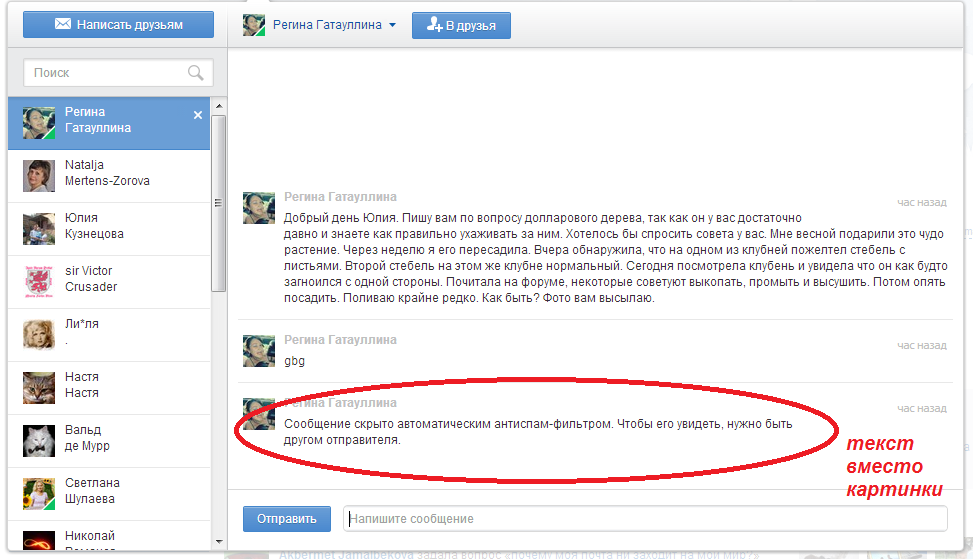
Теперь я хочу изменить код, чтобы он не поддерживал псевдонимы. Не у всех есть прозвища, так что справедливо.
Моей первой мыслью было бы не посылать отчество.
printName1('Дуэйн', 'Джонсон') Но затем срабатывает компилятор, и моя IDE сообщает мне, что я вызываю с двумя аргументами вместо ожидаемых трех. Справедливо. Но я тороплюсь, и мне просто нужно сделать это. Так что я могу просто обойти это.
printName1('Дуэйн', 'Джонсон', '') Я не стал проверять, потому что знаю, что пустая строка ничего не покажет. Я запускаю его в производство, а затем мои пользователи начинают жаловаться.
Внезапно мы видим First «» Last в пользовательском интерфейсе — да?
О-о-о. Мы не проверяли пустую строку. Хм. Тогда ладно. Что ж, в этой редкой и привилегированной ситуации я являюсь и автором, и потребителем кода. Я бы хотел, чтобы компилятор сказал мне, как с этим справиться, но, увы, это не так, но я умный и могу это исправить.
function printName2(firstName: string, lastName: string, nickName: string) { if (nickName.length > 0) { return `${firstName} "${nickName.toUpperCase()}" ${lastName }`; }
return `${firstName} ${lastName}`; }
Хорошо, теперь работает. Я воспользовался тем фактом, что мне повезло контролировать как реализацию функции, так и вызывающую сторону кода.
А если нет? Большую часть времени вы не.
Мы можем сделать лучше , и полагаемся на компилятор нашего языка .
Допустим, вместо этого мы решили точно выразить функцию с помощью более точных типов.
function printName3(firstName: string, lastName: string, nickName?: string) { return `${firstName} "${nickName.toUpperCase()}" ${lastName}`; }
Теперь мы можем называть это двумя способами:
printName3('Дуэйн', 'Джонсон', 'Скала') printName3('Дуэйн', 'Джонсон') И компилятор не жаловаться, как это было в первый раз. Никаких обходных путей, никаких хаков. Гораздо проще для вызывающей функции.
Никаких обходных путей, никаких хаков. Гораздо проще для вызывающей функции.
И нам, как автору функции, тоже легче. Мы можем сообщить, без дополнительной документации или какого-либо сообщения вызывающим абонентам (которыми можете быть вы, будущие вы, коллега или человек на другом конце мира ..), что этот метод делает и ожидает.
А во-вторых, пока мы это пишем, на вечеринку приходит компилятор и предупреждает нас, что мы не обработали возможность отсутствующего никнейма.
Потрясающе. Мы можем это исправить.
function printName3(firstName: string, lastName: string, nickName?: string) { if (nickName) { return `${firstName} "${nickName.toUpperCase()}" ${lastName}`; }
return `${firstName} ${lastName}`; }
В более широком смысле, системы типов невероятно мощны и могут проверить для вас множество потенциальных логических ошибок. Однако он может помочь вам ровно настолько, насколько вы ему поможете. Правильно сообщая компилятору через язык, что эта строка может быть необязательной, мы получаем, что компилятор помогает нам на всем протяжении нашего кода. Изобретая собственный индикатор для необязательных строк — пустую строку — мы не получаем такой помощи, и ошибки находят свой путь очень быстро, даже с такими средствами защиты, как документация.
Правильно сообщая компилятору через язык, что эта строка может быть необязательной, мы получаем, что компилятор помогает нам на всем протяжении нашего кода. Изобретая собственный индикатор для необязательных строк — пустую строку — мы не получаем такой помощи, и ошибки находят свой путь очень быстро, даже с такими средствами защиты, как документация.
Итак, вот почему я считаю пустую строку [вредной](https://en.wikipedia.org/wiki/Considered_harmful) в языках, которые имеют эти функции. Это указывает на непонимание языка и его способности помочь вам, неправильный перевод требований в код и возможность будущих ошибок.
Однако из этого правила есть несколько исключений. Как правило, это должно происходить только в «точке входа» и «точке выхода» вашей кодовой базы. Например, если вы имеете дело с API, базой данных или визуальным интерфейсом, который имеет эти контракты и может означать что-то семантически отличающееся, то можно на последнем возможном шаге преобразовать значение, которое не определено, в пустую строку.
