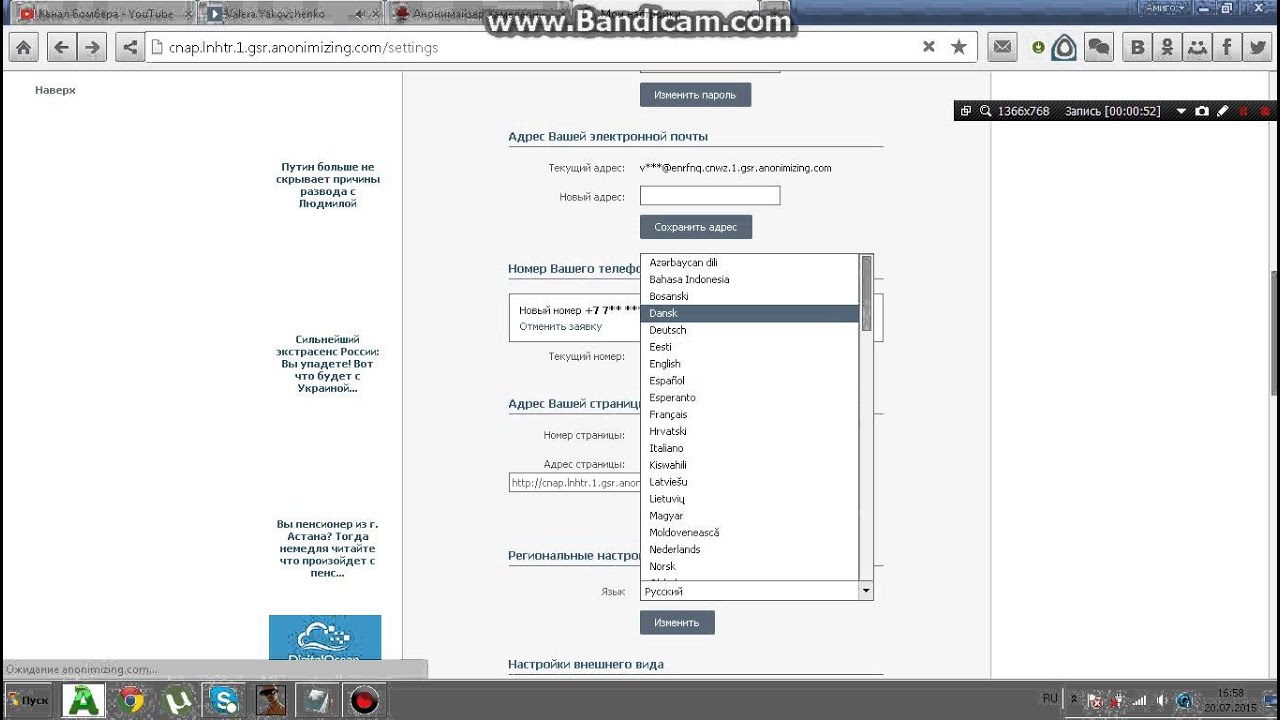
ВГИК
Всероссийский государственный институт кинематографии имени С.А. Герасимова (ВГИК) является федеральным государственным образовательным учреждением высшего образования Российской Федерации.
ВГИК находится в ведении Министерства культуры Российской Федерации.
Учредителем и собственником имущества Института является Российская Федерация.
Официальное наименование Института на русском языке: полное – Федеральное государственное бюджетное образовательное учреждение высшего образования «Всероссийский государственный институт кинематографии имени С.А. Герасимова»; сокращенное – Всероссийский государственный институт кинематографии имени С.А. Герасимова; аббревиатура: ВГИК.
Официальное наименование Института на английском языке – Russian State University of Cinematography named after S.Gerasimov; аббревиатура – VGIK.
ВГИК основан 1 сентября 1919 года как Государственная школа кинематографии.
ВГИК готовит специалистов в области «Культура и искусство» по программам высшего, среднего профессионального и дополнительного образования. Обучение ведется по очной (на всех факультетах) и заочной (на сценарно-киноведческом факультете и факультете продюсерства и экономики) формам.
Обучение ведется по очной (на всех факультетах) и заочной (на сценарно-киноведческом факультете и факультете продюсерства и экономики) формам.
Преподаватели ВГИК являются лауреатами государственных премий: «Ника», «ТЭФИ», «Золотой витязь», «Золотой орел», «Феликс».
Среди преподавателей – выпускников ВГИК обладатели «Золотой пальмовой ветви» Каннского кинофестиваля, «Оскара» Американской киноакадемии, «Золотого льва» Венецианского кинофестиваля, наград Московского международного кинофестиваля и других международных и национальных премий.
Федеральное государственное бюджетное образовательное учреждение высшего образования «Всероссийский государственный институт кинематографии имени С.А. Герасимова» имеет филиалы:
Иркутский филиал федерального государственного бюджетного образовательного учреждения высшего образования «Всероссийский государственный институт кинематографии имени С.
 А. Герасимова»;
А. Герасимова»;Ростовский-на-Дону филиал федерального государственного бюджетного образовательного учреждения высшего образования «Всероссийский государственный институт кинематографии имени С.А. Герасимова»;
Сергиево-Посадский филиал федерального государственного бюджетного образовательного учреждения высшего образования «Всероссийский государственный институт кинематографии имени С.А. Герасимова».
 А. Герасимова»;
А. Герасимова»;Важную роль в деятельности ВГИКа как научно-образовательного центра играет Научно-исследовательский институт киноискусства (НИИК), который в сотрудничестве с кафедрами института проводит исследования в области истории и теории кино и других актуальных проблем развития киноиндустрии.
ВГИК — первая в мире киношкола — исторически и традиционно является интернациональным вузом. За годы его существования подготовлены специалисты для республик бывшего СССР, стран СНГ и для 75 стран дальнего зарубежья.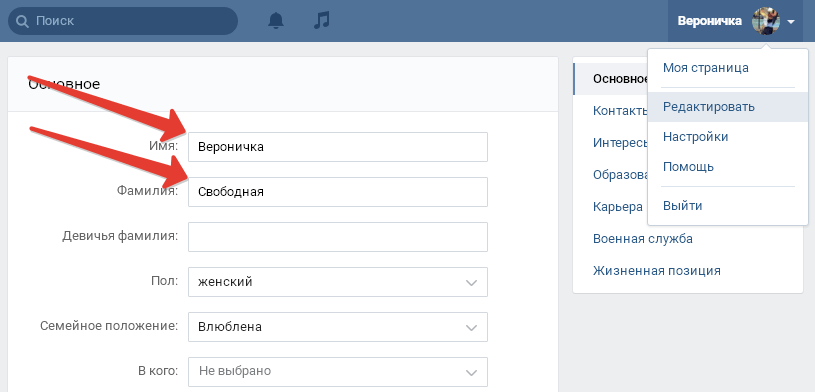
ВГИК — единственная в России государственная киношкола, обладающая киностудией с полным технологическим циклом для производства кино- и видеофильмов.
ВГИК является ответственной организацией федеральных учебно-методических объединений (ФУМО) в системе среднего профессионального и высшего образования по укрупненным группам специальностей и направлений подготовки 55.00.00 Экранные искусства. Председателем ФУМО в сфере высшего образования и среднего профессионального образования по УГСН 55.00.00 Экранные искусства является Николаева-Чинарова Алевтина Петровна.
Указом Президента РФ от 15 апреля 2013 г. № 360 ВГИК отнесен к особо ценным объектам культурного наследия народов Российской Федерации.
История института
Роль ВГИКа в развитии экранного искусства невозможно переоценить. Другого подобного вуза в практике мирового кино и кинообразования не существует.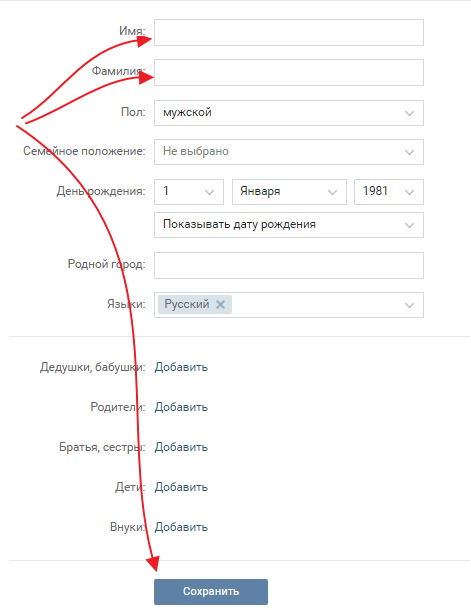 Он появился на заре кинематографа, когда кино еще никто не считал искусством.
Он появился на заре кинематографа, когда кино еще никто не считал искусством.
Стремительный взлет советского кино 20-х годов, который привел к созданию непревзойденных шедевров мирового киноискусства, начался с открытия 1 сентября 1919 г. первой в мире «Государственной киношколы». Ей суждено было стать не только местом, где получили образование многие поколения корифеев советского кино, но и лабораторией, где создавалась теория первого массового искусства ХХ века, а ее принципиальные положения впервые проверялись на практике. Именно во ВГИКе был снят первый советский полнометражный художественный фильм «Серп и молот». Здесь под руководством выдающегося теоретика и практика монтажа Льва Кулешова, воспитавшего другого титана 20-х годов – Всеволода Пудовкина, возникла советская школа киноактера. Здесь же в начале 30-х годов Сергей Эйзенштейн, возглавивший экспериментальную мастерскую, где учились создатели «Чапаева» братья Васильевы, разработал первые в мире учебный курс и программу по кинорежиссуре.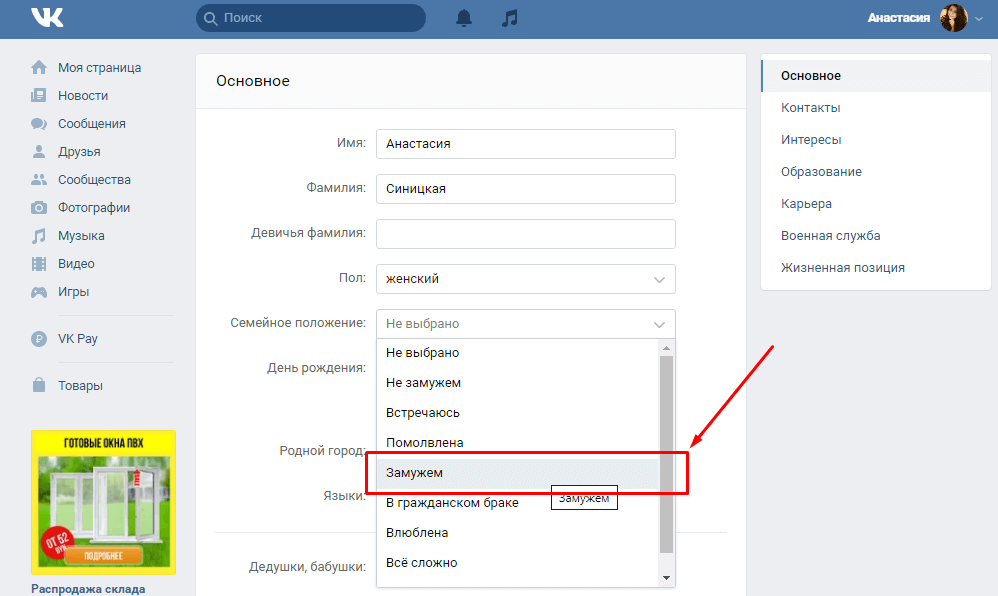
В 1931 году во ВГИКе была организована фильмотека, выросшая впоследствии в Госфильмофонд России – ныне особо ценный объект культурного наследия народов Российской Федерации. Основатель французской национальной синематеки Анри Ланглуа писал: «Первая в мире фильмотека художественных фильмов создана в Москве при школе киноискусства… Большинство собрания Московской фильмотеки имеет уникальное значение…». В 1937 году организация фильмотеки была отмечена «Гран при» Международной выставки в Париже. В 1934 году во ВГИКе открылся первый в нашей стране научно-исследовательский сектор, объединивший крупнейших теоретиков, историков и практиков – Н. Лебедева, В. Вишневского, С. Гинзбурга, Г. Авенариуса, Л. Кулешова, С. Эйзенштейна, В. Пудовкина, А. Довженко, В. Туркина и многих других, чьими усилиями создано отечественное киноведение, написаны основополагающие труды по истории и теории экранного искусства.
Уникальная роль отечественной киношколы состояла не только в том, что она опередила время (лишь в 1935 году в Италии был создан Римский экспериментальный киноцентр, и только в 1939 году во Франции организована Высшая школа кинематографии – ИДЕК), но и в том, что, впервые занявшись подготовкой творческих работников кинематографа, она противопоставила узкоремесленническому подходу в кинообразовании концепцию воспитания творческой личности, художника-творца и патриота.
Вся последующая история отечественного кино свидетельствует о плодотворности такого подхода. Подтверждением этому служит выдающийся вклад многих поколений вгиковцев в отечественную кинокультуру. В их числе фронтовые кинооператоры, создавшие трагически-величественную хронику борьбы народа с фашизмом, и те, кто в последующий период не только определял художественные направления и тенденции развития киноискусства, но и в значительной степени мироощущение нации, духовный и нравственный климат в обществе. Фильмы Г.Чухрая, М.Хуциева, Т.Абуладзе, Р.Чхеидзе, С.Ростоцкого, Л.Кулиджанова, Э.Рязанова, А.Тарковского, В.Шукшина, А.Кончаловского, О.Иоселиани, С. Параджанова, Э.Климова, К.Муратовой, Н.Михалкова, В.Абдрашитова, А.Сокурова, С.Соловьева, А.Петрова и многих других выпускников ВГИК стали не только выдающимися явлениями отечественной культуры, но и утвердили высокий международный авторитет киноискусства нашей страны во всем мире.
Профессионализм вгиковцев, их владение средствами экранной выразительности были и остаются востребованы телевидением. Они – создатели многочисленных телевизионных фильмов и сериалов, познавательных и образовательных программ и передач. Выпускниками ВГИК – Т.Лиозновой, С.Говорухиным, Е.Ташковым, В.Краснопольским и В.Усковым заложена успешно ныне развивающаяся традиция создания отечественного телевизионного сериала.
Они – создатели многочисленных телевизионных фильмов и сериалов, познавательных и образовательных программ и передач. Выпускниками ВГИК – Т.Лиозновой, С.Говорухиным, Е.Ташковым, В.Краснопольским и В.Усковым заложена успешно ныне развивающаяся традиция создания отечественного телевизионного сериала.
 При активном участии ВГИК созданы киновузы Болгарии, Вьетнама, Египта, Китая, Чехии, Польши и других стран. Вгиковские образовательные программы и методики успешно используются сегодня в США, Мексике, Англии, Германии, Польше, Чехии, Индии, Вьетнаме, Китае и других странах.
При активном участии ВГИК созданы киновузы Болгарии, Вьетнама, Египта, Китая, Чехии, Польши и других стран. Вгиковские образовательные программы и методики успешно используются сегодня в США, Мексике, Англии, Германии, Польше, Чехии, Индии, Вьетнаме, Китае и других странах.С момента своего основания ВГИК был и остается носителем культурной традиции, духовно-нравственных ценностей и созидательного духа нашего народа. И сегодня вгиковцы разных поколений, определяют поступательное движение отечественного кинопроцесса. В их числе: Кира Муратова, Никита Михалков, Александр Сокуров, Вадим Абдрашитов, Сергей Соловьев, Александр Рогожкин, Алексей Учитель, Сергей Сельянов, Сергей Мирошниченко, Александр Петров, а вместе с ними выпускники нового поколения: Дмитрий Месхиев, Геннадий Сидоров, Федор Бондарчук, Алексей Федорченко, Лариса Садилова, Филипп Янковский, Анна Меликян, Алексей Герман-младший и многие, многие другие.
Оставаясь верным традициям, ВГИК, признанный всемирной моделью кинообразования, устремлен в будущее.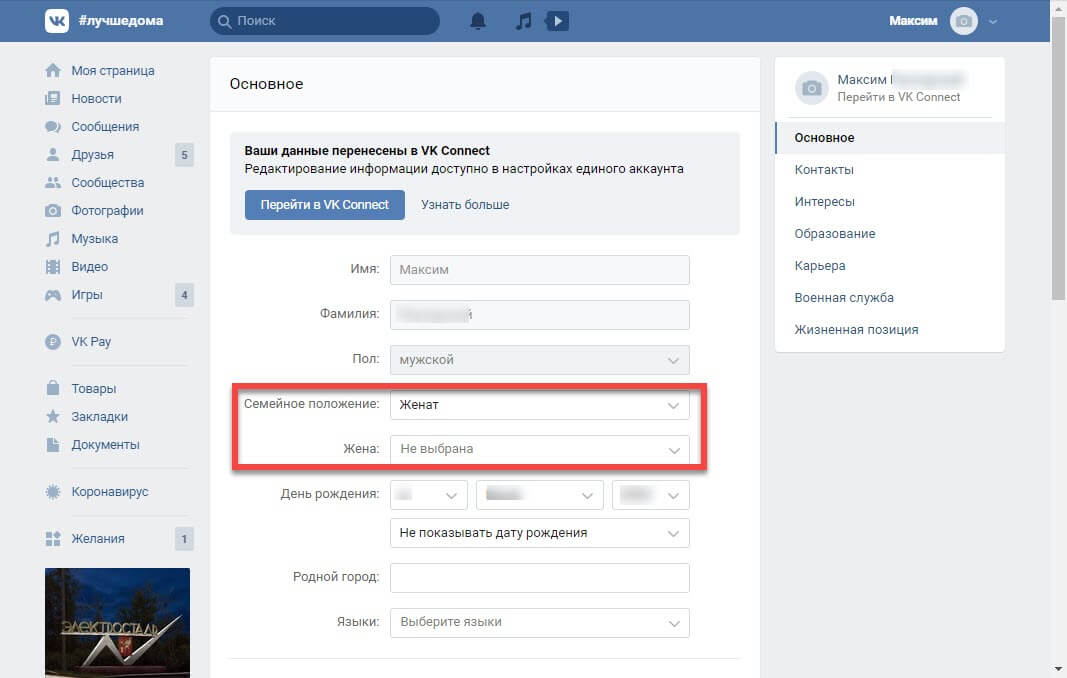 Осуществляется модернизация образования, научной и творческой деятельности, внедряются инновационные технологии, методики обучения. Расширяющееся международное сотрудничество, многочисленные совместные проекты с зарубежными вузами кино и телевидения определяют последовательное движение российской киношколы к интеграции в мировой культурный и образовательный процесс.
Осуществляется модернизация образования, научной и творческой деятельности, внедряются инновационные технологии, методики обучения. Расширяющееся международное сотрудничество, многочисленные совместные проекты с зарубежными вузами кино и телевидения определяют последовательное движение российской киношколы к интеграции в мировой культурный и образовательный процесс.
Согласные в английском языке. P, b, k, f, v, m, z, h, t, d, l, n
Уникальный онлайн курс английского языка IQEnglish от Марины Озеровой
Бесплатный вебинар! Подробнее о курсе…
Практически все звуки английского языка отличаются от звуков русского языка. И даже на первый взгляд похожие звуки могут артикулироваться по-разному. Артикуляция в данном случае – это положение органов речи (языка и губ в первую очередь) во время произнесения звука. Однако, целых 12 согласных английских звуков может с легкостью произнести русскоязычный человек. Это звуки [p, b, k, f, v, m, z, h, t, d, l, n].
Фонетика – это такая область английского языка, для изучения которой лучше всего подходят аудио и видео материалы. Можно бесконечно читать про звуки, и так и не научится их правильно произносить.
Обязательно посмотрите видеоурок. В нем Вас ждут упражнение для отработки Вашего произношения!
Данный видео урок входит в программу онлайн курса RealStudy на уровне для начинающих Starter.
Хочу попробовать курс бесплатно
Звуки [p, b, k, f, v, m, z]
Произносить английские звуки p, b, k, f, v, m, z – можно также как их аналоги в русском:
p = п,
b = б | book [buk] — книга,
k = к | kite [kaɪt] — воздушный змей,
f = ф | fan [fæn] — веер,
v = в | van [væn] — фургон,
m = м | mole[məul] — крот,
z = з | zoo [zuː] — зоопарк
Особенности произнесения
1. Z нужно произносить с меньшим акцентом, чем мы делаем это в русском. В целом, англичане произносят глухие звуки мощнее, чем звонкие.
Z нужно произносить с меньшим акцентом, чем мы делаем это в русском. В целом, англичане произносят глухие звуки мощнее, чем звонкие.
2. При произнесении v, я очень рекомендую немного прикусывать верхними зубами нижнюю губу. Это помогает не оглушать данный звук во всех позициях. Не забывайте, что в отличие от русского языка, в английском звонкие согласные никогда не оглушаются. Поэтому, например, move всегда будет [muːv ~ мув], и никогда [муф].
3. Звуки [p], [t] и [k] в начале ударного слога произносятся с придыханием или аспирацией. После каждого из этих звуков мы немного выдыхаем (но так, чтобы это было слышно), а затем уже произносим следующих звук. Нужно запомнить, что если [p], [t] и [k] стоят после [s], например, sport, skate, то придыхания не будет. Свистящий звук [s] как бы крадёт придыхание у следующих за ним [p], [t] и [k].
Звук [h]
Звук h – это простой выдох без голоса. Легче всего его тренировать на словах, которые с этого звука начинаются.
Hi! [haɪ]
Hello! [‘he’ləu]
happy [‘hæpɪ]
holiday [‘hɔlədeɪ]
Звуки [t, d, l, n]
Звуки t, d, l, n (т, д, л, н) – произносятся на альвеолах (бугорок за зубами), а не на зубах. Подробнее об этом смотрите в видео, размещённой в данной статье.
Твёрдость, мягкость. Это важно
И последнее замечание, не забывайте, что английские согласные звуки не смягчаются. Сравните, в русском: [бал]- [бил] – в первом слове [б] – твердый, а во втором — [б] – мягкий. В английском же [bæt]- [bɪt] – в обоих случая согласный звук [b] будет твёрдым. Попробуйте произнести. Не получается? Можно попробовать сделать так. Согласную перед [ɪ / e] произнести с небольшой паузой, чтобы согласный звук уже отзвучал твёрдо, а потом уже звучал гласный звук. Постепенно это паузу нужно сводить на нет. В идеале, конечно, никаких пауз между звуками быть не должно.
О КУРСЕ REALSTUDY: Курс содержит 5 уровней языка от самого начального (Starter) до Intermediate. Вас ждут более 200 полезных видеоуроков, обучающих всем тонкостям языка; более 300 диалогов для разговорной практики; специальные уроки, улучшающие произношение; более 900 полезных заданий для отработки; самые необходимые разговорные темы, мониторинг прогресса и многое другое.
Вас ждут более 200 полезных видеоуроков, обучающих всем тонкостям языка; более 300 диалогов для разговорной практики; специальные уроки, улучшающие произношение; более 900 полезных заданий для отработки; самые необходимые разговорные темы, мониторинг прогресса и многое другое.
Начать заниматься бесплатно
Похожие статьи
Также советуем почитать
Читать, а не слушать: как работает распознавание речи во «ВКонтакте» | by VK Team
Когда дело доходит до сообщений, читать их быстрее, чем слушать. Также легче просматривать текст, чтобы найти и проверить детали. Однако иногда бывают ситуации, когда гораздо удобнее просто отправить голосовое сообщение, чем набирать все подряд.
Меня зовут Надя Зуева. В этой статье я расскажу, как мы в ВКонтакте смогли помочь помирить любителей и ненавистников голосовых сообщений с помощью автоматического распознавания речи. Я поделюсь с вами тем, как мы пришли к нашему решению, какие модели мы используем, на каких данных мы их обучали и как мы оптимизировали его для быстрой работы в продакшене.
Мы начали проводить исследования по распознаванию речи в голосовых сообщениях в 2018 году. Тогда мы думали, что это может стать крутой функцией продукта и настоящим вызовом для нашей исследовательской группы. Голосовые сообщения записываются в условиях, далеких от идеальных, люди говорят на сленге и не особо заботятся о правильной дикции. И в то же время распознавание речи должно быть быстрым. Тратить 10 минут на расшифровку 10-секундного голосового сообщения — не вариант.
В начале все наши эксперименты мы проводили с использованием английской речи, так как на английском много хороших наборов данных, и научились их распознавать. Однако большая часть аудитории ВКонтакте говорит по-русски, и в открытом доступе не было русских наборов данных, которые мы могли бы использовать для обучения наших моделей. Сейчас с русскими наборами данных ситуация получше: есть «Голос» от Сбера, Common Voice от Mozilla и ряд других. Но до этого это была отдельная задача, которую нам нужно было решить, создав собственный набор данных.
Первая версия нашей модели была основана на wav2letter++ от Facebook AI Research и была готова к экспериментам в продакшене в 2019 году. Мы запустили ее в тихом режиме как функцию поиска голосовых сообщений. Благодаря этому мы смогли убедиться, что распознавание речи может быть полезно для преобразования голосовых сообщений в текст, и начали вкладывать больше ресурсов в создание этой технологии.
В начале 2020 года нашей задачей было нечто большее, чем просто создание точной модели. Нам нужно было увеличить производительность для нашей многомиллионной аудитории. Дополнительным вызовом для нас стал сленг. У нас не было другого выбора, кроме как выяснить, как его разобрать.
Теперь конвейер распознавания речи состоит из трех моделей. Первая — акустическая модель, отвечающая за распознавание звуков. Вторая — это языковая модель, которая формирует слова из звуков. И третья — это модель Punctuation, которая добавляет в текст знаки препинания. Мы рассмотрим каждую из этих моделей, но сначала давайте подготовим входные данные.
Для задач ASR первое, что вам нужно сделать, это преобразовать звук в формат, с которым может работать нейросеть. Сам по себе звук сохраняется в памяти компьютера в виде массива значений, показывающих колебания амплитуды во времени. Обычно частота дискретизации исчисляется десятками тысяч точек в секунду (или кГц), а получившийся трек получается очень длинным и сложным для работы. Поэтому перед прогоном через нейросеть звуки предварительно обрабатываются. Они преобразуются в спектрограмму, которая показывает интенсивность звуковых колебаний на различных частотах с течением времени.
Подход с использованием спектрограммы считается консервативным. Есть и другие варианты, такие как wav2vec (который похож на word2vec в НЛП, но для звука). Несмотря на то, что современные модели ASR в настоящее время используют wav2vec, этот подход не обеспечил улучшения качества для нашей архитектуры.
После преобразования необработанного сигнала в удобный формат для использования с нейронными сетями мы готовы распознавать речь, получая вероятностное распределение фонем во времени по звуку.
Большинство подходов сначала создают фонетические транскрипции (по сути, «что слышно, то и написано»), а затем отдельная языковая модель «прочесывает» результат, исправляя грамматические и орфографические ошибки и удаляя лишние буквы.
Марковские модели использовались в качестве простых акустических моделей для распознавания речи (например, в элайнерах). Теперь нейронные сети заменили эти модели для полного распознавания речи, но марковские модели по-прежнему используются, например, для разбиения длинных аудиосигналов на более мелкие фрагменты.
В 2019 году, когда мы активно работали над этим проектом, уже существовало значительное количество архитектур распознавания речи, таких как DeepSpeech3 (SOTA 2018 на основе набора данных LibriSpeech). Он состоит из комбинации двух типов слоев — рекуррентного и сверточного. Повторяющиеся слои позволяют генерировать продолжения фраз с особым вниманием к ранее сгенерированным словам. А сверточные слои отвечают за извлечение признаков из спектрограмм. В статье об этой архитектуре авторы использовали для обучения CTC-loss. Это позволяет модели распознавать такие слова, как «Privye-e-e-et» и «Privyet» (по-английски «Hello-o-o-o» и «Hello») как одно и то же, не спотыкаясь о длину звука. Собственно, эта функция потерь используется и при распознавании рукописных текстов.
В статье об этой архитектуре авторы использовали для обучения CTC-loss. Это позволяет модели распознавать такие слова, как «Privye-e-e-et» и «Privyet» (по-английски «Hello-o-o-o» и «Hello») как одно и то же, не спотыкаясь о длину звука. Собственно, эта функция потерь используется и при распознавании рукописных текстов.
Чуть позже был выпущен wav2letter++ от FAIR. Что делало его уникальным, так это то, что он использовал только сверточные слои без авторегрессии (при авторегрессии мы смотрим на ранее сгенерированные слова и последовательно просматриваем их, что замедляет работу нейронной сети). Создатели wav2letter++ сосредоточились на скорости, поэтому он был создан с использованием C++. Мы начали с этой архитектуры при разработке нашего поиска голосовых сообщений.
Использование полностью сверточных подходов открыло новые возможности для исследователей. Вскоре после этого появилась архитектура Jasper, которая также была полностью сверточной, но использовала идею остаточных соединений, как ResNet или трансформаторы. Затем появился QuartzNet от NVIDIA, основанный на Jasper. Это тот, который мы использовали.
Затем появился QuartzNet от NVIDIA, основанный на Jasper. Это тот, который мы использовали.
Прямо сейчас есть Conformer, который является SOTA-решением на момент написания этой статьи.
Таким образом, независимо от того, какую архитектуру мы выбрали, нейронная сеть получает на вход спектрограмму и выводит матрицу распределения вероятностей каждой фонемы во времени. Эта таблица также называется эмиссионным набором.
Используя жадный декодер, мы уже могли получить ответ из данных эмиссионного набора, выбрав наиболее вероятный звук для каждого момента времени.
Но этот подход мало что знает о правильном написании и, скорее всего, даст ответы с большим количеством ошибок. Чтобы исправить это, мы используем декодирование поиска луча с использованием взвешивания гипотез с использованием языковой модели.
После того, как мы получили набор эмиссий, нам нужно сгенерировать текст. Декодирование выполняется не только с использованием вероятностей, которые дает нам наша акустическая модель. Он также принимает во внимание «мнение» языковой модели. Это может сообщить нам, насколько вероятно встретить такое сочетание символов или слов в языке.
Он также принимает во внимание «мнение» языковой модели. Это может сообщить нам, насколько вероятно встретить такое сочетание символов или слов в языке.
Для декодирования используем алгоритм поиска луча. Идея заключается в том, что мы не только выбираем наиболее вероятный звук для данного момента, но и вычисляем вероятность всей цепочки с учетом предыдущих слов и сохраняем лучших кандидатов на каждом шаге. В результате выбираем наиболее вероятный вариант.
d2l.ai/chapter_recurrent-modern/beam-search.htmlПри отборе кандидатов мы присваиваем каждому вероятность, принимая во внимание ответы акустической и языковой моделей. Вы можете увидеть формулу на картинке ниже.
Хорошо, мы рассмотрели расшифровку поиска луча. Теперь нам нужно посмотреть, на что способна языковая модель.
В качестве языковой модели мы использовали n-граммы. С точки зрения архитектуры этот подход работает достаточно хорошо, пока мы говорим о серверных (а не мобильных) решениях. Ниже вы можете увидеть пример для n=2.
Что здесь гораздо интереснее, так это то, как мы предварительно обрабатываем данные для обучения.
При письме туда и обратно люди часто используют сокращения, цифры и другие символы. Наша акустическая модель знает только буквы, поэтому в наших обучающих данных нам нужно различать ситуации, когда «1» означает «первый», а когда означает «один» или «один». Трудно найти много текстов с непринужденной речью, где люди пишут «отдайте мне 386 рублей до 20 декабря» вместо «отдайте 386 рублей до 20 декабря». Поэтому мы обучили дополнительную модель нормализации.
В качестве архитектуры мы выбрали трансформатор, который часто используется для машинного перевода. Наша задача по-своему похожа на МТ. Нам нужно перевести денормализованный язык в нормализованный язык, в котором используются только символы алфавита.
Языковая модель дает нам последовательность слов, которые есть в языке и «идут вместе» друг с другом. Его намного легче читать и понимать, чем вывод акустической модели. Но для длинных сообщений результат все равно не очень хорош, потому что может быть некоторая двусмысленность.
Но для длинных сообщений результат все равно не очень хорош, потому что может быть некоторая двусмысленность.
После того, как мы получим читаемую строку слов, мы можем добавить знаки препинания. Это особенно полезно, когда текст длинный. Предложения, разделенные точками, читать намного легче, а в русском языке активно используются другие виды пунктуации, например, запятые. Даже в коротких предложениях они должны быть.
Архитектура, на которой основана наша модель пунктуации, представляет собой кодировщик из преобразователя и линейный слой. Он выполняет умную классификацию, предсказывая, нужна ли точка, запятая, тире или двоеточие после каждого слова или нет.
Подход к созданию обучающих данных здесь аналогичен. Мы берем тексты со знаками препинания в них и искусственно «портим» эти данные, убирая знаки препинания. Затем обучаем модель, чтобы вставить их обратно.
Как я упоминал в начале статьи, когда мы начинали наше исследование, в открытых источниках русскоязычных данных для обучения систем распознавания речи не было. Какое-то время мы экспериментировали с английским языком. Затем мы пришли к пониманию, что в любом случае нам нужны записи как можно более непринужденной речи, а не профессионально прочитанные аудиокниги, как в LibriSpeech.
Какое-то время мы экспериментировали с английским языком. Затем мы пришли к пониманию, что в любом случае нам нужны записи как можно более непринужденной речи, а не профессионально прочитанные аудиокниги, как в LibriSpeech.
В конце концов, мы решили сами собирать данные для обучения. Для этого мы привлекли Тестеров ВКонтакте. Мы готовили короткие тексты из 3–30 слов, которые нам диктовали в голосовых сообщениях. Тексты, которые должны были быть записаны, мы создавали сами на отдельной модели, которую обучали на комментариях публичных сообществ. Таким образом, мы получили дистрибутив из того же домена, где распространены сленг и случайная речь. Мы попросили тестировщиков записывать голосовые сообщения в различных условиях и говорить так, как они обычно говорят, чтобы наши обучающие данные максимально походили на то, что будет использоваться в реальных жизненных ситуациях.
Как всем известно, путь от описанных в статьях моделей (и даже их реализации специалистами по машинному обучению) до реального использования машинного обучения в продакшене — долгий путь. Поэтому наша инфраструктурная команда ВКонтакте начала работу над сервисом распознавания голосовых сообщений в самом начале 2020 года, когда у нас еще была первая версия модели.
Поэтому наша инфраструктурная команда ВКонтакте начала работу над сервисом распознавания голосовых сообщений в самом начале 2020 года, когда у нас еще была первая версия модели.
Команда специалистов по инфраструктуре помогла превратить наши решения машинного обучения в высоконагруженный, надежный сервис с высокой производительностью и эффективным использованием серверных ресурсов.
Одна из проблем заключалась в том, что мы в исследовательской группе работаем с файлами моделей и кодом C++, который их запускает. Но инфраструктура ВКонтакте в основном написана на Go, и нашим коллегам нужно было найти способ заставить C++ работать с Go. Для этого мы использовали расширение CGO, чтобы код более высокого уровня можно было писать на Go, а декодирование и общение с моделями оставалось на C++.
Наша следующая задача заключалась в том, чтобы обрабатывать голосовые сообщения в течение нескольких секунд, но заставить эту обработку работать с ограничениями нашего оборудования и эффективно использовать ресурсы сервера. Чтобы это стало возможным, мы сделали так, чтобы распознавание голоса работало на тех же серверах, что и другие сервисы. Это вызвало проблему с общим доступом к ядрам GPU и CUDA из нескольких процессов. Мы решили эту проблему с помощью технологии MPS от NVIDIA. MPS сводит к минимуму влияние блоков и простоев, позволяя нам использовать видеокарту на полную катушку без необходимости переписывать клиент.
Чтобы это стало возможным, мы сделали так, чтобы распознавание голоса работало на тех же серверах, что и другие сервисы. Это вызвало проблему с общим доступом к ядрам GPU и CUDA из нескольких процессов. Мы решили эту проблему с помощью технологии MPS от NVIDIA. MPS сводит к минимуму влияние блоков и простоев, позволяя нам использовать видеокарту на полную катушку без необходимости переписывать клиент.
Другим важным моментом, который следует учитывать, является группировка данных в пакеты для эффективной обработки на графическом процессоре. Дело в том, что в пакете акустической модели все аудиофайлы должны быть одинаковой длины. Поэтому нам нужно было уравнять их, добавив нули к более коротким дорожкам. Однако они также проходят через акустическую модель и занимают ресурсы GPU. В результате выравнивания на разбор коротких сообщений уходило больше времени и ресурсов.
Полностью избавиться от лишних нулей невозможно из-за вариативности длины записи, но их количество можно уменьшить. Для этого инфраструктурная команда придумала способ разбивать длинные голосовые сообщения на 23-25-секундные фрагменты, сортировать все треки и группировать похожие по длине в небольшие пакеты, которые уже находятся в пути для отправки через сеть. видеокарта. Это разделение голосовых сообщений было сделано с помощью алгоритма VAD от WebRTC. Он помогает распознавать паузы и отправляет в акустическую модель полные слова, а не их фрагменты. Продолжительность 23–25 секунд была выбрана в результате экспериментов. Более короткие фрагменты вызывали снижение показателей качества распознавания, а более длинные требовалось чаще выравнивать .
Для этого инфраструктурная команда придумала способ разбивать длинные голосовые сообщения на 23-25-секундные фрагменты, сортировать все треки и группировать похожие по длине в небольшие пакеты, которые уже находятся в пути для отправки через сеть. видеокарта. Это разделение голосовых сообщений было сделано с помощью алгоритма VAD от WebRTC. Он помогает распознавать паузы и отправляет в акустическую модель полные слова, а не их фрагменты. Продолжительность 23–25 секунд была выбрана в результате экспериментов. Более короткие фрагменты вызывали снижение показателей качества распознавания, а более длинные требовалось чаще выравнивать .
Подход с разбиением длинных записей, помимо оптимизации производительности, позволил нам транскрибировать аудио практически любой длины в текст и открыл поле для экспериментов с ASR для других задач продукта, таких как автоматические субтитры.
В июне 2020 года мы запустили в производство распознавание голосовых сообщений для сообщений длиной до 30 секунд (в эту продолжительность укладывается около 90% всех таких сообщений). Затем мы оптимизировали сервис, интегрировав более интеллектуальный способ нарезки треков. С ноября 2020 года мы можем распознавать голосовые сообщения продолжительностью до двух минут (9 минут).9% всех голосовых сообщений). Наша инфраструктура готова к будущим проектам и позволит нам обрабатывать аудиофайлы продолжительностью в несколько часов.
Затем мы оптимизировали сервис, интегрировав более интеллектуальный способ нарезки треков. С ноября 2020 года мы можем распознавать голосовые сообщения продолжительностью до двух минут (9 минут).9% всех голосовых сообщений). Наша инфраструктура готова к будущим проектам и позволит нам обрабатывать аудиофайлы продолжительностью в несколько часов.
Конечно, с момента запуска год назад многое изменилось. Мы обновили архитектуру акустической и языковой модели и добавили шумоподавление.
На данный момент весь пайплайн выглядит так:
- Получаем звуковую дорожку, предварительно ее обрабатываем и превращаем в спектрограмму.
- Если трек длиннее 25 секунд, мы разрезаем его с помощью VAD на фрагменты по 23–25 секунд. Этот вариант помогает нам не сокращать слова пополам.
- Далее все фрагменты прогоняются через акустическую (на основе QuartzNet) и языковую (с использованием n-грамм) модели.
- Затем все фрагменты собираются вместе и проходят через модель пунктуации с помощью нашей пользовательской архитектуры. Перед этим этапом мы также разбиваем слишком длинные тексты на сегменты по 400 слов.
- Мы объединяем все сегменты и даем пользователю расшифровку текста, которую он может быстро прочитать в любое время и в любом месте, экономя свое время.
 Перед этим этапом мы также разбиваем слишком длинные тексты на сегменты по 400 слов.
Перед этим этапом мы также разбиваем слишком длинные тексты на сегменты по 400 слов.Все это вместе образует уникальную услугу. Он может не только распознавать обыденную речь, сленг, ругательства и новые слова в шумной обстановке, но делает это быстро и эффективно. Вот процентили полного времени обработки голосового сообщения (без учета загрузки и отправки клиенту):
- 95-й процентиль: 1,5 секунды
- 99-й процентиль: 1,9 секунды
- 99,9-й процентиль: 2,5 секунды
количество количество голосовых сообщений, отправляемых во «ВКонтакте», выросло на 24% по сравнению с прошлым годом. Ежемесячно 33 миллиона человек слушают и отправляют голосовые сообщения. Для нас это означает, что нашим пользователям нужны голосовые технологии и стоит инвестировать в разработку новых решений.