Как скрыть заголовки страниц в WordPress и зачем вам это нужно
Зачем вам вообще скрывать заголовки страниц в WordPress?1 Вы используете обычную страницу WordPress в качестве домашней.
2 Вы создаете страницу и понимаете, что заголовок выглядит неуместным.
3 Вы хотите создать целевую страницу.
Давайте перейдем к делу: как скрыть заголовки страниц в WordPressПредупреждение: вот как НЕ скрывать заголовки страниц
Лучшие способы скрыть заголовки страниц в WordPress1 Использование темы WordPress для скрытия заголовков
2 Добавление кода в дочернюю тему WordPress для скрытия заголовков
Создать дочернюю тему (ВАЖНО)
Определите свой класс заголовка страницы
Определение идентификатора страницы
Поместите код в таблицу стилей
Это оно!
Страницы в WordPress по умолчанию имеют заголовки. Просто как тот.
В некоторых темах вы заметите, что заголовки иногда удаляются с определенных страниц, но в большинстве случаев вам придется пачкать руки и удалять их самостоятельно.
Почему?
Что ж, иногда заголовок не подходит для страницы, потому что он отвлекает или не смотрится на странице. Есть несколько дизайнерских приемов для замены или замаскирования заголовка страницы, но большинство из них требует некоторых догадок и проверок, а другие больше похожи на баннеры для решения, которое должно полностью скрыть заголовок.
Цель здесь – свести к минимуму все, что может показаться неуместным или озадачить пользователя. Ваш пользовательский интерфейс, очевидно, важен. Для некоторых страниц это особенно верно. Возьмите целевые страницы и статические страницы, используемые в качестве домашних страниц.
Если вас все еще интересует основная причина сокрытия заголовков страниц в WordPress, продолжайте читать ниже.
Зачем вам вообще скрывать заголовки страниц в WordPress?
Сначала вы можете задаться вопросом, почему скрытие заголовка страницы имеет какое-либо преимущество. Но я предполагаю, что в какой-то момент вы наткнулись на страницу, для которой не нужен заголовок по эстетическим причинам или потому, что это повредит вашему бизнесу в целом.
По каким причинам вы можете скрыть заголовок страницы?
1 Вы используете обычную страницу WordPress в качестве домашней.
Это случается довольно часто, когда вы не заинтересованы в регулярной ленте блога на главной странице. Так много веб-сайтов создают домашнюю страницу с определенными кнопками, мультимедиа и другими элементами, чтобы сделать домашнюю страницу WordPress по умолчанию более похожей на обычный веб-сайт. Иногда выбранная вами тема уже удаляет заголовок страницы за вас. В других случаях вам, возможно, придется пойти туда и выполнить задачу вручную.
Процесс создания обычной домашней страницы в качестве домашней часто называют «статической» страницей, где вы в основном удаляете заголовки «Домашняя страница» или «Домашняя страница», которые никому не нужно видеть в первую очередь.
2 Вы создаете страницу и понимаете, что заголовок выглядит неуместным.
Иногда вы можете создать страницу, для которой вообще не нужен заголовок. Я видел, как это происходило при встраивании таких вещей, как форумы или галереи на страницу. Даже некоторые страницы “Свяжитесь с нами” выглядят немного глупо с неприятными большими заголовками вверху. Я заметил, что это часто происходит, когда вы центрируете контент, а заголовок остается с левой стороны. Или иногда заголовок повторяется, или пользователи уже знают, где они заканчивают после нажатия на пункт меню.
Даже некоторые страницы “Свяжитесь с нами” выглядят немного глупо с неприятными большими заголовками вверху. Я заметил, что это часто происходит, когда вы центрируете контент, а заголовок остается с левой стороны. Или иногда заголовок повторяется, или пользователи уже знают, где они заканчивают после нажатия на пункт меню.
3 Вы хотите создать целевую страницу.
Целевая страница – одна из основных причин, по которой вам нужно избавиться от назойливого заголовка страницы. Целевые страницы предназначены для увеличения ваших конверсий, а заголовок часто отвлекает пользователя от таких областей, как форма подписки по электронной почте или кнопка «Купить». В конце концов, обычно нет причин сообщать людям, где они приземлились с заголовком, если они, скорее всего, щелкнули через рекламу Google или Facebook. Лучше начинать страницу с видео и полностью пропускать заголовок.
Давайте перейдем к делу: как скрыть заголовки страниц в WordPress
После того, как вы выполните поиск в Google на предмет скрытия заголовков страниц, вы можете наткнуться на статьи, в которых говорится об установке плагина для этой цели. К сожалению, этот плагин больше не доступен, поэтому нам придется выполнить его вручную.
К сожалению, этот плагин больше не доступен, поэтому нам придется выполнить его вручную.
Это тоже не обязательно плохо, поскольку удаление заголовка является довольно простой задачей, что в первую очередь делает сомнительным использование плагина, который может не обновляться. Некоторых может напугать добавление небольшого количества кода, но на самом деле это довольно просто. И у вас меньше шансов открыть уязвимости безопасности или замедлить работу вашего сайта (что может произойти с плагином).
Предупреждение: вот как НЕ скрывать заголовки страниц
Пользователи WordPress часто открывают страницу и оставляют поле заголовка пустым. Мы настоятельно не рекомендуем этого делать по двум причинам.
Во-первых, вам будет трудно найти эти страницы в будущем, поскольку WordPress отображает текст «без заголовка» в вашем списке страниц. Это не способ организовать ваши страницы, особенно если вы планируете использовать несколько страниц без заголовков.
Во-вторых, WordPress генерирует для вас собственную постоянную ссылку, когда поле заголовка остается пустым. Поэтому не забудьте отредактировать постоянную ссылку вручную. В противном случае ваш SEO пострадает, поскольку вы можете получить случайную постоянную ссылку с кучей цифр или слов, которые ничего не значат.
Поэтому не забудьте отредактировать постоянную ссылку вручную. В противном случае ваш SEO пострадает, поскольку вы можете получить случайную постоянную ссылку с кучей цифр или слов, которые ничего не значат.
Более того, страницы в WordPress не будут публиковаться, если у вас не введен заголовок. С другой стороны, сообщения публикуются без названия. Следовательно, если вы все же решите использовать этот метод (что не является хорошей идеей), вы должны опубликовать страницу с заголовком, затем вернуться, чтобы удалить заголовок и опубликовать его снова. Опять же, было бы несколько глупо даже подумать об этом, так что это скорее напоминание о недостатках метода.
Лучшие способы скрыть заголовки страниц в WordPress
У вас есть два варианта: использовать тему WordPress, которая включает встроенную опцию, чтобы скрыть заголовки, или добавить немного кода в дочернюю тему, чтобы внести изменения самостоятельно.
1 Использование темы WordPress для скрытия заголовков
Самый простой вариант – просто использовать тему, в которой уже есть возможность скрывать заголовки в сообщениях или страницах. Отличным примером является тема Total WordPress. Поскольку тема перетаскивания предназначена для различных целей, в нее встроены специальные функции, которые делают ее более гибкой. Это включает в себя множество дополнительных параметров обрезки изображений, ширины сайта и того, что отображается в верхней части страниц.
Отличным примером является тема Total WordPress. Поскольку тема перетаскивания предназначена для различных целей, в нее встроены специальные функции, которые делают ее более гибкой. Это включает в себя множество дополнительных параметров обрезки изображений, ширины сайта и того, что отображается в верхней части страниц.
Чтобы скрыть заголовок страницы в Total, просто создайте новую страницу (или откройте страницу, которую вы уже создали с помощью конструктора страниц с перетаскиванием, например, одного из этих распространенных инструментов конструктора веб-сайтов через инсайдер Website Builder), прокрутите вниз до «Настройки страницы », щелкните вкладку« Заголовок »и выберите параметр« Отключить »плитку страницы / публикации. Когда закончите, сохраните изменения.
Если заголовок страницы отключен, вы можете создать свой собственный макет. Просто не забудьте добавить заголовки на свою страницу при создании нового макета, используя правильные заголовки h2, h3, h4 и т.д.
Например, эта конкретная страница демонстрации Total Theme была построена с использованием пользовательских модулей Total для Visual Composer. Без стандартного заголовка или заголовка страницы, который мешает, эта целевая страница в стиле ресторана добавляет настраиваемый заголовок с кнопкой выноски (гораздо лучше для привлечения внимания посетителей).
Но если вы не хотите переключать темы, вы можете удалить заголовки страниц вручную, используя дочернюю тему.
2 Добавление кода в дочернюю тему WordPress для скрытия заголовков
У вас есть возможность вставить некоторые условия для тегов заголовков в файлы вашей темы. Но это звучит запутанно, и мы не пытаемся усложнять вам задачу.
Следовательно, вам следует выбрать скрытие определенных заголовков страниц в таблице стилей CSS.
Создать дочернюю тему (ВАЖНО)
Для начала вам необходимо создать дочернюю тему WordPress. Этот шаг имеет решающее значение для сохранения любых изменений, внесенных вами в таблицу стилей, при обновлении основной темы WordPress в будущем.
Для этого вам потребуется SFTP-доступ к вашему сайту WordPress, и мы не рекомендуем этот метод, если вы не знакомы с CSS, PHP или не используете свой сервер для доступа к файлам.
Но в основном вы создадите новую папку Theme-Child в wp-content / themes, добавите файл style.css в новую папку Theme-Child, а затем поставите в очередь исходный стиль темы, добавив файл functions.php с небольшим кода в папку Theme-Child (вы можете подробно увидеть этот процесс со скриншотами в нашем руководстве о том, как создать целевую страницу с помощью WordPress).
Когда ваша дочерняя тема готова к работе, вы можете перейти к следующему шагу.
Определите свой класс заголовка страницы
Перейдите к интерфейсу страницы, которую хотите отредактировать, и щелкните ее правой кнопкой мыши. Выберите параметр «Просмотр источника страницы» (иногда отображается как «Просмотр источника» или «Источник страницы» ). Вы также можете нажать «Проверить» для более плавного просмотра.
Это должно отобразить кучу кода. Мы пытаемся найти имя «класса», которое соответствует вашему тегу заголовка. Найдите имя своей страницы с помощью ярлыка «Найти» (Ctrl + F / Command + F)
Мы пытаемся найти имя «класса», которое соответствует вашему тегу заголовка. Найдите имя своей страницы с помощью ярлыка «Найти» (Ctrl + F / Command + F)
Например, заголовок на моей странице – «Свяжитесь с нами». При использовании ярлыка «Найти» он выделяет все экземпляры текста «Свяжитесь с нами». Вероятно, вам придется нажать Enter несколько раз, чтобы найти интересующий нас экземпляр.
Это похоже на снимок экрана ниже, где заголовок указан после тега «h2class =».
Класс расположен сразу после <h2 class = “. Итак, в этом примере это класс «main-title__primary». Иногда ваш класс называется так же, но авторы темы часто называют их по-разному.
Когда у вас есть класс вашего тега заголовка, скопируйте его, чтобы использовать позже.
Определение идентификатора страницы
Найти идентификатор страницы немного проще. В вашей панели управления WordPress. Откройте редактор страницы, для которой вы пытаетесь получить идентификатор страницы. Посмотрите URL-адрес этой страницы в своем браузере. Идентификатор вашей страницы – это число после «post =». Так что для меня это будет 171.
Идентификатор вашей страницы – это число после «post =». Так что для меня это будет 171.
Отметьте свой идентификатор страницы.
Поместите код в таблицу стилей
Теперь откройте новый файл style.css, который вы создали для своей папки Theme-Child, и вставьте следующий код:
/* Hide title on About Us page */
.page-id-171 .main-title__primary { display: none; }Единственная разница для вас заключается в том, что вы вставляете собственное имя страницы в нотацию, идентификатор страницы и класс.
После сохранения таблицы стилей вы сможете перейти к интерфейсу этой страницы и увидеть скрытый заголовок страницы. Если сначала это не сработает, попробуйте повторно опубликовать страницу.
Это оно!
Вот и все – пара простых способов удалить заголовок со страниц WordPress. Если у вас есть какие-либо вопросы о том, как скрыть заголовки страниц в WordPress, или советы по добавлению, которые, по вашему мнению, могут оказаться полезными для других читателей, сообщите нам об этом в комментариях ниже.
Источник записи: https://www.wpexplorer.com
15 скрытых возможностей Instagram, которые облегчат ведение аккаунта
Согласно Adweek, Instagram – вторая по величине социальная сеть в мире. Для нас, Instagram-зависимых, это неудивительно. Мы часами сидим в нем, листаем страницы, редактируем снимки, загружаем их и делимся с другими. Главный вопрос – используете ли вы все возможности Instagram?
Оказывается, в Instagram есть много функций, которые помогают улучшить пользовательский опыт, повышают вашу эффективность и позволяют персонализировать приложение. Мы нашли 15 скрытых возможностей и советов, как пользоваться Instagram.
1. Просматривайте понравившиеся публикации
Instagram сохраняет все посты, которые вы лайкнули. Если не знаете, как посмотреть понравившиеся публикации в Instagram, просто зайдите в свой профиль, нажмите кнопку “Настройки”, затем выберите “Аккаунт” и “Публикации, которые вам понравились”.
2. Скрывайте посты, в которых вас отметили
Как только вас отметили на фотографии в Instagram, она автоматически появляется во вкладке “Фото с вами”. Чтобы спрятать ее, перейдите во вкладку и кликните на фото, которое хотите убрать. Выберите тег, которым вас отметили, и опцию “Скрыть из профиля” в появившемся меню.
Чтобы спрятать ее, перейдите во вкладку и кликните на фото, которое хотите убрать. Выберите тег, которым вас отметили, и опцию “Скрыть из профиля” в появившемся меню.
Если вы пользуетесь редактором в Instagram, наверняка есть фильтры, которые вы применяете чаще всего, и те, которые вам не нравятся. Вы можете упорядочить их по своему усмотрению. Просто загрузите фото, пролистайте список фильтров и кликните опцию “Управление”.
Фильтры Instagram появятся в обычном порядке. Нажмите на нужный и, удерживая его, переставьте в начало или конец списка.
4. Добавляйте перенос строки
Чтобы сделать новый абзац, нажмите клавишу “123” и добавляйте переносы строки с помощью кнопки “Ввод”.
5. Сохраняйте посты и создавайте коллекции
У вас есть возможность не только посмотреть понравившиеся фото в Instagram, но и сохранить выбранные публикации. Также вы можете объединить их в подборки. Если не знаете, как посмотреть сохранения в Instagram, просто перейдите в свой профиль и кликните пункт “Сохраненное”. Вы увидите список сохраненных публикаций. Чтобы добавить их в подборку, нажмите на нужную и выберите соответствующую опцию.
Если не знаете, как посмотреть сохранения в Instagram, просто перейдите в свой профиль и кликните пункт “Сохраненное”. Вы увидите список сохраненных публикаций. Чтобы добавить их в подборку, нажмите на нужную и выберите соответствующую опцию.
6. Просматривайте фотографии по местоположению
Вы можете просматривать фото с тегами разных локаций. Для этого кликните на иконку поиска и введите название. Выберите нужную локацию из меню. Затем нажмите “Места”. Вы увидите все фотографии, сделанные там.
7. Спрячьте рекламу
Хоть Instagram старается показывать только релевантные рекламные объявления, они все равно могут раздражать. У вас есть возможность повлиять на ситуацию, сообщив Instagram, какую рекламу вы не хотите видеть. Чтобы спрятать ее, откройте опции рядом с нежелательным объявлением и кликните “Скрыть рекламу”. Нужно будет выбрать причину, почему вы не хотите видеть эту рекламу. Это поможет Instagram понять, какие объявления вам показывать.
8. Получайте уведомления от избранных аккаунтов
Эта функция полезна для компаний, которые следят за конкурентами. Включив уведомления, вы будете знать, когда они публикуют новый контент. Для этого кликните опции рядом с одной из фотографий и выберите “Включить уведомления о публикациях”.
9. Приглашайте подписчиков в групповые чаты из историй
Instagram расширил функции историй, добавив возможность приглашать пользователей в групповые чаты. Достаточно просто нажать на стикер “Чат” при создании истории и выбрать, кого из подписчиков пригласить. Но учтите, что в чате не может быть больше 32 участников.
10. Удаляйте комментарии
Кроме своих комментариев, вы можете удалять и те, которые под вашими постами оставляют другие пользователи. Для этого просто зажмите комментарий и кликните на иконку корзины.
11. Отключайте комментарииИногда лучше обойтись вообще без комментариев. Чтобы отключить возможность комментировать конкретную публикацию, загрузите ее, как обычно, перейдите в расширенные настройки и выберите опцию “Выключить комментарии”.
12. Архивируйте публикации
Если за годы ведения аккаунта в Instagram ваш стиль изменился, возможно, вы захотите почистить профиль от старых фотографий. При этом нет необходимости удалять их. Вы можете архивировать публикации. Они не будут отображаться на вашей странице, но вы сохраните к ним доступ. Просто выберите пост, который хотите отправить в архив Instagram, откройте опции и кликните соответствующий пункт.
Все заархивированные посты можно увидеть во вкладке “Архив” в опциях.
13. Прячьте хэштеги
Вам не нужна куча тегов под публикациями. Вы можете спрятать их, указав, что текста слишком много. В итоге будет отображаться сжатое сообщение с символом […] вместо хештегов. Кликните на кнопку «123» на клавиатуре и поставьте точку в поле для комментариев, затем нажмите «Return», чтобы начать новый абзац, и таким образом поставьте еще пять точек. Добавьте свои хештеги под точками. Теперь ваш комментарий будет выглядеть так:
14.
 Скрывайте истории от определенных пользователей
Скрывайте истории от определенных пользователейНе всем нужно видеть, что вы делаете. Если хотите скрыть свои истории в Instagram от конкретных людей, перейдите в профиль, нажмите опции, затем – “Настройки”. Выберите пункт “Конфиденциальность” – “История” – “Скрыть мою историю от” и введите имена людей, которых хотите исключить.
15. Перейдите на бизнес-аккаунт
Перейдя на бизнес-аккаунт, вы сможете получить доступ к статистике в Instagram и запускать рекламу. Это полезная опция для брендов, которая позволяет узнать целевую аудиторию, добавить CTA-кнопки и ознакомиться с аналитикой. В своем профиле выберите опции – “Настройки” – “Аккаунт” – “Переключиться на бизнес-аккаунт” и “Продолжить”. Затем надо будет заполнить все данные, привязать Facebook-аккаунт, ввести номер телефона, электронную почту и адрес компании. Нажмите “Готово” и пользуйтесь статистикой Instagram, а также другими преимуществами бизнес-аккаунта.
Если вы знаете другие полезные функции Instagram и хотите ими поделиться, напишите в комментариях, и мы обязательно их добавим.
Дайджест блога Depositphotos
Присоединяйтесь к сообществу из 160,000 читателей, которые раз в месяц
получают подборку креативных фото, полезных советов и интересных историй.
Спасибо, что подписались на ежемесячный дайджест блога Depositphotos!
Google объясняет, как скрыть веб-сайт из результатов поиска
Google утверждает, что лучший способ скрыть веб-сайт из результатов поиска — использовать пароль, но есть и другие варианты, которые вы можете рассмотреть.
Эта тема освещена в последнем выпуске серии видеороликов Ask Googlebot на YouTube.
Джон Мюллер из Google отвечает на вопрос о том, как предотвратить индексацию контента в поиске и разрешено ли это делать веб-сайтам.
«Короче говоря, да, можете, — говорит Мюллер.
Есть три способа скрыть сайт из результатов поиска:
- Использовать пароль
- Обход блока
- Индексация блока
Веб-сайты могут либо вообще отказаться от индексации, либо проиндексироваться и скрыть контент от робота Googlebot с помощью пароля.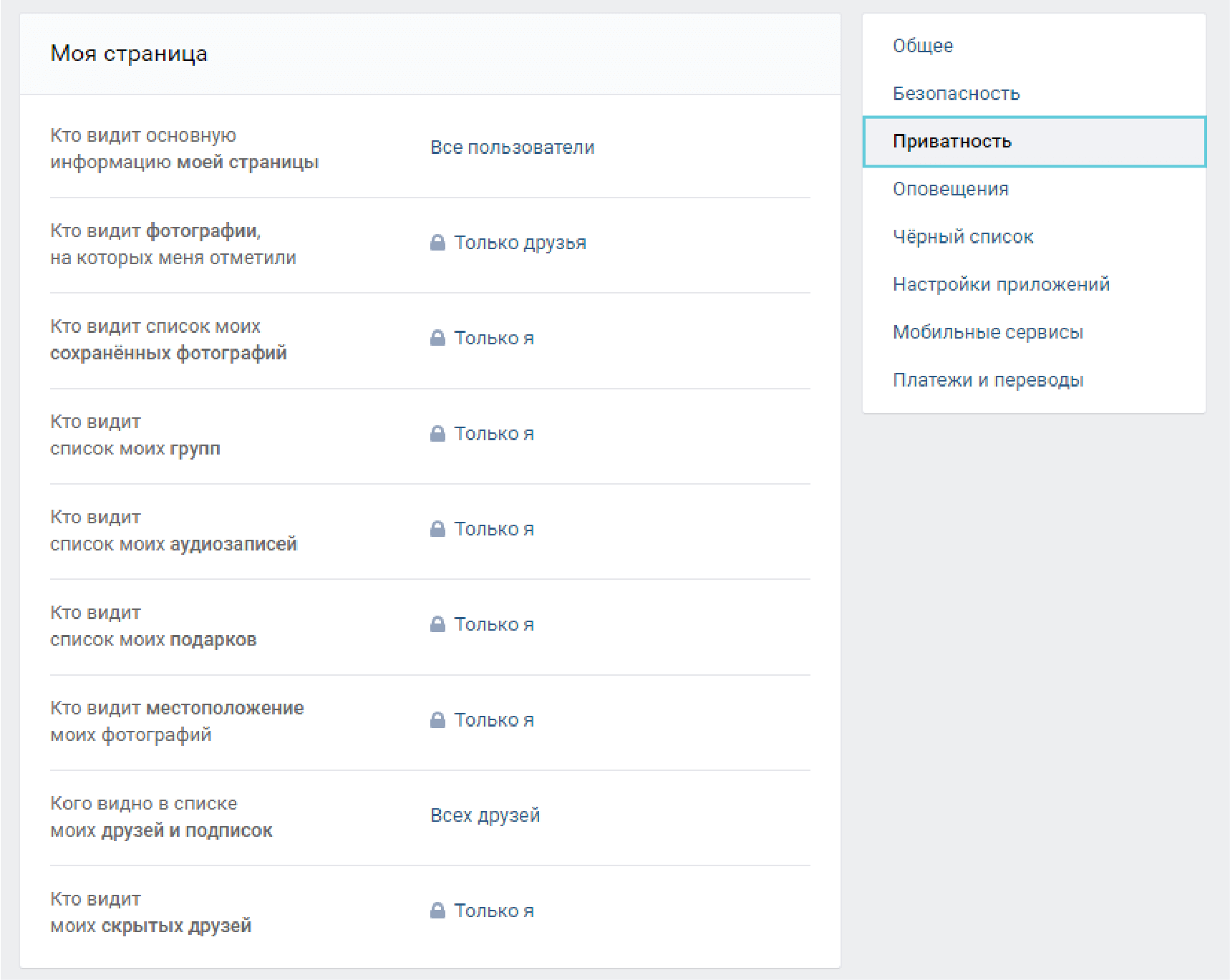
Блокировка контента от робота Googlebot не противоречит рекомендациям для веб-мастеров, если он одновременно заблокирован для пользователей.
Например, если сайт защищен паролем при сканировании роботом Googlebot, он также должен быть защищен паролем для пользователей.
В качестве альтернативы сайт должен иметь директивы, запрещающие роботу Googlebot сканировать или индексировать сайт.
У вас могут возникнуть проблемы, если ваш веб-сайт предоставляет другой контент для робота Googlebot, чем для пользователей.
Это называется «маскировкой» и противоречит рекомендациям Google.
С учетом этого различия, вот правильные способы скрытия контента от поисковых систем.
1. Защита паролем
Блокировка веб-сайта паролем часто является лучшим подходом, если вы хотите сохранить конфиденциальность своего сайта.
Пароль гарантирует, что ни поисковые системы, ни случайные пользователи сети не смогут увидеть ваш контент.
Это обычная практика для веб-сайтов в разработке. Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
2. Заблокировать сканирование
Еще один способ запретить роботу Googlebot доступ к вашему сайту — заблокировать сканирование. Это делается с помощью файла robots.txt.
С помощью этого метода люди могут получить доступ к вашему сайту по прямой ссылке, но она не будет обнаружена «приличными» поисковыми системами.
По словам Мюллера, это не лучший вариант, потому что поисковые системы могут индексировать адрес веб-сайта без доступа к его содержимому.
Такое случается редко, но о такой возможности вам следует знать.
3. Заблокировать индексирование
Третий и последний вариант — заблокировать индексирование вашего веб-сайта.
Для этого вы добавляете на свои страницы метатег noindex robots.
Тег noindex указывает поисковым системам не индексировать эту страницу до тех пор, пока после они не просканируют ее.
Пользователи не видят метатег и по-прежнему могут нормально заходить на страницу.
Заключительные мысли Мюллера
Мюллер завершает видео, говоря, что главная рекомендация Google — использовать пароль:
«В целом, для частного контента мы рекомендуем использовать защиту паролем. Легко проверить, работает ли он, и он не позволяет никому получить доступ к вашему контенту.
Блокировка сканирования или индексации — хорошие варианты, когда контент не является частным. Или если есть только части веб-сайта, которые вы не хотите отображать в поиске».
См. полное видео ниже:
Избранное изображение: снимок экрана с сайта YouTube.com/GoogleSearchCentral, ноябрь 2021 г.
Категория Новости SEO
Полное руководство по сокрытию страниц сайта от индексации
Индексация страниц сайта — это то, с чего начинается процесс поисковой оптимизации. Предоставление ботам движка доступа к вашему контенту означает, что ваши страницы готовы для посетителей, у них нет технических проблем, и вы хотите, чтобы они отображались в поисковой выдаче, поэтому всеобъемлющая индексация на первый взгляд кажется огромным преимуществом.
Предоставление ботам движка доступа к вашему контенту означает, что ваши страницы готовы для посетителей, у них нет технических проблем, и вы хотите, чтобы они отображались в поисковой выдаче, поэтому всеобъемлющая индексация на первый взгляд кажется огромным преимуществом.
Тем не менее, некоторые типы страниц лучше держать подальше от поисковой выдачи, чтобы обеспечить ваш рейтинг. Это означает, что вам нужно скрыть их от индексации. В этом посте я расскажу вам о типах контента, который нужно скрыть от поисковых систем, и покажу, как это сделать.
Содержание
- Страницы, которые нужно скрыть от поиска
- Как скрыть страницу из поиска
- Ограничение сканирования с помощью файлов robots.txt
- Ограничить индексирование с помощью метатега robots и тега X-Robots
- Роботы noindex метатег
- X-Robots-тег
- Особые случаи
Страницы, которые нужно скрыть от поиска
Давайте без лишних слов приступим к делу. Вот список страниц, которые вам лучше скрыть от поисковых систем, чтобы они не появлялись в поисковой выдаче.
Вот список страниц, которые вам лучше скрыть от поисковых систем, чтобы они не появлялись в поисковой выдаче.
Страницы с личными данными
Защита контента от прямого поискового трафика обязательна, если страница содержит личную информацию. Это страницы с конфиденциальной информацией о компании, информацией об альфа-продуктах, информацией о профилях пользователей, личной перепиской, платежными данными и т. д. Поскольку частный контент должен быть скрыт от кого-либо, кроме владельца данных, Google (или любая поисковая система) не должен t сделать эти страницы видимыми для более широкой аудитории.
Страницы входа
Если форма входа размещена не на главной, а на отдельной странице, нет необходимости показывать эту страницу в поисковой выдаче. Такие страницы не несут никакой дополнительной ценности для пользователей, которую можно считать малосодержательным контентом.
Страницы благодарности
Это страницы, которые пользователи видят после успешного действия на веб-сайте, будь то покупка, регистрация или что-то еще. Эти страницы также, вероятно, будут иметь мало контента и практически не несут никакой дополнительной ценности для пользователей.
Эти страницы также, вероятно, будут иметь мало контента и практически не несут никакой дополнительной ценности для пользователей.
Версии страниц для печати или чтения
Содержимое страниц этого типа дублирует содержимое основных страниц вашего веб-сайта, то есть эти страницы будут рассматриваться как дубликаты содержимого при сканировании и индексировании.
Страницы с похожими товарами
Это распространенная проблема для крупных веб-сайтов электронной коммерции, на которых много товаров, отличающихся только размером или цветом. Google может не определить разницу между ними и рассматривать их как дубликаты контента.
Внутренние результаты поиска
Когда пользователи приходят на ваш сайт из поисковой выдачи, они ожидают, что они нажмут на вашу ссылку и найдут ответ на свой запрос. Не очередная внутренняя поисковая выдача с кучей ссылок. Поэтому, если ваши внутренние результаты поисковой выдачи попадут в индекс, они, скорее всего, не принесут ничего, кроме низкого времени пребывания на странице и высокого показателя отказов.
Страницы с биографией автора в блогах с одним автором
Если в вашем блоге все сообщения написаны одним автором, то страница биографии автора является чистой копией главной страницы блога.
Страницы формы подписки
Подобно страницам входа в систему, формы подписки обычно не содержат ничего, кроме формы для ввода ваших данных для подписки. Таким образом, страница а) пуста, б) не представляет ценности для пользователей. Вот почему вы должны запретить поисковым системам вытягивать их в поисковую выдачу.
Страницы в разработке
Эмпирическое правило: страницы, находящиеся в процессе разработки, должны быть недоступны для роботов поисковых систем, пока они не будут полностью готовы для посетителей.
Зеркальные страницы
Зеркальные страницы — это идентичные копии ваших страниц на отдельном сервере/в другом месте. Они будут считаться техническими дубликатами, если будут просканированы и проиндексированы.
Специальные предложения и рекламные целевые страницы
Специальные предложения и рекламные страницы предназначены для просмотра пользователями только после выполнения ими каких-либо специальных действий или в течение определенного периода времени (специальные предложения, события и т. д.). После завершения мероприятия эти страницы не должны быть видны никому, в том числе поисковым системам.
д.). После завершения мероприятия эти страницы не должны быть видны никому, в том числе поисковым системам.
Хотите быстро научиться SEO?
Присоединяйтесь к нашему 30-дневному курсу SEO и ежедневно получайте по одному очень простому уроку SEO на свой почтовый ящик.
Как скрыть страницу из поиска
А теперь вопрос: как скрыть все вышеперечисленные страницы от надоедливых пауков и сохранить остальную часть вашего сайта видимой так, как она должна быть?
При настройке инструкций для поисковых систем у вас есть два варианта. Вы можете ограничить сканирование или ограничить индексирование страницы.
Ограничение сканирования с помощью файлов robots.txt
Возможно, самый простой и прямой способ ограничить доступ сканеров поисковых систем к вашим страницам — это создать файл robots.txt. Файлы robots.txt позволяют заблаговременно исключить нежелательный контент из результатов поиска. С помощью этого файла вы можете ограничить доступ к одной странице, целому каталогу или даже одному изображению или файлу.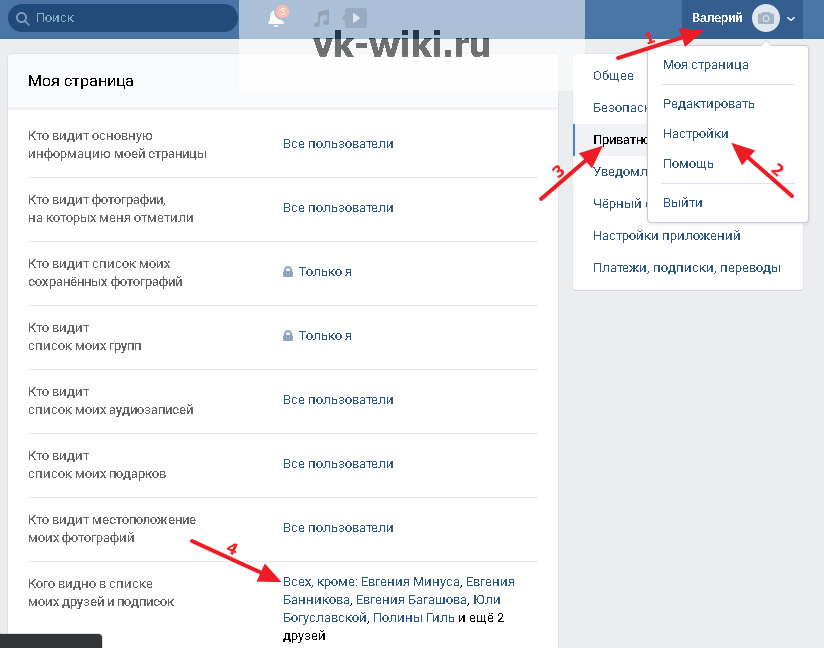
Как это работает
Создание файла robots.txt
Процедура довольно проста. Вы просто создаете файл .txt со следующими полями:
- User-agent: – в этой строке вы идентифицируете рассматриваемого поискового робота;
- Disallow: – две или более строк, которые предписывают указанным поисковым роботам не получать доступ к определенным частям сайта.
Обратите внимание, что некоторые поисковые роботы (например, Google) также поддерживают дополнительное поле с именем Разрешить: . Как следует из названия, Разрешить: позволяет явно перечислить файлы/папки, которые можно сканировать.
Вот некоторые основные примеры файлов robots.txt.
* в строке User-agent означает, что всем ботам поисковых систем предписывается не сканировать ни одну из страниц вашего сайта, что обозначается / . Скорее всего, это то, чего вы предпочли бы избежать, но теперь вы поняли идею.
В приведенном выше примере вы запрещаете роботу изображений Google сканировать ваши изображения в выбранном каталоге.
Дополнительные инструкции о том, как писать такие файлы вручную, можно найти в руководстве разработчика Google.
Но процесс создания robots.txt можно полностью автоматизировать — существует множество инструментов, способных создавать такие файлы. Например, WebSite Auditor может легко скомпилировать файл robots.txt для вашего сайта.
Когда вы запустите инструмент и создадите проект для своего веб-сайта, перейдите к Структура сайта > Страницы , щелкните значок гаечного ключа и выберите
Затем нажмите Добавить правило и указать инструкции. Выберите поискового робота и каталог или страницу, для которых вы хотите ограничить сканирование.
Загрузить WebSite Auditor Когда вы закончите со всеми настройками, нажмите Далее , чтобы инструмент сгенерировал файл robots. txt, который вы затем можете загрузить на свой веб-сайт.
txt, который вы затем можете загрузить на свой веб-сайт.
Чтобы просмотреть ресурсы, заблокированные для сканирования, и убедиться, что вы не запретили сканирование ничего, перейдите к Структура сайта > Аудит сайта и проверьте раздел Ресурсы, заблокированные от индексации :
Загрузить WebSite AuditorПримечание: Хотя файл robots.txt запрещает поисковым системам сканировать определенные страницы, URL-адреса этих страниц все же могут быть проиндексированы, если другие страницы указывают на них с описательным текстом. URL-адрес с ограниченным доступом может отображаться в результатах поиска без описания, поскольку контент не будет сканироваться и индексироваться.
Также имейте в виду, что протокол robots.txt носит исключительно рекомендательный характер. Это не блокировка страниц вашего сайта, а больше похоже на «Личное — не входить». Robots.txt может предотвратить доступ «законопослушных» ботов (например, ботов Google, Yahoo! и Bing) к вашему контенту. Однако вредоносные боты просто игнорируют его и все равно просматривают ваш контент. Таким образом, существует риск того, что ваши личные данные могут быть удалены, скомпилированы и повторно использованы под видом добросовестного использования. Если вы хотите, чтобы ваш контент был на 100% безопасным, вам следует ввести более безопасные меры (например, добавить регистрацию на сайте, скрыть контент под паролем и т. д.).
Однако вредоносные боты просто игнорируют его и все равно просматривают ваш контент. Таким образом, существует риск того, что ваши личные данные могут быть удалены, скомпилированы и повторно использованы под видом добросовестного использования. Если вы хотите, чтобы ваш контент был на 100% безопасным, вам следует ввести более безопасные меры (например, добавить регистрацию на сайте, скрыть контент под паролем и т. д.).
Распространенные ошибки
Вот наиболее распространенные ошибки, которые допускают люди при создании файлов robots.txt. Внимательно прочитайте эту часть.
1) Использование прописных букв в имени файла. Имя файла — robots.txt. Период. Не Robots.txt и не ROBOTS.txt
2) Не помещать файл robots.txt в основной каталог
3) Заблокировать весь ваш веб-сайт (если вы этого не хотите), оставив инструкцию запрета следующим образом
4) Неверное указание user-agent
5) Упоминание нескольких каталогов в одной строке запрета. Для каждой страницы или каталога нужна отдельная строка
Для каждой страницы или каталога нужна отдельная строка
6) Оставить строку агента пользователя пустой
7)
Список всех файлов в каталоге. Если вы скрываете весь каталог, вам не нужно заморачиваться перечислением каждого отдельного файла8) Без упоминания о строке запрета инструкций
9) Не указана карта сайта внизу файла robots.txt
10) Добавление инструкций noindex в файл
Ограничить индексирование с помощью метатега robots и X-Robots-tag
Использование метатега robots noindex или X-Robots-tag страницу, но предотвратить попадание страницы в индекс, т.е. от появления в результатах поиска.
Теперь давайте рассмотрим каждый вариант поближе.
Метатег robots noindex
Метатег robots noindex размещается в исходном коде HTML вашей страницы (раздел
). Процесс создания этих тегов требует совсем немного технических знаний и может быть легко выполнен даже младшим SEO-специалистом.
Как это работает
Когда бот Google получает страницу, он видит метатег noindex и не включает эту страницу в веб-индекс. Страница по-прежнему сканируется и существует по указанному URL-адресу, но не будет отображаться в результатах поиска независимо от того, как часто на нее ссылаются с любой другой страницы.
Примеры метатегов robots
Добавление этого метатега в HTML-код вашей страницы указывает роботу поисковой системы проиндексировать эту страницу и все ссылки переход с этой страницы.
Изменяя «follow» на «nofollow», вы влияете на поведение бота поисковой системы. Вышеупомянутая конфигурация тега указывает поисковой системе индексировать страницу, но не переходить ни по каким ссылкам, размещенным на ней.
Этот метатег указывает роботу поисковой системы игнорировать страницу, на которой он размещен, но переходить по всем размещенным на нем ссылкам.
Этот тег, размещенный на странице, означает, что ни страница, ни содержащиеся на ней ссылки не будут отслеживаться или индексироваться.
Примечание: Упомянутые выше атрибуты Nofollow и Follow не имеют ничего общего с rel=nofollow. Это две разные вещи. Rel=nofollow применяется к ссылкам, чтобы предотвратить передачу ссылочного веса. Упомянутый выше атрибут nofollow применяется ко всей странице и не позволяет сканерам переходить по ссылкам.
X-Robots-tag
Помимо метатега robots noindex, вы можете скрыть страницу, настроив ответ HTTP-заголовка с X-Robots-Tag со значением noindex или none .
Помимо страниц и элементов HTML, X-Robots-Tag позволяет не индексировать отдельные файлы PDF, видео, изображения или любые другие файлы, отличные от HTML, где использование метатегов robots невозможно.
Как это работает
Механизм очень похож на механизм тега noindex. Как только поисковый бот заходит на страницу, ответ HTTP возвращает заголовок X-Robots-Tag с инструкциями noindex. Страница или файл все еще сканируются, но не отображаются в результатах поиска.
Примеры тегов X-Robots
Это наиболее распространенный пример ответа HTTP с указанием не индексировать страницу.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Вы можете указать тип поискового бота, если вам нужно скрыть свою страницу от определенных ботов. В приведенном ниже примере показано, как скрыть страницу от любой другой поисковой системы, кроме Google, и запретить всем ботам переходить по ссылкам на этой странице:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
Если вы не укажете тип робота, инструкции будут действительны для всех типов сканеров.
Чтобы ограничить индексирование определенных типов файлов на всем веб-сайте, вы можете добавить инструкции ответа X-Robots-Tag в файлы конфигурации программного обеспечения веб-сервера вашего сайта.
Вот как вы ограничиваете все файлы PDF на сервере на базе Apache:
Набор заголовков X-Robots-Tag «noindex, nofollow»
И те же инструкции для NGINX:
location ~* \.pdf$ {
add_header X-Robots -Тэг » noindex, nofollow»;
}
Чтобы ограничить индексацию одного элемента, для Apache используется следующий шаблон:
# файл htaccess должен быть помещен в каталог соответствующего файла.
Набор заголовков X-Robots-Tag «noindex, nofollow»
А вот как вы ограничиваете индексацию одного элемента для NGINX:
location = /secrets/unicorn.pdf {
add_header X-Robots-Tag «noindex, nofollow»;
}
Тег robots noindex против X-Robots-Tag
Хотя тег robots noindex кажется более простым решением для ограничения индексации ваших страниц, в некоторых случаях использование X-Robots-Tag для страниц является лучший вариант :
- Не индексировать весь поддомен или категорию.
 X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;
X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой; - Нет индексирования файла, отличного от HTML. В этом случае X-Robots-Tag — не лучший, а единственный вариант, который у вас есть.
 X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;
X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;Тем не менее, помните, что только Google точно следует инструкциям X-Robots-Tag. Что касается остальных поисковых систем, то нет гарантии, что они правильно интерпретируют тег. Например, Seznam вообще не поддерживает теги x-robots. Поэтому, если вы планируете, чтобы ваш веб-сайт отображался в различных поисковых системах, вам необходимо использовать тег robots noindex 9.0060 во фрагментах HTML.
Распространенные ошибки
Наиболее распространенные ошибки пользователей при работе с тегами noindex:
1) Добавление неиндексируемой страницы или элемента в файл robots.txt. Robots.txt ограничивает сканирование, поэтому поисковые боты не будут заходить на страницу и видеть директивы noindex. Это означает, что ваша страница может быть проиндексирована без содержания и по-прежнему отображаться в результатах поиска.
Это означает, что ваша страница может быть проиндексирована без содержания и по-прежнему отображаться в результатах поиска.
Чтобы проверить, попала ли какая-либо из ваших папок с тегом noindex в файл robots.txt, проверьте Инструкции для роботов в разделе Структура сайта > Страницы WebSite Auditor.
Загрузить WebSite Auditor
Примечание. Не забудьте включить экспертные параметры и снять флажок «Следовать инструкциям robots.txt» при сборке проекта, чтобы инструмент видел инструкции, но не следовал им.
2) Использование прописных букв в директивах тегов. Согласно Google, все директивы чувствительны к регистру, поэтому будьте осторожны.
Особые случаи
Теперь, когда с основными проблемами индексации контента все более-менее понятно, перейдем к нескольким нестандартным случаям, заслуживающим отдельного упоминания.
1) Убедитесь, что страниц, которые вы не хотите индексировать, не включены в вашу карту сайта .
2) Тем не менее, если вам нужно деиндексировать страницу, которая уже присутствует в карте сайта, не удаляйте страницу из карты сайта, пока она не будет повторно просканирована и деиндексирована поисковыми роботами. В противном случае деиндексация может занять больше времени, чем ожидалось.
3) Защитите паролем страницы, содержащие личные данные. Защита паролем — самый надежный способ скрыть конфиденциальный контент даже от тех ботов, которые не следуют инструкциям robots.txt. Поисковые системы не знают ваших паролей, поэтому они не попадут на страницу, не увидят конфиденциальный контент и не выведут страницу в поисковую выдачу.
4) Чтобы поисковые роботы не индексировали саму страницу, но переходили по всем ссылкам на странице и индексировали контент по этим URL-адресам , настройте следующую директиву
Это обычная практика для внутренних страниц результатов поиска, которые содержат много полезных ссылок, но сами по себе не несут никакой ценности.
5) Для конкретного робота могут быть указаны ограничения индексации. Например, вы можете заблокировать свою страницу от новостных ботов, ботов с изображениями и т. д. Имена ботов могут быть указаны для любого типа инструкций, будь то файл robots.txt, метатег robots или X-Robots-Tag.
6) Не используйте тег noindex в A/B-тестах , когда часть ваших пользователей перенаправляется со страницы A на страницу B. Так как если noindex сочетается с 301 (постоянной) переадресацией, то поисковые системы получат следующие сигналы:
- Страница A больше не существует, так как она навсегда перемещена на страницу B;
- Страница B не должна быть проиндексирована, так как она имеет тег noindex.
В результате обе страницы A и B исчезают из индекса.
Чтобы правильно настроить A/B-тест, используйте переадресацию 302 (временную) вместо 301. Это позволит поисковым системам сохранить старую страницу в индексе и вернуть ее, когда вы закончите тест. Если вы тестируете несколько версий страницы (A/B/C/D и т. д.), используйте тег rel=canonical, чтобы отметить каноническую версию страницы, которая должна попасть в поисковую выдачу.
Если вы тестируете несколько версий страницы (A/B/C/D и т. д.), используйте тег rel=canonical, чтобы отметить каноническую версию страницы, которая должна попасть в поисковую выдачу.
7) Используйте тег noindex, чтобы скрыть временные целевые страницы. Если вы скрываете страницы со специальными предложениями, рекламные страницы, скидки или любой другой тип контента, который не должен просачиваться, то запрещать этот контент с помощью файла robots.txt — не лучшая идея. Поскольку сверхлюбопытные пользователи все еще могут просматривать эти страницы в вашем файле robots.txt. В этом случае лучше использовать noindex , чтобы случайно не скомпрометировать «секретный» URL публично.
Подводя итог
Теперь вы знаете основы того, как найти и скрыть определенные страницы вашего сайта от внимания поисковых роботов. И, как видите, процесс на самом деле несложный. Только не смешивайте несколько типов инструкций на одной странице и будьте внимательны, чтобы не скрыть страницы, которые должны отображаться в поиске.