как создать и реализовать в Senler, примеры схем чат-ботов
Поговорим о том, как создать квиз-тест и реализовать его в Senler.
Все больше мы слышим о так званых «квизах», которые должны (по идее) эффективно отрабатывать в наших маркетинговых стратегиях. Механизм прост — создаем квиз и отправляем партию трафика на посадочную страницу, где пользователей уже ожидает ряд вопросов. После чего, по классике жанра, он получает супер-предложение. Будь то скидка, купон, или что-либо из этого жанра.
Так, с этим разобрались. Но в данном материале я бы хотел сосредоточиться на квизах, которые реализованы в формате тестирования. Чуть ли не каждый (или каждый?) из нас уже стыкался с подобными вещами — «Узнай, какой ты герой из Marvel», «Каким пирожком ты был в прошлой жизни», «Какая профессия подходит вам больше всего» и так далее, и, естественно, тому подобное.
Данный формат, как по мне, требует большей подготовки, анализа и вот этого всего. Ведь в сети можно найти массу шаблонов для классических опросников — «Узнайте, сколько будет стоить кухня вашей мечты и получите 80% скидки». Не считаю, что это примитивно или не эффективно. Вот ни разу. Но уверен, что такой подход однозначно не есть универсальным.
Не считаю, что это примитивно или не эффективно. Вот ни разу. Но уверен, что такой подход однозначно не есть универсальным.
В этой статье я бы хотел рассказать, как создать квиз-тест (опросник) и о его реализации с помощью Senler. Реализовать можно многими способами, но в своем случае я решил сделать это в рамках ВК.
Что мы имеем? Проект — достаточно сложный продукт для здоровья. Его супер-сила — снижение аппетита. Поэтому логично предположить, что он будет (возможно) интересен тем, кто хочет похудеть, в процессе похудения, или просто желают поддерживать свою форму. Исходя из этого, тест затачивался под женскую аудиторию.
Как и в любой другой ситуации, в начале всего стоит анализ и построение гипотез. В конечном итоге я выделил несколько вариантов, но дабы все было лаконично — рассмотрим тот, который был первым в очереди на запуск и, соответственно, был реализован первым.
Квиз-тест — «Насколько вы склонны к перееданию?»Тема мне понравилась, осталась малость — найти вопросы и запустить это дело.
Поиск вопросов
Со старта у меня была единственная стратегия — прозондировать интернеты и найти подходящие вопросы с вариантами ответов именно там. Провел данную работу я в несколько этапов :
1. Выделил все ключевые запросы, по которым, в теории, должно быть нужное мне сырье.
2. Начал гуглить запросы
3. По каждому открывал 7-15 вкладок
4. Пробегал глазами по вопросам, либо сам быстренько проходил готовые тесты
5. Выделял ссылки, где была хотя бы часть адекватных вопросов
6. Передавал копирайтеру, который уже отбирал вопросы и вносил в них нужную редактуру. По факту – не составит труда сделать это лично, но времени было в обрез.
Для большинства тем данный алгоритм будет более менее универсальным. Теперь ближе к реальному примеру.
Это часть моего списка ссылок, которые удалось собрать. Небольшие тезисы, которые смогут помочь (когда-то) при последующих касаниях с данным списком.
Таким образом на выходе (с помощью копирайтера или своими усилиями) получаем список подходящих вопросов с ответами. Я остановился на цифре 5 — именно столько вопросов было в итоговом варианте теста.
Я остановился на цифре 5 — именно столько вопросов было в итоговом варианте теста.
Осталось прикрутить градацию результатов, дабы все это имело смысл. Особо не выдумывая, было принято решение внедрить 3 возможных результата теста. Условно говоря плохой, средний, и, соответственно, отличный.
На данном этапе все строится в формате гипотезы. Не удастся (скорее всего) со старта определить какой вопрос или ответ будет более/менее эффективным. Поэтому делаем вид, что текущий вариант является оптимальным, и двигаемся дальше.
Далее стоит подобрать картинку для каждого вопроса, дабы придать более презентабельный вид всему тесту. Не буду заострять на этом внимание, так как это субъективный момент, и выбирать стоит те изображения, который по вашему мнению подойдут лучше других.
После чего нужно создать сообщения, которые будут приходить пользователю в зависимости от его результатов. Здесь вновь все индивидуально. У нас была цель вывести пользователя на то, что у него либо есть проблема с перееданием, либо её практически нет, но еще есть куда расти. В данном случае я выступил в роле того, кто задаст мысленный вектор для копирайтера. Который, в свою очередь, упакует этот вектор в красивое сообщение.
В данном случае я выступил в роле того, кто задаст мысленный вектор для копирайтера. Который, в свою очередь, упакует этот вектор в красивое сообщение.
На самом деле, вся эта затея строилась как авто-воронка, которая в конечном итоге будет приводить всех пользователей к посадочной странице в виде лендинга самого продукта. Ну либо же соединение с живым менеджером, который сможет проконсультировать пользователя по поводу самого продукта.
Но сегодня мы не будем разбирать построение воронки.
Это тема для другого выпуска, а поэтому в данном материале акцентируется внимание непосредственно на создании главного элемента — это квиз, который выполнен в формате теста.
Квиз-тест: реализация задуманного
Примерно так выглядит схема чат-бота в Senler, которая отвечает за отправку основных вопросов.
Разберем несколько важных моментов в технической реализации такого дела.
За все время тестирования отсутствие кнопок у пользователя было единичным случаем. Но мы все равно учитываем этот момент, и указываем, что при отсутствии кнопок нужно написать «Нет» в ответ на данное сообщение.
Важный момент — галочка возле пункта «Клавиатура внутри сообщения». Это нужно сделать, дабы кнопки не пропадали по ходу всего теста.
«Ожидание ответа на сообщение» — это важно сделать, чтобы можно было отдельно прорабатывать ситуации, когда кнопка все же не появилась и пользователь хочет об этом сообщить.
Ставим блок с условием и проверяем наличие ответа «нет» в его сообщении. В положительном случае удаляем его из группы подписчиков, в которую попадают все, кто получает первое сообщение от бота. И добавляем следующим сообщением инструкцию:
Стандартные шаги для отображения кнопок и ключевое слово «Переедание». Соответственно, чтобы это функционировало, нужно добавить в настройках данной группы подписчиков ключевое слово «Переедание», которое автоматически добавит пользователя в данный чат-бот и отправит ему первое сообщение.
Творческий беспорядок творится на полотне Senler, но тем не менее. Чтобы все смотрелось красиво, я устанавливаю статус набора текста с таймером перед каждым сообщением. Своего рода имитация более менее реального человека.
Своего рода имитация более менее реального человека.
Дабы мы могли как-то считать набранные пользователем баллы, при нажатии кнопки «Начать» создается переменная «score», которой присваивается значение 0.
Теперь, при нажатии кнопки 1, 2 или 3 будем прибавлять нашей переменной соответствующую цифру. Это справедливо для каждого вопроса из теста, и в конечном итоге мы сможем сегментировать пользователей в зависимости от набранных баллов.
Если пользователю пришло первое сообщение и он никак не отреагировал за 12 часов, то мы отправляем ему дополнительное сообщение. В котором уточняем в чем дело и просим сообщить, если появились проблемы. Пользователь ответил — отправили данные администратору, который находится в боевой готовности, и готов вмешаться в диалог. Если же пользователь просто забыл или отвлекся — даем ему еще одну возможность нажать кнопку «Начать» и перейти к первому вопросу из теста.
Если на первом вопросе человек не нажал кнопку с ответом, а что-то отписал, то отправляем ему сообщение о том, что мы не можем разобрать его ответ и предлагаем либо связаться с менеджером, либо продолжить квиз-тест.
Если же прошло больше 3х часов после отправки пользователю вопроса и он никак не отреагировал, то отправляем ему еще одно сообщение. В условии мы проверяем количество баллов. Если оно равно 0 и он не состоит в группе тех, кто отписал вместо нажатия кнопки на первом вопросе — высылаем сообщение о том, что видимо что-то пошло не так. И здесь все та же схема — подключаем менеджера (администратора), либо же даем возможность начать квиз-тест заново.
По вопросам была универсальная схема. Ответ 1 — прибавляем 1 балл пользователю(+1 к переменной, созданной на первом этапе). И так далее. После чего устанавливался статус набора текста и таймер на несколько секунд, и отправлялся следующий вопрос. Плюс ко всему работала еще одна универсальная схема. Если вместо нажатия кнопки пользователь отправлял сообщение, то мы в свою очередь предлагали подключать менеджера или продолжать тестирование.
После всех вопросов нам нужно определить, какое сообщение отправлять дальше. Для этого мы добавляем блоки с условиями. Как я говорил в начале, у нас 3 сценария — плохой, средний и отличный. Предварительно нужно было посчитать сколько баллов будет оптимально под каждый сценарий. В итоге получилось следующее :
Как я говорил в начале, у нас 3 сценария — плохой, средний и отличный. Предварительно нужно было посчитать сколько баллов будет оптимально под каждый сценарий. В итоге получилось следующее :
1. Меньше 8 баллов — плохой результат
2. Больше 7 и меньше 13 — средний результат
3. Больше 12 — отличный результат
В соответствии с этим была построена все последующие взаимодействия с пользователем.
Базовый этап готов. Все последующие шаги в схеме — полноценная воронка, которая прорабатывалась отдельно. И это однозначно тема для продолжения цикла материалов по данному направлению.
А на сегодня все про квиз-тест, с этим закончили (выдохнули). Обнял, проанализировал, заплакал.
Назначение тестов учащимся с помощью Microsoft Teams
Microsoft Teams для образования Еще…Меньше
Функция «Задания» в Microsoft Teams позволяет отправлять ученикам тесты, созданные в Forms. Она позволяет ученикам прямо в Teams проходить тесты, а вам — выставлять оценки.
Назначьте тест учащимся в Teams
-
Перейдите в нужную команду класса и выберите Задания.
-
Выберите «Создать > quiz».
Выберите «+ Создать тест «, чтобы создать тест или выбрать существующий. Используйте панель поиска, если вы не видите тест, который вы ищете прямо сейчас.
Примечание: Если выбрать «+Создать тест«, на устройстве откроется новое окно веб-браузера.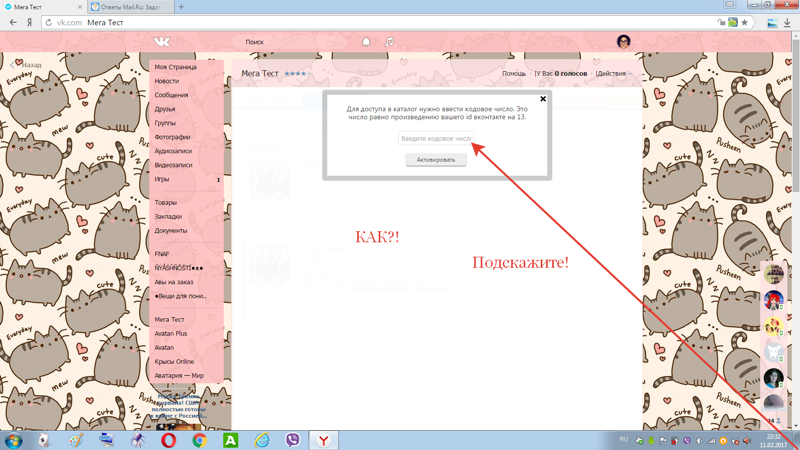 Создайте тест в Forms, а затем вернитесь к Teams. Теперь новый тест будет доступен для выбора и назначения учащимся.
Создайте тест в Forms, а затем вернитесь к Teams. Теперь новый тест будет доступен для выбора и назначения учащимся.
После выбора нужного теста он появится в задании в разделе «Инструкции». Введите остальные параметры задания и выберите Назначить.
Учащиеся смогут отправить тест непосредственно в Teams, где вы сможете оценить его.
Примечание: Формы автоматически вычисляют баллы, полученные за запросы с несколькими вариантами выбора. Дополнительные сведения о просмотре и возврате результатов теста см. в Teams этой статьи.Оценка и возврат отзывов учащимся
-
Выберите «Задания» в нужной команде класса, а затем выберите тест.

По умолчанию задания отображаются в порядке выполнения и показывают, сколько учащихся отправили каждое из них.
На вкладке «Вернуть» вы увидите, что всем учащимся назначен тест и состояние их работы: «Не сдано», «Просмотрено» и «Сдано».
Выберите «Включено» рядом с именем учащегося для проверки.
Совет: Вы можете открыть несколько тестов для проверки и оценки за раз. На вкладке «Вернуть»выберите раскрывающийся список «Состояние», чтобы отсортировать учащихся по статусу задания. Установите флажки для учащихся, которые сдают работу, а затем выберите выделенную группу, чтобы открыть ее.
-
Чтобы опубликовать оценку учащегося и вернуть ему оценку, выберите дополнительные параметры > оценки.
Выберите «Опубликовать», чтобы отправить окончательный отзыв и баллы.
-
Вернитесь к назначенной головоломке и обновите ее. Тесты, которые вы выполнили и вернули, будут отображаться на вкладке «Возвращено «.
 org/ListItem»>
org/ListItem»>
Представление оценки заданий откроется для результатов теста учащегося. При проверке вы можете:
Выберите «Рецензия» рядом, чтобы перейти от вопроса к вопросу при просмотре теста учащегося.
См. автоматические ответы с несколькими вариантами выбора. Формы уже будут иметь вычисляемые баллы, но вы можете изменить оценку, чтобы получить частичный или дополнительный кредит.
оставить отзыв по одному ответу.
Ознакомьтесь с краткими ответами и ответами на вопросы и добавьте баллы.
Выберите в верхней части теста, чтобы предоставить комментарии для всего теста.
При работе с несколькими тестами, которые были включены одновременно, используйте раскрывающееся меню на вкладке «Люди», чтобы перемещаться между учащимися.

Если вам нужно собрать ответы от учащихся за пределами сценария теста, вы по-прежнему можете использовать задания для распространения формы или опроса, выполненных в Forms.
-
В Microsoft Forms выберите форму или опрос, которые вы хотите назначить.
-
Откройте Teams и перейдите на вкладку «Назначения» в команде класса. Так же, как вы создали бы новое назначение для еврея,
-
Заполните инструкции по назначению и выберите «Добавить ресурсы».
-
В меню «Ресурсы» выберите вкладку » Ссылка», а затем вставьте ранее скопированную ссылку «Форма» и введите отображаемый текст. Выберите «Присоединить».
-
Заполните все оставшиеся сведения о назначении, а затем выберите « Назначить».
 org/ListItem»>
org/ListItem»>
В раскрывающемся списке меню «Общий доступ» скопируйте ссылку на форму.
Примечание: Убедитесь, что разрешения на просмотр заданы в соответствии с вашими потребностями в сценарии. При назначении учащимся только сотрудники моей организации могут отвечать на запросы, гарантируя конфиденциальность в вашем учебном заведении или округе, а любой пользователь, у которого есть ссылка, может быть полезен для отправки форм в семьи.

Дополнительные сведения
Microsoft Forms для образовательных учреждений
Создание теста с помощью Microsoft Forms
Создание задания в Microsoft Teams
Настройка ветвления в форме или тесте Microsoft Forms
Просмотр сведений о задании в Microsoft Teams (для учащихся)
VK-7212-301-4-04-Электроприводные клапаны Schneider в сборе
Магазин не будет работать корректно в случае, если куки отключены.
Похоже, в вашем браузере отключен JavaScript. Для наилучшего взаимодействия с нашим сайтом обязательно включите Javascript в своем браузере.
Подробная информация о продукте
Обзор
Клапаны HVAC, серия VB-7200
Артикул №
VK-7212-301-4-04
Клапан: 5/8 дюйма, 2W, шаровой, STR, 7B0003 FLR, 3
3
Информация о серииДокументы
Технические характеристики
| Артикул | ВК-7212-301-4-04 |
|---|---|
| Производитель | Шнайдер Электрик |
| Серия продуктов | ВБ-7200 |
| Семейная серия | Клапаны Schneider Electric HVAC, серия VB-7200 |
| Пропускная способность | Cv 4. 4 4 |
| Размер трубы | 0,625 дюйма |
| Тип соединения | Факел |
| Максимальное давление закрытия | 250 фунтов на кв. дюйм |
| Максимальное статическое давление | 321 фунтов на кв. дюйм |
| Рисунок корпуса | Двухсторонний |
| Тип клапана | Глобус |
| Двухпозиционный | |
| Материал отделки | Латунь |
| Диапазон средних температур | от 20 до 281 градусов по Фаренгейту |
| Расходная характеристика | Модифицированный равнопроцентный |
| Отказоустойчивый режим | Пружина нормально открытая |
| Вспомогательный концевой выключатель | SPDT |
| Вес нетто | 0 фунтов |
| Вес брутто | 0 фунтов |
© Copyright 2023 Galco Industrial Electronics, Все права защищены.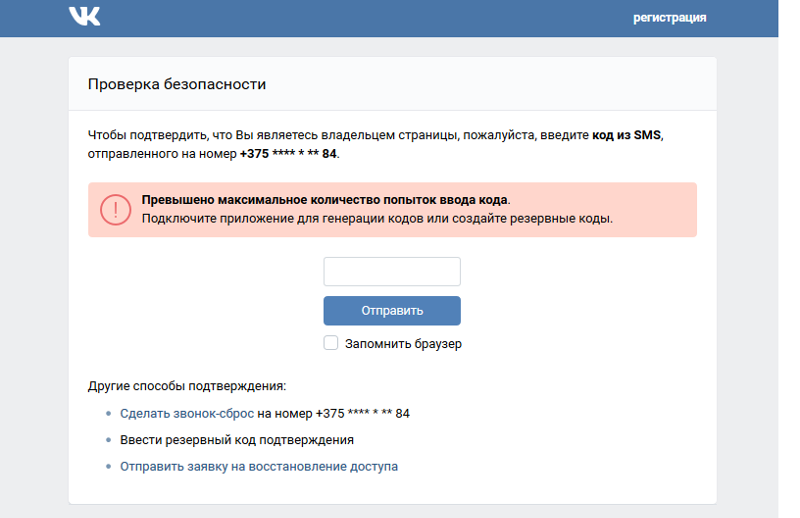
Как правильно выбрать статистические тесты для различных показателей A/B | Минтао Вэй
A Обсуждение методов перехода к 5 типам метрик A/B
В этой статье 5 категорий обобщаются метрики оценки теста A/B и описываются предлагаемые статистические тесты для их значений значимости в Таблица ниже.
Таблица по авторам- Зачем нам это нужно
- Среднее количество пользователей
- Показатели конверсии на уровне пользователя
- Показатели конверсии на уровне просмотра страницы
- Процентильные показатели
- Метрики SUM
- Резюме и практические советы
- Примечание
Несмотря на то, что t-тесты являются мощными, они не универсальны в мире данных, заполненном бизнес-метриками с различными распределениями, значительно отличающимися от хорошего одномодального распределения. нормальное распределение. Например, количество отправленных подарков и действий по обмену на пользователя обычно сильно искажено с серьезными выбросами. Это связано с тем, что поведение пользователей не так организовано и объективно, как статистические правила, а скорее эмоционально и обычно характеризуется экстремальными действиями.
Это связано с тем, что поведение пользователей не так организовано и объективно, как статистические правила, а скорее эмоционально и обычно характеризуется экстремальными действиями.
Как специалисты по данным, мы обязаны, а также в чем заключается наша ценность, глубже вникнуть в соответствующие методы тестирования для различных бизнес-показателей, которые имеют научный смысл с точки зрения статистики. Мы всегда будем напоминать себе о необходимости проверить выборочное распределение, прежде чем приступать к t-тестам.
В этом основном абзаце я обсуждаю подходящие методы тестирования, соответствующие каждой из 5 метрических категорий. Короче говоря, два ключевых аспекта в определении того, какой метод использовать, — это статистическая и экспериментальная точки зрения. В частности, мы хотели бы задать себе два вопроса:
- Соответствует ли выборочное распределение допущению (например, независимости, нормальности и т. д.) предлагаемых методов испытаний?
- Совпадает ли блок рандомизации с блоком анализа?
1.
 Средние пользовательские метрики (например, лайк/пользователь, время пребывания/пользователь и т. д.) В противном случае выберите U-критерий суммы рангов Манна-Уитни
Средние пользовательские метрики (например, лайк/пользователь, время пребывания/пользователь и т. д.) В противном случае выберите U-критерий суммы рангов Манна-Уитни Что такое средние показатели пользователя?
Показатели среднего количества пользователей — это показатели, которые усредняют общую эффективность бизнеса по количеству уникальных пользователей, например среднее количество лайков на пользователя и среднее время пребывания на пользователя в течение периода эксперимента. Они являются часто используемыми критериями оценки в тестах A/B, и это сравнение того, одинаковы ли математические ожидания или средние значения выборки между контрольной группой и экспериментальной группой, также является одним из наиболее распространенных и классических сценариев статистического тестирования.
Как проверить средние показатели пользователя
Методом проверки гипотезы на выборочной средней статистике обычно является двухвыборочный t-критерий . Проще говоря, двухвыборочный t-критерий определяет, равны ли ожидаемые средние метрики в двух совокупностях, путем сравнения выборочного среднего между двумя выборочными группами. два предположения откровенно, но менее точно:0006 Предположение о независимом распределении часто выполняется, поскольку каждого пользователя можно рассматривать как независимого человека*, а единицей рандомизации для эксперимента обычно является уровень пользователя (большинство экспериментов определяют, в какие экспериментальные группы попадает определенный пользователь, по его идентификатору пользователя). Обладая независимостью, можно применить центральную предельную теорему для получения нормальности , которая удовлетворяет этому предположению для двухвыборочного t-критерия. Стоит повторить, что, хотя надежность t-критерия при CLT признана, результат t-критерия в целом эффективен, даже если распределение населения не является технически нормальным (квази/асимптотически нормальным), что часто имеет место в реальных условиях.
Проще говоря, двухвыборочный t-критерий определяет, равны ли ожидаемые средние метрики в двух совокупностях, путем сравнения выборочного среднего между двумя выборочными группами. два предположения откровенно, но менее точно:0006 Предположение о независимом распределении часто выполняется, поскольку каждого пользователя можно рассматривать как независимого человека*, а единицей рандомизации для эксперимента обычно является уровень пользователя (большинство экспериментов определяют, в какие экспериментальные группы попадает определенный пользователь, по его идентификатору пользователя). Обладая независимостью, можно применить центральную предельную теорему для получения нормальности , которая удовлетворяет этому предположению для двухвыборочного t-критерия. Стоит повторить, что, хотя надежность t-критерия при CLT признана, результат t-критерия в целом эффективен, даже если распределение населения не является технически нормальным (квази/асимптотически нормальным), что часто имеет место в реальных условиях. мировые проблемы, робастность ограничена для распределений с неумеренным отклонением от нормальности (Bartlett, 1935; Snijders, 2011). Он становится менее надежным, если базовые распределения сильно искажены, мультимодальны или разрежены с экстремальными выбросами.
мировые проблемы, робастность ограничена для распределений с неумеренным отклонением от нормальности (Bartlett, 1935; Snijders, 2011). Он становится менее надежным, если базовые распределения сильно искажены, мультимодальны или разрежены с экстремальными выбросами.
В качестве примечания: графики квантилей-квантилей (QQ), гистограммы, критерий Шапиро-Уилка, критерий Колмогорова-Смирнова (КС) являются распространенными методами проверки нормальности.
 Это не только подразумевается в некоторых академических статьях (Delacre et al., 2017), но также и предлагается инженерами экспериментальных платформ в технологических компаниях на основе моего опыта, потому что это может быть вычислительно затратно и затратно по времени, чтобы извлечь все данные из базы данных и подтвердить, что дисперсии равны, что также обычно является ложным утверждением (вычисление дисперсий может быть очень обременительным в масштабе миллионов и миллиардов).
Это не только подразумевается в некоторых академических статьях (Delacre et al., 2017), но также и предлагается инженерами экспериментальных платформ в технологических компаниях на основе моего опыта, потому что это может быть вычислительно затратно и затратно по времени, чтобы извлечь все данные из базы данных и подтвердить, что дисперсии равны, что также обычно является ложным утверждением (вычисление дисперсий может быть очень обременительным в масштабе миллионов и миллиардов).Уравнение 1: t-статистикаДелакр и др. (2017) показывают, что критерий t Уэлча обеспечивает лучший контроль частоты ошибок типа 1, когда предположение об однородности дисперсии не выполняется, и он немного теряет в надежности по сравнению с критерием t 9 Стьюдента.0212 — тест, когда предположения выполняются. Поэтому они утверждают, что тест Уэлча t следует использовать в качестве стратегии по умолчанию.
Для этих сильно искаженных показателей непараметрический подход для двух независимых групп — U-критерий суммы рангов Манна-Уитни (тест MW) — является более подходящим, поскольку он использует «ранги», а не реальные значений, чтобы определить, является ли различие в показателях значительным, что позволяет избежать искажений, вносимых экстремальными значениями. Более того, чувствительность (мощность) MW-теста не разочаровывает даже тогда, когда он теряет информацию, заменяя абсолютные значения рангами, потому что другие параметрические тесты (например, t-критерий) имеют более существенное снижение способности делать истинные выводы. положительные выводы, когда распределение сильно асимметрично — 9Команда 0211 VK провела моделирование и продемонстрировала эту идею в мельчайших деталях. Я настоятельно рекомендую ознакомиться с их статьей на Medium здесь .
Более того, чувствительность (мощность) MW-теста не разочаровывает даже тогда, когда он теряет информацию, заменяя абсолютные значения рангами, потому что другие параметрические тесты (например, t-критерий) имеют более существенное снижение способности делать истинные выводы. положительные выводы, когда распределение сильно асимметрично — 9Команда 0211 VK провела моделирование и продемонстрировала эту идею в мельчайших деталях. Я настоятельно рекомендую ознакомиться с их статьей на Medium здесь .
Однако недостатком теста MW является то, что он требует больших вычислительных ресурсов, потому что он требует сортировки полного набора выборок для создания рангов, поэтому следует принять во внимание размер данных, прежде чем принять решение о проведении теста MW.
2. Показатели конверсии на уровне пользователя
Предлагаемый тест: пропорциональный Z-тест
Что такое показатели конверсии на уровне пользователя?
Конверсии на уровне пользователя — это метрики из бинарных результатов — удерживает этот пользователь или нет, конвертирует этот пользователь или нет и т. д. Другими словами, у всех пользователей будет только одно наблюдение, которое является идентификатором либо 1, либо 0, что делает показатели конверсии на уровне пользователей по существу . Биномиальная пропорциональная статистика (количество конвертированных пользователей/количество всех пользователей).
д. Другими словами, у всех пользователей будет только одно наблюдение, которое является идентификатором либо 1, либо 0, что делает показатели конверсии на уровне пользователей по существу . Биномиальная пропорциональная статистика (количество конвертированных пользователей/количество всех пользователей).
Как проверить показатели конверсии на уровне пользователя?
Согласно центральной предельной теореме (ЦПТ), мы можем безопасно аппроксимировать распределение биномиальной пропорциональной статистики, используя нормальные распределения. Другой способ думать об этом состоит в том, что пропорциональная биномиальная агрегация очень похожа на получение среднего , где CLT эффективно подтверждает нормальность распределения любых выборочных средних, когда общее количество пользователей (размер совокупности) достаточно велико. В результате z-тест становится идеальным кандидатом.
Уравнение 2: Биномиальная пропорция Предположение о нормальной аппроксимации обычно выполняется по сравнению с обсуждавшимися выше средними пользовательскими показателями, потому что лежащее в основе выборочное распределение является биномиальным, а не резко искаженным благодаря хорошему свойству бинарных событий Бернулли. Кроме того, количество пользователей, или численность населения, как правило, очень велико, чтобы поддерживать разумное приближение (мы часто уверены, когда N*p>5 и N*(1-p)>5 как правило. Подробнее см. в ссылке).
Кроме того, количество пользователей, или численность населения, как правило, очень велико, чтобы поддерживать разумное приближение (мы часто уверены, когда N*p>5 и N*(1-p)>5 как правило. Подробнее см. в ссылке).
Стоит отметить, что центральной предельной теореме нельзя доверять, а z-критерий нельзя применять, если значения выборки в эксперименте не являются независимыми и одинаково распределенными (i.i.d.) . Это не проблема в сценариях метрик на уровне пользователя, потому что по умолчанию блок рандомизации находится на пользователях, и поэтому мы считаем, что каждый человек ведет себя индивидуально. Однако это независимое допущение может оказаться неверным.0006, когда метрики агрегируются на более детальном уровне, чем пользователи, например метрики конверсии на уровне просмотра страницы в третьем разделе ниже.
Уравнение 3: z-статистика3. Показатели конверсии на уровне просмотра страницы
Предлагаемый тест: дельта-метод + T-тест
Какие существуют показатели конверсии на уровне просмотра страницы?
Одним из распространенных примеров является рейтинг кликов (CTR), определяемый как количество кликов / количество просмотров.
В чем проблема простого использования t-тестов?
Обычно сложно анализировать статистическую значимость показателей конверсии на уровне просмотров страниц, таких как рейтинг кликов (CTR), в экспериментах A/B. Существенная проблема заключается в том, что единица анализа (т. е. уровень события — события кликов и показов) отличается от единицы рандомизации (т. е. уровня пользователя), что может сделать недействительным наш t-тест и недооценить дисперсию.
В частности, когда мы вычисляем p-значения для CTR между экспериментальной и контрольной группами, мы, по сути, объединяем все события кликов и делим на все события показов всех пользователей в каждой группе, а t-тест разница. Этот процесс имеет врожденное предположение о нормальности, согласно которому выборки данных должны быть независимо взяты из нормального распределения. Иными словами, поскольку каждое выборочное наблюдение представляет собой событие просмотра, нам нужно убедиться, что все события просмотра независимы. В противном случае мы не сможем использовать CLT для подтверждения нормальности нашей средней статистики.
В противном случае мы не сможем использовать CLT для подтверждения нормальности нашей средней статистики.
Однако это предположение о независимости нарушается. В экспериментах A/B, где мы рандомизируем пользователей (, это обычно параметр по умолчанию, потому что у каждого пользователя будет непоследовательный опыт работы с продуктом, если мы рандомизируем сеансы ), у пользователя может быть несколько событий кликов/просмотров, и эти события коррелируют. с нашим здравым смыслом — мы можем в лучшем случае утверждать, что каждый человек ведет себя независимо, но поведение на данный момент и завтра не коррелирует во временном ряду. В результате выборочная дисперсия больше не будет объективной оценкой дисперсии генеральной совокупности — истинная выборочная дисперсия для нашей средней статистики может быть выше , чем наша оценка, потому что шагов ковариации в , и мы пропустили это в наших расчетах.
Таким образом, для метрик с детализацией на уровне событий неизбежно недооценивать дисперсию, если придерживаться традиционных методов t-критерия. Прямым следствием недооценки дисперсии выборки является ложноположительный результат. Истинная и высокая дисперсия может отклонить средние значения выборки от нулевой гипотезы и 0005 вводят нас в заблуждение относительно низких p-значений, даже если лечение неэффективно .
Прямым следствием недооценки дисперсии выборки является ложноположительный результат. Истинная и высокая дисперсия может отклонить средние значения выборки от нулевой гипотезы и 0005 вводят нас в заблуждение относительно низких p-значений, даже если лечение неэффективно .
Как решить эту проблему зависимости от образца?
Есть два способа решить эту проблему: (1) t-тест разницы с использованием дельта-метода или (2) продолжение t-теста с эмпирической дисперсией, оцененной с использованием бутстрэппинг-подхода , который также подчеркивается в документе < Надежные онлайн-контролируемые эксперименты: практическое руководство по A/B-тестированию >
Если единица рандомизации будет более грубой, чем единица анализа, например,
рандомизация пользователем и анализ рейтинга кликов (по страницам), будет работать, но требует более тонких методов анализа, таких как начальная загрузка или дельта метод (Дэн и др.
 , 2017 г., Дэн, Кноблих и Лу, 2018 г., Тан и др., 2010 г., Дэн и др., 2011 г.).
, 2017 г., Дэн, Кноблих и Лу, 2018 г., Тан и др., 2010 г., Дэн и др., 2011 г.).- Дельта-метод : Дельта-метод обычно считается более эффективным подходом. Ключевую идею можно интерпретировать как переписывание метрик коэффициента CTR на уровне просмотра страницы в отношение двух «метрик среднего уровня пользователя» и утверждение CLT для этой метрики отношения (используя разложение Тейлора и теорему Слуцкого) , чтобы мы могли преобразовать гранулярность анализа с уровня страницы на уровень пользователя , который теперь в соответствии с нашей единицей отвлечения (т.е. пользователем). Таким образом, нам удается восстановить i.i.d. потому что и наш числитель, и знаменатель являются средними значениями i.i.d. образцы . Используя CTR в качестве примера,
AVG.clicksиAVG.viewsсовместно являются двумерными нормальными в пределе и i.i.d., что составляетCTR, отношение двух средних значений также становится нормально распределенным (Кохави, Р. , Танг, Д., и Сюй, Ю. ( 2020)). Реализацию кода можно найти в посте Ахмада Нура Азиза здесь.
 , Танг, Д., и Сюй, Ю. ( 2020)). Реализацию кода можно найти в посте Ахмада Нура Азиза здесь.
, Танг, Д., и Сюй, Ю. ( 2020)). Реализацию кода можно найти в посте Ахмада Нура Азиза здесь.- Бутстрэппинг : Бутстрэппинг — это основанный на моделировании метод эмпирического расчета дисперсии выборочной средней статистики. Основная идея состоит в том, чтобы многократно брать множество выборок из всех событий просмотра в каждой группе, стратифицированных по идентификаторам пользователей, затем вычислять множество средних статистических данных из этих загрузочных выборок и соответствующим образом оценивать дисперсию для этих статистических данных. Стратификация по идентификатору пользователя обеспечивает i.i.d. предположение выполняется и оценка дисперсии заслуживает доверия.
Однако начальная загрузка требует больших вычислительных ресурсов, поскольку моделирование в основном манипулирует и агрегирует десятки миллиардов пользовательских журналов для многих итераций ( Сложность ~ O(nB), где n — размер выборки, а B — количество итераций начальной загрузки ). В результате, несмотря на его гибкость, он обычно не является первым вариантом в технологических компаниях и больше используется в качестве надежного эталона для перепроверки критически важных решений.
В результате, несмотря на его гибкость, он обычно не является первым вариантом в технологических компаниях и больше используется в качестве надежного эталона для перепроверки критически важных решений.
4. Показатели процентилей
Предлагаемый тест: Центральная предельная теорема (CLT) + Z-тест
Что такое показатели процентилей?
Квантильные метрики, такие как время загрузки страницы 95-го процентиля, имеют решающее значение для A/B-тестирования, поскольку многие бизнес-аспекты характеризуются пограничными случаями и поэтому лучше описываются квантильными метриками.
Какие проблемы возникают при тестировании процентильных показателей?
Большинство процентильных показателей, например, 95-процентная задержка загрузки страницы — это инженерные показатели производительности, определяемые в степени детализации просмотра страниц. Следовательно, единица рандомизации (пользователи) не будет соответствовать единице анализа (просмотры страниц), что делает недействительным предположение о независимости и оценку дисперсии генеральной совокупности с использованием дисперсии простой выборки.
Как протестировать процентильные показатели?
- Бутстрэппинг: Бутстрэппинг, как «универсально применимый» инструмент, может использоваться здесь для оценки эмпирической дисперсии и t-тестирования выборочных средних показателей процентилей. Опять же, тем не менее, его вычисление непомерно дорого и, следовательно, не может хорошо масштабироваться.
- CLT+Proportional Z-test: За кулисами стоит довольно много математики, но я постараюсь продемонстрировать основные идеи в простых терминах (настоятельно рекомендую прочитать Alex Deng (2021), если интересно). Для начала мы сначала исследуем распределение квантилей, статистики доказали, что выборочные процентили приблизительно нормальны:
о относится к стандартному отклонению того, меньше ли точка данных 95-го процентиля (его нельзя оценить «традиционным» способом Бернулли, поскольку здесь наблюдения зависят). F — неизвестная функция плотности вероятности для исходных данных.
F — неизвестная функция плотности вероятности для исходных данных.
Отлично! Поскольку квантили следуют нормальному распределению, мы можем использовать Z-тест для расчета p-значений. Что ж, в целом это то направление, в котором мы идем, но есть один важный блокировщик — 9.0005 σ , а также функция плотности вероятности F неизвестна, и ее может быть трудно оценить.
Итак, наша цель на данный момент — получить точную оценку дисперсии (обведено красным). В отрасли используется более одного подхода. Специалисты по данным в LinkedIn, Quora и Wish оценивают эту функцию плотности напрямую, в то время как Microsoft и TikTok ссылаются на новую идею, предложенную Алексом Денгом, Кноблихом и Лу (2018), которая обходит оценку функции плотности 9.0005 Ф . Вместо этого они сначала оценивают доверительный интервал для истинного процентиля, исследуя распределение биномиальной доли наблюдения, которая меньше процентиля, как показано в уравнении 7:
Уравнение 7: Доверительный интервал для 95-го процентиля Метрики назад, чтобы получить оценку дисперсии на основе длины аппроксимированного доверительного интервала. Уравнение 8: Получение стандартного отклонения из доверительного интервала
Уравнение 8: Получение стандартного отклонения из доверительного интервалаНаконец, с оценкой дисперсии мы можем приступить к вычислению z-статистики для нашей пробной процентили и соответствующих p-значений, аналогичных этим средним показателям.
5. Показатели SUM (не рекомендуется)
Предлагаемый тест: моделирование
Что такое показатели SUM?
Показатели SUM относятся к агрегированным показателям, включая общее количество раз чтения статьи, общий GMV, общее количество размещенных видео и т. д. для экспериментальной и контрольной групп.
Какие здесь проблемы?
Показатели SUM обычно являются путеводной звездой для разработки продукта, но их может быть трудно протестировать из-за недостаточной статистической достоверности и сопутствующих ошибок. В частности, метрики SUM можно разложить на метрик среднего пользователя и количества пользователей в экспериментальной и контрольной группах. неизбежная случайная ошибка, вызванная отклонением трафика .:
неизбежная случайная ошибка, вызванная отклонением трафика .:
В то время как средний показатель пользователя соответствует (квази)нормальному распределению, а отклонение трафика соответствует биномиальному распределению с p = 0,5, классическая статистика не имеет полное исследование относительно распределения продукта двух.
Как мы должны тестировать средние показатели пользователей?
Мы можем решить эту проблему с помощью моделирования . Поскольку два распределения являются детерминированными и независимыми, мы можем получить их собственную функцию плотности вероятности (PDF) путем итеративного рисования выборок. Если затем умножить два PDF, мы могли бы получить эмпирический PDF для метрики SUM. Таким образом, p-значение можно рассчитать, исследуя, как статистика SUM того, что мы фактически видим в экспериментальной группе, вписывается в наше смоделированное распределение.
Это относительно сложный процесс с большим количеством приближений. Поэтому обычно не рекомендуется. Я бы предложил протестировать эффективность/статистическую значимость функции продукта, используя среднюю метрику пользователя, и рассчитать дополнительный прирост в метрике SUM, если руководство действительно заботится об этом.
Изображение Diego PH на UnsplashВопрос о правильных статистических тестах, по сути, состоит в том, какой тест имеет наибольшую чувствительность или статистическую мощность с учетом данных эксперимента и контрольной группы.
Мощность тесно связана с лежащим в основе распределением наших показателей и независимостью наших выборок. Поэтому всегда рекомендуется проверять асимметрию распределения и обдумывать предположения перед тем, как приступить к анализу.
Ниже приведены три совета, основанные на моем личном опыте и моих знаниях из ссылок:
- Когда данные искажены, t-критерий не так надежен, а критерий Манна-Уитни не так уж слаб.
- Рассмотрите возможность преобразования метрики (например, логарифмическое преобразование), чтобы уменьшить асимметрию или даже заменить ее более нормально распределенной.
- Если вы не хотите возиться с устрашающей статистикой, попробуйте методы уменьшения дисперсии, такие как CUPED. В конце концов, наша цель — добиться высокой мощности и достоверности выводов о значимости.
- Все уравнения были закодированы автором вручную.
- *Каждый пользователь является независимым человеком: при условии отсутствия сетевого эффекта. Приведенный ниже фрагмент, цитируемый Алексом Денгом (2021), очень хорошо объясняет идею предположения о независимости в сценарии A/B-тестирования:
блок рандомизации… Общее практическое правило гласит, что мы всегда можем рассматривать блок рандомизации как i.i.d. Мы называем это 9Принцип блока рандомизации 0211 (RUP). Например, когда эксперимент рандомизирован по пользователю, просмотру страницы (С.
 Денг и др., 2011), количеству файлов cookie (Танг и др., 2010) или сеансу/посещению, RUP предлагает разумно предполагать наблюдения в каждый из эти уровни соответственно i.i.d. Ранее не было опубликованных работ, в которых прямо указывалось бы RUP. Но он широко используется в анализе A/B-тестов сообществом
Денг и др., 2011), количеству файлов cookie (Танг и др., 2010) или сеансу/посещению, RUP предлагает разумно предполагать наблюдения в каждый из эти уровни соответственно i.i.d. Ранее не было опубликованных работ, в которых прямо указывалось бы RUP. Но он широко используется в анализе A/B-тестов сообществом- Азиз, А.Н. (2021). Применение дельта-метода в анализе A/B-тестов. https://medium.com/@ahmadnuraziz3/applying-delta-method-for-a-b-tests-analysis-8b1d13411c22
- Bartlett, MS (1935, апрель). Влияние ненормальности на распределение t. В математические труды Кембриджского философского общества (Том 31, №2, стр. 223–231). Издательство Кембриджского университета.
- Денг, А., Кноблих, У., и Лу, Дж. (2018). Применение дельта-метода в метрической аналитике: практическое руководство с новыми идеями. In Материалы 24-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных (стр. 233–242).
- Дэн А. (2021). «8.6 Доверительный интервал и оценка дисперсии для процентильных показателей». В Причинно-следственный вывод и его приложения в онлайн-индустрии. https://alexdeng.github.io/causal/abstats.html#indvar
- Делакр, М., Лакенс, Д., и Лейс, К. (2017). Почему психологи должны по умолчанию использовать t-критерий Уэлча вместо t-критерия Стьюдента. International Review of Social Psychology , 30 (1).
- Ли, К.К. (2021). Как Wish A/B тестирует процентили. https://towardsdatascience.com/how-wish-a-b-tests-percentiles-35ee3e4589e7
- Лю, М., Сун, X., Варшней, М., и Сюй, Ю. (2019). Масштабные онлайн-эксперименты с квантильными метриками. Препринт arXiv arXiv:1903.08762 .
- Кохави, Р., Тан, Д., и Сюй, Ю. (2020). Надежные онлайн-контролируемые эксперименты: практическое руководство по A/B-тестированию. В книге «Надежные контролируемые онлайн-эксперименты: практическое руководство по A/B-тестированию» (стр.
 233–242).
233–242).
