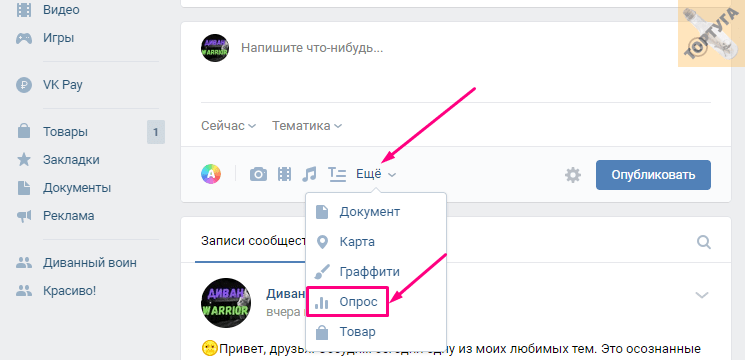
Как сделать интеллектуального чат-бота для проведения опросов/интервью / Хабр
В современном мире всё большую популярность приобретает методика под названием customer development для тестирования идей и гипотез о будущем продукте. Методику придумал «крёстный отец Кремниевой долины» Стив Бланк.
Одним из числа сильных инструментов в «разработке клиентов» является интервью, когда вы можете побеседовать с респондентом. Однако им не всегда можно воспользоваться ввиду разных причин, которые условно можно свести к объёму бюджета и имеющемуся времени. Но во многих ситуациях можно воспользоваться опросом. Причём опросом, который можно автоматизировать за счёт применения чат-бота и нейронной сети для определения смысла слов, которые написал респондент в ответ на заданный вопрос.
В этой статье сконцентрируюсь на алгоритме работы чат-бота для проведения опроса. Как сделать чат-бота для VK писал в отдельной статье на Хабре. Использовал: Python, MySQL, API VK и готовую нейросеть от RusVectores.
Статья будет полезна для тех, кто только начинает погружаться в тему и хотел бы получить информацию, изложенную в более простой, упрощённой форме.
Дисклеймер. Не претендую на академическую точность изложения, говорю лишь о том, что удалось понять на текущий момент по итогу изучения различных материалов. Не рекламирую какие-либо технологии и сервисы.
Содержание
Нейросеть для понимания смысла текста, вводимого пользователем
База данных для хранения вопросов интервью
Описание алгоритма работы чат-бота
Нейросеть для понимания смысла текста, вводимого пользователем
Сделать бота, который распознаёт только ключевые слова в фразе пользователя — не очень жизненно. Проверку всех ключевых слов можно постараться прописать в коде, но это трудоёмко и негибко. Поэтому стоит воспользоваться возможностями нейросетей для определения смысла введённых пользователем слов.
В данном решении была использована готовая нейросеть от сервиса RusVectores, обученная на корпусе НКРЯ с использованием алгоритма word2vec CBOW с длиной вектора 300.
НКРЯ – это совокупность русскоязычных текстов, Национальный Корпус Русского Языка в полном объёме. Содержит 270 миллионов слов, объём словаря 189 193 слова.
Word2vec CBOW — алгоритм, благодаря которому слово на естественном языке представляется в виде числового вектора. Т.е. определяет «координату» слова в «смысловом пространстве». CBOW – это аббревиатура Continuous Bag of Words. Она обозначает алгоритм, который есть в word2vec. Данный алгоритм называют моделью «мешка слов», он предсказывает слово по контексту. Ещё один алгоритм в word2vec — Skip-gram предсказывает контекст по слову.
С помощью данных алгоритмов генерируют близкие по смыслу слова при запросе в поисковой системе, сравнивают документы по смыслу, определяют смысловую близость слов и предложений.
Более подробно о word2vec можно почитать в статье «Немного про word2vec: полезная теория».
О векторном представлении слов (эмбеддинге) хорошо и с примерами описано в статье «Что такое эмбеддинги и как они помогают машинам понимать тексты».
Представление слова в виде вектора позволяет оценивать его смысловую близость с другими словами, так же представленными в виде вектора. Для оценки близости слов можно вычислить косинус угла между их векторами. Чем ближе к 1 будет косинус угла между векторами слов, тем они ближе по смыслу. Единице будет соответствовать косинус угла 0 градусов, т. е. когда векторы слов совпадают.
Чтобы создать такой набор векторов почти для 200 000 слов и постоянно иметь к ним доступ, нужно располагать вычислительными мощностями. Т.к. у меня таких мощностей нет, я воспользовался доступным онлайн сервисом RusVectores.
База данных для хранения вопросов
Для проведения опроса я подготовил табличку с вопросами и разместил её в базе данных MySQL. Как видно из рисунка ниже, вопросы имеют ответвления, похожие на древовидную структуру или структуру графа.
Структура вопросовВ базе данных таблица с вопросами выглядит так (фрагмент):
Фрагмент таблицы в БД с вопросамиПоле question_num служит для того, чтобы определить порядок вопросов и ответвления. Это путь от корневого элемента дерева вопросов до листового, разделённый точкой.
Это путь от корневого элемента дерева вопросов до листового, разделённый точкой.
Описание алгоритма работы чат-бота
Начало опроса
По договорённости с пользователем он заходит на страницу сообщества в ВК и инициирует диалог, нажав кнопку «Сообщение».
Бот здоровается и спрашивает разрешения начать опрос. Текст приветствия задавал в разделе «Управление»→ «Сообщения» на странице сообщества в ВК.
Если пользователь ответил что-то близкое по смыслу со словом «да», то бот начинает задавать вопросы. Как определить, что пользователь одобрил старт интервью? Для этого как раз нужна нейросеть, чтобы определить смысловую близость введённых пользователем слов к словам: да, можем, можно, начинай, ок. Для этого воспользуемся API сервиса RusVectores.
Далее приведён код функции, которая определяет начинать интервью или нет. Если интервью уже было начато, то функция определяет какой вопрос задать следующим.
фрагменты кода из bot_methods.
py
модуля, в котором реализованы все методы бота
 py
pydef _identify_phrase(user_id, user_message):
"""
identify start question or greeting
return number of phrase in database
"""
# identification variable, on start set "I don't know"
identi = 'I dont know'
# find in database current position in conversation between user and chatbot
identi = get_current_position_in_conversation(user_id)
if identi != 'err':
# if the conversation has just begun
if identi == '0':
# define greetings
similarity = _get_similarity(user_message, u'привет здравствуйте добрый')
if similarity > 0.5:
identi = "greetings"
else:
# define start interview or not
identi = _start_or_not(user_message)
# if the conversation continues
elif identi == '1':
# define start interview or not
identi = _start_or_not(user_message)
else:
pass
return identi Вначале определим возможность начать опрос исходя из ответа пользователя с помощью метода _start_or_not():
def _start_or_not(user_message):
"""
define <identi>: start or don't start interview
"""
if user_message != 'старт' or user_message != 'Старт':
_identi = 'I dont know'
# define if user agree to start interview
start = _get_similarity(user_message, u'да можем можно начинай ок')
# define if user don't agree to start interview
later = _get_similarity(user_message, u'нет позже потом завтра')
if start > later and start > 0. 15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identi 15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identi
15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identiЕсли пользователь решил сначала поприветствовать бота, то нужно понять это и поприветствовать в ответ. Для этого проверим на смысловую близость сообщения от пользователя со словами приветствия с помощью метода
def _get_similarity(text1, text2):
"""
Function return similarity between text1 and text2
text1 - user message
text2 - key words
"""
text1.strip() # delete empty space on start and end of string
text2.strip()
text1_words = text1.split(' ')
text2_words = text2.split(' ')
similarity = 0.0 # init variable
try:
for word1 in text1_words:
if word1 != '':
for word2 in text2_words:
if word2 != '':
# prepare url for request to API rusvectores. org
# url example https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019/дело__папка/api/similarity/
url = '/'.join(['https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarity  org
# url example https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019/дело__папка/api/similarity/
url = '/'.join(['https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarity
org
# url example https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019/дело__папка/api/similarity/
url = '/'.join(['https://rusvectores.org/ruscorpora_upos_cbow_300_20_2019',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarityПеременная similarity содержит числовое обозначение смысловой близость фраз text1 и text2. Чем ближе similarity к 1, тем ближе фразы по смыслу.
Метод _identify_phrase() используется для обработки всех фраз, которые пользователь пишет в чат.
фрагмент кода из mysqldb_methods.py
модуля, в котором реализованы все методы для работы с MySQL базой данных
def get_current_position_in_conversation(user_id):
"""
find in database current position in conversation between user and chatbot
using in bot_methods.py
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_num` FROM `conversations` WHERE `user_id`=%(user_id)s LIMIT 1"
cursor.execute(query, {'user_id': user_id})
result = cursor. fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identi fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identi
fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identiТаким образом мы обрабатываем три сценария взаимодействия с чат-ботом:
— старт опроса (понимаем согласен пользователь начать опрос или нет с помощью функции _start_or_not()),
— обмен приветствиями, если пользователь поздоровался (понимаем по смысловой близости к словам приветствия с помощью функции _get_similarity());
— движение по структуре вопросов с помощью функции get_current_position_in_conversation() для определения текущего положения в структуре вопросов.
Давайте рассмотрим движение по структуре вопросов более подробно.
Стоп-слова
Одним из важных моментов является удаление «стоп-слов», т.е. слов, которые можно с лёгкостью удалить из предложения и при этом его смысл не потеряется. Вот набор стоп-слов, которые я использовал в данном проекте:
stop_words = [ u'а', u'большой',u'бы',u'быть', u'в',u'весь',u'вот',u'всей',u'вы', u'говорить',u'год', u'для',u'до', u'еще',u'если', u'же', u'знать', u'и',u'из',u'или', u'к',u'как',u'который', u'мочь',u'мы',u'мне', u'на',u'наш',u'него',u'нее',u'них',u'но', u'о',u'один',u'она',u'они',u'оно',u'оный',u'от',u'ото', u'по', u'с',u'свой',u'себя',u'сказать', u'та',u'такой',u'такое',u'только',u'тот',u'ты',u'то', u'у', u'что', u'это',u'этот', u'я' ] stop_characters = [u'.
 ',u',',u' - ',u'- ',u' -',u':',u';',u'?',u'№',u'!',u'_',u'(',
u')',u'=',u'+',u"#",u'$',u'@',u'%',u'*',u' ',u'<',u'>','1','2','3','4','5','6',
'7','8','9','0']
',u',',u' - ',u'- ',u' -',u':',u';',u'?',u'№',u'!',u'_',u'(',
u')',u'=',u'+',u"#",u'$',u'@',u'%',u'*',u' ',u'<',u'>','1','2','3','4','5','6',
'7','8','9','0']С помощью метода _clear_text() очищаю предложение от стоп-слов:
Движение по структуре вопросов
Для определения в каком направлении опроса двигаться исходя из ответов респондента воспользуемся функцией _define_conversation_way():
def _define_conversation_way(user_message, identi):
"""
define in which way we are goin to?
"""
# all questions, unless № 3 has two ways: 'yes' (positive) or 'no' (negative)
if identi != '3' and identi != '6':
yes = _get_similarity(user_message, u'да заказывал просить')
no = _get_similarity(user_message, u'нет никогда')
elif identi == '6':
# the question number 6 has different ways: 'delivery' or 'self-delivery'
yes = _get_similarity(user_message, u'заказываю доставку')
no = _get_similarity(user_message, u'еду сам ищу аналог')
elif identi == '3':
# the question number 3 has different ways: 'from store' or 'delivery'
yes = _get_similarity(user_message, u'магазин сам')
no = _get_similarity(user_message, u'доставка почта все перечисленное курьер дом')
if yes > no and yes > 0. 15:
_way = 'yes'
elif no > yes and no > 0.15:
_way = 'no'
else:
_way = 'I dont know'
return _way
Для удобства использования я сгруппировал всю логику по определению того что бот должен ответить в функцию _get_bot_answer(). Для удобства восприятия приведу ниже не только данный метод, а модуль с методами бота в целом:
bot_methods.py
полный код модуля, в котором реализованы все методы бота
# -*- coding: utf-8 -*-
"""
Bot methods.
Realizes all what bot can do.
"3. Использование API сервиса RusVectores"
https://github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores_tutorial.ipynb
"""
import re # for work with regular expressions
import requests # for using HTTP requests
from bot_config import stop_words
from bot_config import stop_characters
from mysqldb_methods import get_current_position_in_conversation
from mysqldb_methods import get_question_from_DB
from mysqldb_methods import write_current_question_number_for_user
def get_bot_answer(user_id, user_message):
"""
using in views. py
make answer to user
"""
answer = ''
# delete stop-words and punctuation characters in sentence
user_message = _clear_text(user_message)
# identify what to do: start or continue conversation
identi = _identify_phrase(user_id, user_message)
if identi == 'greetings':
answer = get_question_from_DB('1')
write_current_question_number_for_user(user_id, '1')
elif identi == 'start':
answer = get_question_from_DB('2')
write_current_question_number_for_user(user_id, '2')
elif identi == 'later':
answer = "Когда у вас будет возможность пройти интервью напишите мне 'старт'."
elif identi == 'I dont know':
answer = "Я не совсем вас понимаю...\nУточните, пожалуйста."
elif identi == 'end':
answer = "Спасибо за ваше участие в интервью!"
else:
# if top-level question: 1, 2 or 3 etc.
if len(identi) == 1:
# define in which way we are goin to?
way = _define_conversation_way(user_message, identi)
if way == 'yes' or way == 'no':
if way == 'yes':
# going to positive way
question_num = '. '.join([identi,'1','1'])
if way == 'no':
# going to negative way
question_num = '.'.join([identi,'2','1'])
answer = get_question_from_DB(question_num)
if answer != 'None':
write_current_question_number_for_user(user_id, question_num)
else:
question_num = str(int(identi) + 1)
answer = get_question_from_DB(question_num)
write_current_question_number_for_user(user_id, question_num)
else:
# if way='I dont know'
answer = "Я не совсем вас понимаю...\nУточните, пожалуйста."
else:
# if subquestion: e.g. identi=2.1.1 or 3.2.2 etc.
identi_numbers = identi.split('.')
next_num = str(int(identi_numbers[2]) + 1)
question_num = '.'.join([identi_numbers[0],identi_numbers[1],next_num])
answer = get_question_from_DB(question_num)
# if we get end of subquestions in this top-level-question
if answer == 'None':
# going to the next top-level question
question_num = str(int(identi_numbers[0]) + 1)
# checking that the question is the last
if _is_the_last_question(question_num):
answer = get_question_from_DB(question_num)
question_num = 'end'
else:
# is not the last question
answer = get_question_from_DB(question_num)
write_current_question_number_for_user(user_id, question_num)
return answer
def _is_the_last_question(question_num):
"""
define is the last question?
by the condition (len(identi) == 1) of the function "get_bot_answer"
question_num has lenght 1
"""
is_the_last = True
question_num = str(int(question_num) + 1)
question = get_question_from_DB(question_num)
if question != 'None':
is_the_last = False
return is_the_last
def _define_conversation_way(user_message, identi):
"""
define in which way we are goin to?
"""
# all questions, unless № 3 has two ways: 'yes' (positive) or 'no' (negative)
if identi != '3' and identi != '6':
yes = _get_similarity(user_message, u'да заказывал просить')
no = _get_similarity(user_message, u'нет никогда')
elif identi == '6':
# the question number 6 has different ways: 'delivery' or 'self-delivery'
yes = _get_similarity(user_message, u'заказываю доставку')
no = _get_similarity(user_message, u'еду сам ищу аналог')
elif identi == '3':
# the question number 3 has different ways: 'from store' or 'delivery'
yes = _get_similarity(user_message, u'магазин сам')
no = _get_similarity(user_message, u'доставка почта все перечисленное курьер дом')
if yes > no and yes > 0. 15:
_way = 'yes'
elif no > yes and no > 0.15:
_way = 'no'
else:
_way = 'I dont know'
return _way
def _identify_phrase(user_id, user_message):
"""
identify start question or greeting
return number of phrase in database
"""
# identification variable, on start set "I don't know"
identi = 'I dont know'
# find in database current position in conversation between user and chatbot
identi = get_current_position_in_conversation(user_id)
if identi != 'err':
# if the conversation has just begun
if identi == '0':
# define greetings
similarity = _get_similarity(user_message, u'привет здравствуйте добрый')
if similarity > 0.5:
identi = "greetings"
else:
# define start interview or not
identi = _start_or_not(user_message)
# if the conversation continues
elif identi == '1':
# define start interview or not
identi = _start_or_not(user_message)
else:
pass
return identi
def _start_or_not(user_message):
"""
define <identi>: start or don't start interview
"""
if user_message != 'старт' or user_message != 'Старт':
_identi = 'I dont know'
# define if user agree to start interview
start = _get_similarity(user_message, u'да можем можно начинай ок')
# define if user don't agree to start interview
later = _get_similarity(user_message, u'нет позже потом завтра')
if start > later and start > 0. 15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identi
def _clear_text(sentence):
"""
delete stop-words and punctuation characters in sentence
"""
try:
# sentence to low-case
sentence = sentence.lower()
# delete stop-characters
for char in stop_characters:
sentence = sentence.replace(char, '')
# delete stop-words
words_of_sentence = sentence.split(' ')
result = ''
for word in words_of_sentence:
if word not in stop_words:
result = result + ' ' + word
except Exception as e:
result = str(e)
return result
def _get_similarity(text1, text2):
"""
Function return similarity between text1 and text2
:param text1: user message
:param text2: key words
"""
text1.strip() # delete empty space on start and end of string
text2.strip()
text1_words = text1. split(' ')
text2_words = text2.split(' ')
similarity = 0.0 # init variable
try:
for word1 in text1_words:
if word1 != '':
for word2 in text2_words:
if word2 != '':
# prepare url for request to API rusvectores.org
# url example http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018/дело__папка/api/similarity/
url = '/'.join(['http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarity py
make answer to user
"""
answer = ''
# delete stop-words and punctuation characters in sentence
user_message = _clear_text(user_message)
# identify what to do: start or continue conversation
identi = _identify_phrase(user_id, user_message)
if identi == 'greetings':
answer = get_question_from_DB('1')
write_current_question_number_for_user(user_id, '1')
elif identi == 'start':
answer = get_question_from_DB('2')
write_current_question_number_for_user(user_id, '2')
elif identi == 'later':
answer = "Когда у вас будет возможность пройти интервью напишите мне 'старт'."
elif identi == 'I dont know':
answer = "Я не совсем вас понимаю...\nУточните, пожалуйста."
elif identi == 'end':
answer = "Спасибо за ваше участие в интервью!"
else:
# if top-level question: 1, 2 or 3 etc.
if len(identi) == 1:
# define in which way we are goin to?
way = _define_conversation_way(user_message, identi)
if way == 'yes' or way == 'no':
if way == 'yes':
# going to positive way
question_num = '.
py
make answer to user
"""
answer = ''
# delete stop-words and punctuation characters in sentence
user_message = _clear_text(user_message)
# identify what to do: start or continue conversation
identi = _identify_phrase(user_id, user_message)
if identi == 'greetings':
answer = get_question_from_DB('1')
write_current_question_number_for_user(user_id, '1')
elif identi == 'start':
answer = get_question_from_DB('2')
write_current_question_number_for_user(user_id, '2')
elif identi == 'later':
answer = "Когда у вас будет возможность пройти интервью напишите мне 'старт'."
elif identi == 'I dont know':
answer = "Я не совсем вас понимаю...\nУточните, пожалуйста."
elif identi == 'end':
answer = "Спасибо за ваше участие в интервью!"
else:
# if top-level question: 1, 2 or 3 etc.
if len(identi) == 1:
# define in which way we are goin to?
way = _define_conversation_way(user_message, identi)
if way == 'yes' or way == 'no':
if way == 'yes':
# going to positive way
question_num = '.
 15:
_way = 'yes'
elif no > yes and no > 0.15:
_way = 'no'
else:
_way = 'I dont know'
return _way
def _identify_phrase(user_id, user_message):
"""
identify start question or greeting
return number of phrase in database
"""
# identification variable, on start set "I don't know"
identi = 'I dont know'
# find in database current position in conversation between user and chatbot
identi = get_current_position_in_conversation(user_id)
if identi != 'err':
# if the conversation has just begun
if identi == '0':
# define greetings
similarity = _get_similarity(user_message, u'привет здравствуйте добрый')
if similarity > 0.5:
identi = "greetings"
else:
# define start interview or not
identi = _start_or_not(user_message)
# if the conversation continues
elif identi == '1':
# define start interview or not
identi = _start_or_not(user_message)
else:
pass
return identi
def _start_or_not(user_message):
"""
define <identi>: start or don't start interview
"""
if user_message != 'старт' or user_message != 'Старт':
_identi = 'I dont know'
# define if user agree to start interview
start = _get_similarity(user_message, u'да можем можно начинай ок')
# define if user don't agree to start interview
later = _get_similarity(user_message, u'нет позже потом завтра')
if start > later and start > 0.
15:
_way = 'yes'
elif no > yes and no > 0.15:
_way = 'no'
else:
_way = 'I dont know'
return _way
def _identify_phrase(user_id, user_message):
"""
identify start question or greeting
return number of phrase in database
"""
# identification variable, on start set "I don't know"
identi = 'I dont know'
# find in database current position in conversation between user and chatbot
identi = get_current_position_in_conversation(user_id)
if identi != 'err':
# if the conversation has just begun
if identi == '0':
# define greetings
similarity = _get_similarity(user_message, u'привет здравствуйте добрый')
if similarity > 0.5:
identi = "greetings"
else:
# define start interview or not
identi = _start_or_not(user_message)
# if the conversation continues
elif identi == '1':
# define start interview or not
identi = _start_or_not(user_message)
else:
pass
return identi
def _start_or_not(user_message):
"""
define <identi>: start or don't start interview
"""
if user_message != 'старт' or user_message != 'Старт':
_identi = 'I dont know'
# define if user agree to start interview
start = _get_similarity(user_message, u'да можем можно начинай ок')
# define if user don't agree to start interview
later = _get_similarity(user_message, u'нет позже потом завтра')
if start > later and start > 0.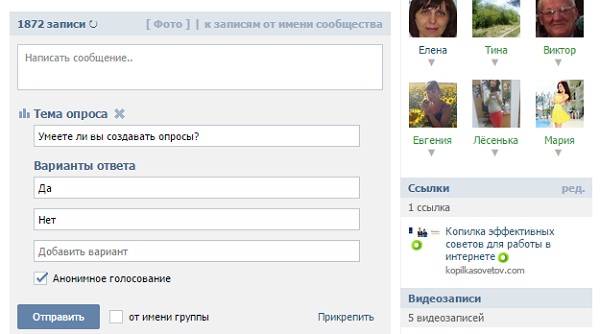 15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identi
def _clear_text(sentence):
"""
delete stop-words and punctuation characters in sentence
"""
try:
# sentence to low-case
sentence = sentence.lower()
# delete stop-characters
for char in stop_characters:
sentence = sentence.replace(char, '')
# delete stop-words
words_of_sentence = sentence.split(' ')
result = ''
for word in words_of_sentence:
if word not in stop_words:
result = result + ' ' + word
except Exception as e:
result = str(e)
return result
def _get_similarity(text1, text2):
"""
Function return similarity between text1 and text2
:param text1: user message
:param text2: key words
"""
text1.strip() # delete empty space on start and end of string
text2.strip()
text1_words = text1.
15:
_identi = 'start'
elif later > start and later > 0.15:
_identi = 'later'
else:
_identi = "start"
return _identi
def _clear_text(sentence):
"""
delete stop-words and punctuation characters in sentence
"""
try:
# sentence to low-case
sentence = sentence.lower()
# delete stop-characters
for char in stop_characters:
sentence = sentence.replace(char, '')
# delete stop-words
words_of_sentence = sentence.split(' ')
result = ''
for word in words_of_sentence:
if word not in stop_words:
result = result + ' ' + word
except Exception as e:
result = str(e)
return result
def _get_similarity(text1, text2):
"""
Function return similarity between text1 and text2
:param text1: user message
:param text2: key words
"""
text1.strip() # delete empty space on start and end of string
text2.strip()
text1_words = text1. split(' ')
text2_words = text2.split(' ')
similarity = 0.0 # init variable
try:
for word1 in text1_words:
if word1 != '':
for word2 in text2_words:
if word2 != '':
# prepare url for request to API rusvectores.org
# url example http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018/дело__папка/api/similarity/
url = '/'.join(['http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarity
split(' ')
text2_words = text2.split(' ')
similarity = 0.0 # init variable
try:
for word1 in text1_words:
if word1 != '':
for word2 in text2_words:
if word2 != '':
# prepare url for request to API rusvectores.org
# url example http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018/дело__папка/api/similarity/
url = '/'.join(['http://rusvectores.org/araneum_none_fasttextcbow_300_5_2018',
word1 + '__' + word2, 'api', 'similarity/'])
# GET request to API rusvectores.org
r = requests.get(url, stream=True)
# sum similarity of couple of words
similarity = similarity + float(r.text.split('\t')[0])
except Exception as e:
log_exception = str(e)
# average similarity
similarity = similarity/len(text2_words)
# return similarity between text1 and text2
return similarityКак видно из кода, с помощью метода write_current_question_number_for_user() бот сохраняет в базу данных текущую позицию в диалоге с пользователем. Это необходимо для того, чтобы бот понимал какой следующий вопрос нужно задать респонденту.
Это необходимо для того, чтобы бот понимал какой следующий вопрос нужно задать респонденту.
Функция get_question_from_DB() возвращает текст вопроса из базы данных для того, чтобы бот задал его в чате.
Для удобства приведу полный код модуля с методами для работы с базой данных:
mysqldb_methods.py
полный код модуля, в котором реализованы все методы для работы с MySQL базой данных
# -*- coding: utf-8 -*-
"""
Methods for work with MySQL database.
"""
import MySQLdb # before using it do in ssh: pip install mysqlclient
"""
import configuration variables for connect to MySQL database:
"""
from mysqldb_config import HOST
from mysqldb_config import USER
from mysqldb_config import PASSWORD
from mysqldb_config import DATABASE
def write_current_question_number_for_user(user_id, question_num):
"""
write question number to database for this user
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn. cursor()
if question_num == '2':
query = (
"INSERT INTO `conversations`(`user_id`, `question_num`) "
"VALUES (%s, %s)"
)
data = (user_id, question_num)
else:
query = (
"UPDATE `conversations` "
"SET `question_num`=%s "
"WHERE `user_id`=%s "
)
data = (question_num, user_id)
cursor.execute(query,data)
conn.commit() # commit transaction
conn.close()
except Exception as e:
exception = str(e)
def get_current_position_in_conversation(user_id):
"""
find in database current position in conversation between user and chatbot
using in bot_methods.py
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_num` FROM `conversations` WHERE `user_id`=%(user_id)s LIMIT 1"
cursor. execute(query, {'user_id': user_id})
result = cursor.fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identi
def get_question_from_DB(question_num):
"""
return question text from database
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_text` FROM `questions` WHERE `question_num`=%(num)s LIMIT 1"
cursor.execute(query, {'num': question_num})
result = cursor.fetchone()
if result is not None:
question_text = result[0]
else:
question_text = "None"
conn.close()
except Exception as e:
question_text = str(e)
return question_text cursor()
if question_num == '2':
query = (
"INSERT INTO `conversations`(`user_id`, `question_num`) "
"VALUES (%s, %s)"
)
data = (user_id, question_num)
else:
query = (
"UPDATE `conversations` "
"SET `question_num`=%s "
"WHERE `user_id`=%s "
)
data = (question_num, user_id)
cursor.execute(query,data)
conn.commit() # commit transaction
conn.close()
except Exception as e:
exception = str(e)
def get_current_position_in_conversation(user_id):
"""
find in database current position in conversation between user and chatbot
using in bot_methods.py
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_num` FROM `conversations` WHERE `user_id`=%(user_id)s LIMIT 1"
cursor.
cursor()
if question_num == '2':
query = (
"INSERT INTO `conversations`(`user_id`, `question_num`) "
"VALUES (%s, %s)"
)
data = (user_id, question_num)
else:
query = (
"UPDATE `conversations` "
"SET `question_num`=%s "
"WHERE `user_id`=%s "
)
data = (question_num, user_id)
cursor.execute(query,data)
conn.commit() # commit transaction
conn.close()
except Exception as e:
exception = str(e)
def get_current_position_in_conversation(user_id):
"""
find in database current position in conversation between user and chatbot
using in bot_methods.py
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_num` FROM `conversations` WHERE `user_id`=%(user_id)s LIMIT 1"
cursor. execute(query, {'user_id': user_id})
result = cursor.fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identi
def get_question_from_DB(question_num):
"""
return question text from database
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_text` FROM `questions` WHERE `question_num`=%(num)s LIMIT 1"
cursor.execute(query, {'num': question_num})
result = cursor.fetchone()
if result is not None:
question_text = result[0]
else:
question_text = "None"
conn.close()
except Exception as e:
question_text = str(e)
return question_text
execute(query, {'user_id': user_id})
result = cursor.fetchone()
if result is None:
identi = '0'
else:
identi = result[0]
conn.close()
except Exception as e:
identi = 'err'
return identi
def get_question_from_DB(question_num):
"""
return question text from database
"""
try:
conn = MySQLdb.connect(host=HOST, user=USER, passwd=PASSWORD,
db=DATABASE, charset='utf8', init_command='SET NAMES UTF8')
cursor = conn.cursor()
query = "SELECT `question_text` FROM `questions` WHERE `question_num`=%(num)s LIMIT 1"
cursor.execute(query, {'num': question_num})
result = cursor.fetchone()
if result is not None:
question_text = result[0]
else:
question_text = "None"
conn.close()
except Exception as e:
question_text = str(e)
return question_textТеперь для полноты картины приведу код скрипта, который резюмирует всю логику работы чат-бота.
скрипт views.py
«точка входа» для приёма сообщений пользователя и отправки ответов бота в чат
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import json
import threading # for async executing tasks with VK API
import vk # vk is library from VK
from django.views.decorators.csrf import csrf_exempt
from django.shortcuts import render
from django.http import HttpResponse
from bot_config import * # import token, confirmation_token and over constants from bot_config.py
from bot_methods import get_bot_answer
@csrf_exempt # exempt index() function from built-in Django protection
def index(request): # requested url
if (request.method == "POST"):
data = json.loads(request.body) # take POST request from auto-generated variable <request.body> in json format
if (data['secret'] == secret_key): # if json request contain secret key and it's equal my secret key
if (data['type'] == 'confirmation'): # if VK server request confirmation
"""
For confirmation my server (webhook) it must return
confirmation token, which issuing in administration web-panel
your public group in vk. com.
Using <content_type="text/plain"> in HttpResponse function allows you
response only plain text, without any format symbols.
Parameter <status=200> response to VK server as VK want.
"""
# confirmation_token from bot_config.py
return HttpResponse(confirmation_token,
content_type="text/plain",
status=200)
if (data['type'] == 'message_new'): # if VK server send a message
# t - is new thread to async execute answer_to_message()
t = threading.Thread(target=_answer_to_message, args=(data,))
t.start()
return HttpResponse('ok', content_type="text/plain", status=200)
else:
return HttpResponse('see you :)')
# send anser to user message
def _answer_to_message(data):
session = vk.Session()
api = vk.API(session, v=5.5)
user_id = data['object']['user_id']
user_message = data['object']['body']
# get bot answer
answer = get_bot_answer(user_id, user_message)
# token from bot_config. py
api.messages.send(access_token = token, user_id = str(user_id), message = answer) com.
Using <content_type="text/plain"> in HttpResponse function allows you
response only plain text, without any format symbols.
Parameter <status=200> response to VK server as VK want.
"""
# confirmation_token from bot_config.py
return HttpResponse(confirmation_token,
content_type="text/plain",
status=200)
if (data['type'] == 'message_new'): # if VK server send a message
# t - is new thread to async execute answer_to_message()
t = threading.Thread(target=_answer_to_message, args=(data,))
t.start()
return HttpResponse('ok', content_type="text/plain", status=200)
else:
return HttpResponse('see you :)')
# send anser to user message
def _answer_to_message(data):
session = vk.Session()
api = vk.API(session, v=5.5)
user_id = data['object']['user_id']
user_message = data['object']['body']
# get bot answer
answer = get_bot_answer(user_id, user_message)
# token from bot_config.
com.
Using <content_type="text/plain"> in HttpResponse function allows you
response only plain text, without any format symbols.
Parameter <status=200> response to VK server as VK want.
"""
# confirmation_token from bot_config.py
return HttpResponse(confirmation_token,
content_type="text/plain",
status=200)
if (data['type'] == 'message_new'): # if VK server send a message
# t - is new thread to async execute answer_to_message()
t = threading.Thread(target=_answer_to_message, args=(data,))
t.start()
return HttpResponse('ok', content_type="text/plain", status=200)
else:
return HttpResponse('see you :)')
# send anser to user message
def _answer_to_message(data):
session = vk.Session()
api = vk.API(session, v=5.5)
user_id = data['object']['user_id']
user_message = data['object']['body']
# get bot answer
answer = get_bot_answer(user_id, user_message)
# token from bot_config. py
api.messages.send(access_token = token, user_id = str(user_id), message = answer)
py
api.messages.send(access_token = token, user_id = str(user_id), message = answer)О том как устроена структура файлов приложения, его настройка описывал в подробностях в отдельной статье на Хабре.
Успехов!
Уверен, что для решения изложенной задачи существуют более элегантные решения и подходы. Несмотря на это надеюсь что изложенный материал найдёт своего читателя и будет полезен как в целом, так и в каких-то аспектах.
Желаю всем интересных проектов и успехов в их реализации!
Как добавить вкладку сообщество на ютуб канале и как добавлять запись в сообществе для обсуждения ?
12+
1 год и 8 месяцев назад
Виктор Христов562 подписчика
Когда на ютуб канале появится раздел «сообщество» ? сколько нужно набрать для этого подписчиков ? /описание ниже/
Мой канал на RUTUBE: https://rutube.ru/channel/23488286/
Популярные и полезные видео:
1. РЕГИСТРАЦИЯ И ВХОД В СБЕРБАНК ОНЛАЙН https://youtu.be/XDO1agzcTQY СБЕР
2. ЮMONEY ИДЕНТИФИКАЦИЯ КОШЕЛЬКА https://youtu.be/L-i25qXjv2I
3. РЕГИСТРАЦИЯ НА WEBMONEY: https://youtu.be/flmQf6yIYc8
4. КАК СОЗДАТЬ ЯНДЕКС ПОЧТУ: https://youtu.be/NtOTk1VhwRE
5. РЕГИСТРАЦИЯ КИВИ КОШЕЛЬКА: https://youtu.be/_XXabrsO_As
6. СОЗДАТЬ НОВУЮ ПОЧТУ МАЙЛ РУ: https://youtu.be/ekJhJkUl4GU
7. Как пользоваться плеером ютуб: https://youtu.be/f3_6yc_VRt4
8. ЮMONEY СОЗДАТЬ ЮМАНИ https://youtu.be/c-7lu1fgnQk
9. КАК СОЗДАТЬ СТРАНИЦУ ВКОНТАКТЕ: https://youtu.be/351sZ9SY_24
10. ГЕНЕРАТОР ПАРОЛЕЙ ОНЛАЙН: https://youtu.be/ZNnZQFftFN0
11. Ютуб как оспорить возрастные ограничения: https://youtu.be/u5VsP3fuSkY
12. Ютюб как заменить музыку в видео: https://youtu.be/rzJHJnym4dA
Какое количество активных подписчиков, нужно иметь, чтоб подключили раздел сообщество youtube или ранее, оно ещё называлось разделом «обсуждения». Чтоб появилась вкладка сообщество в 2021 году, нужно хоть примерно понимать, как сегодня работает и устроен канал ютуб. Правила youtube, как и его интерфейс и разделы канала изменяется, бывший раздел сообщество и информация о том как добавить вкладку сообщество уже не актуально, сегодня, актуальна информация, как добавить вкладку обсуждения на свой ютуб канал и как получить вкладку сообщество, вот это совсем другой вопрос.
ЮMONEY ИДЕНТИФИКАЦИЯ КОШЕЛЬКА https://youtu.be/L-i25qXjv2I
3. РЕГИСТРАЦИЯ НА WEBMONEY: https://youtu.be/flmQf6yIYc8
4. КАК СОЗДАТЬ ЯНДЕКС ПОЧТУ: https://youtu.be/NtOTk1VhwRE
5. РЕГИСТРАЦИЯ КИВИ КОШЕЛЬКА: https://youtu.be/_XXabrsO_As
6. СОЗДАТЬ НОВУЮ ПОЧТУ МАЙЛ РУ: https://youtu.be/ekJhJkUl4GU
7. Как пользоваться плеером ютуб: https://youtu.be/f3_6yc_VRt4
8. ЮMONEY СОЗДАТЬ ЮМАНИ https://youtu.be/c-7lu1fgnQk
9. КАК СОЗДАТЬ СТРАНИЦУ ВКОНТАКТЕ: https://youtu.be/351sZ9SY_24
10. ГЕНЕРАТОР ПАРОЛЕЙ ОНЛАЙН: https://youtu.be/ZNnZQFftFN0
11. Ютуб как оспорить возрастные ограничения: https://youtu.be/u5VsP3fuSkY
12. Ютюб как заменить музыку в видео: https://youtu.be/rzJHJnym4dA
Какое количество активных подписчиков, нужно иметь, чтоб подключили раздел сообщество youtube или ранее, оно ещё называлось разделом «обсуждения». Чтоб появилась вкладка сообщество в 2021 году, нужно хоть примерно понимать, как сегодня работает и устроен канал ютуб. Правила youtube, как и его интерфейс и разделы канала изменяется, бывший раздел сообщество и информация о том как добавить вкладку сообщество уже не актуально, сегодня, актуальна информация, как добавить вкладку обсуждения на свой ютуб канал и как получить вкладку сообщество, вот это совсем другой вопрос. Как раз на него в моём видео озвученном на русском языке, и есть ответ. Сколько нужно набрать подписчиков, на своём ютуб канале, чтоб получить на YouTube вкладку сообщество #YouTubeсообщество ? У меня есть ответ, я набрал одну тысячу 1000 подписчиков и ещё ждал примерно одну неделю, затем у меня появился раздел сообщества и в творческой студии ютуба #вкладкасообщество. Как добавить уже в этом 2021 году #вкладкусообщество на свой канал.
В этом видео, я объясняю не только как добавить вкладку сообщество на ютуб канале и как на своём канале проводить опросы на ютуб площадке. Просто расскажу как #какдобавитьвкладкуобсуждения и сделать опрос в ютубе в 2021 году. А как делать опросы в ютубе в других форматах, я тоже объясняю в своём видео с пошаговой инструкцией.
Как создать, настроить #YouTubeобсуждения и опубликовать youtube опрос, информация в этом видео, а так же как опубликовать в опросах #ютуб сообщества видео и фото формате, а как в сообществе youtube добавить в #опрос изображение, картинку или текст, я вам тоже покажу в моих видео.
Как раз на него в моём видео озвученном на русском языке, и есть ответ. Сколько нужно набрать подписчиков, на своём ютуб канале, чтоб получить на YouTube вкладку сообщество #YouTubeсообщество ? У меня есть ответ, я набрал одну тысячу 1000 подписчиков и ещё ждал примерно одну неделю, затем у меня появился раздел сообщества и в творческой студии ютуба #вкладкасообщество. Как добавить уже в этом 2021 году #вкладкусообщество на свой канал.
В этом видео, я объясняю не только как добавить вкладку сообщество на ютуб канале и как на своём канале проводить опросы на ютуб площадке. Просто расскажу как #какдобавитьвкладкуобсуждения и сделать опрос в ютубе в 2021 году. А как делать опросы в ютубе в других форматах, я тоже объясняю в своём видео с пошаговой инструкцией.
Как создать, настроить #YouTubeобсуждения и опубликовать youtube опрос, информация в этом видео, а так же как опубликовать в опросах #ютуб сообщества видео и фото формате, а как в сообществе youtube добавить в #опрос изображение, картинку или текст, я вам тоже покажу в моих видео. Так же, на YouTube в разделе сообщества и обсуждения, есть возможность добавить в сообществе гиф анимацию gif с текстом, ещё видео ролик и опрос. Кстати с такими великолепными инструментами, вам не сложно будет понять, как раскрутить канал на youtube не только в 2021 но и в другое время. В общем желаю успехов в продвижении на ютубе, понимания как набрать первую 1000 активных подписчиков, подключить сообщества и как грамотно вести свой ютуб канал !
Поддержать автора:
1. ЮMoney: https://yoomoney.ru/to/410012692573431
2. Qiwi: qiwi.com/n/VICTORHRISTOV
#ВикторХристов #ИнтернетПолезный #Обучающиеуроки #ютуб #Видеоуроки #YouTube #сообществаютуб #Ютуб2021 #YouTube2021
Так же, на YouTube в разделе сообщества и обсуждения, есть возможность добавить в сообществе гиф анимацию gif с текстом, ещё видео ролик и опрос. Кстати с такими великолепными инструментами, вам не сложно будет понять, как раскрутить канал на youtube не только в 2021 но и в другое время. В общем желаю успехов в продвижении на ютубе, понимания как набрать первую 1000 активных подписчиков, подключить сообщества и как грамотно вести свой ютуб канал !
Поддержать автора:
1. ЮMoney: https://yoomoney.ru/to/410012692573431
2. Qiwi: qiwi.com/n/VICTORHRISTOV
#ВикторХристов #ИнтернетПолезный #Обучающиеуроки #ютуб #Видеоуроки #YouTube #сообществаютуб #Ютуб2021 #YouTube2021
Vk Расширение опроса для Joomla
Описание приложения
С помощью виджета опросов вы можете всего за 5 минут создать опрос для посетителей вашего сайта на любую тему. Это позволит вашим посетителям одним щелчком мыши высказать свое мнение и, что не менее важно, моментально поделиться им со своими друзьями, оставив ссылку на него в своем профиле ВКонтакте.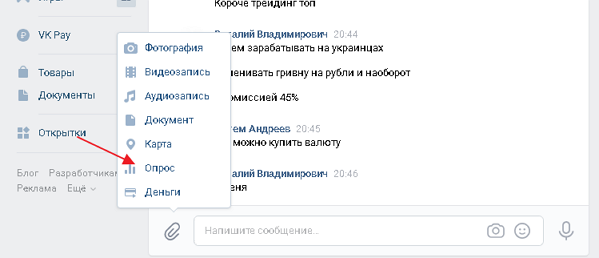 Пользователю не нужно будет вводить какую-либо информацию, поэтому статья с опросом может распространиться максимально быстро.
Пользователю не нужно будет вводить какую-либо информацию, поэтому статья с опросом может распространиться максимально быстро.
Цена
Начиная с 0 долларов США в месяц.
Продление Ultimate Hours Hours
By Common Ninja
Попробуйте бесплатно!
Приложение Info
Рейтинг
Рецензенты
1 Обзоры
TAGS
Опросы
Разработаны Ext-Joom.com
Общие расширения Ninja
. набор расширений, совместимых с Joomla, и легко встраивайте их в любой веб-сайт, блог, платформу электронной коммерции или конструктор сайтов.
Быстро и просто
Легко найти лучшие расширения Joomla для вас
Лучшие расширения и виджеты Joomla уже не за горами! Исследуйте каталог Common Ninja и найдите лучшие ускорители сайтов Joomla — плагины, расширения, виджеты и многое другое! Какие инструменты продвижения сайта нужны дизайнерам? Просмотрите весь наш каталог виджетов и плагинов сегодня, чтобы узнать!
Галерея
Расширения галереи для Joomla
SEO
Расширения SEO для Joomla
Contact
Contact extensions for Joomla
Forms
Forms extensions for Joomla
Social Feed
Social Feed extensions for Joomla
Social Sharing
Social Sharing extensions for Joomla
Events Calendar
Events Calendar extensions for Joomla
Slideshow
Расширения слайд-шоу для Joomla
Analytics
Расширения Analytics для Joomla
Отзывы
Reviews extensions for Joomla
Comments
Comments extensions for Joomla
Portfolio
Portfolio extensions for Joomla
Maps
Maps extensions for Joomla
Security
Security extensions for Joomla
Translation
Translation extensions for Joomla
Ads
Расширения Ads для Joomla
Video Player
Расширения Video Player для Joomla
Music player
Music player extensions for Joomla
Backup
Backup extensions for Joomla
Privacy
Privacy extensions for Joomla
Optimize
Optimize extensions for Joomla
Chat
Chat extensions for Joomla
Countdown
Расширения обратного отсчета для Joomla
Маркетинг по электронной почте
Расширения для маркетинга по электронной почте для Joomla
Вкладки
Расширения для вкладок для Joomla
Membership
Membership extensions for Joomla
popup
popup extensions for Joomla
SiteMap
SiteMap extensions for Joomla
Payment
Payment extensions for Joomla
Coming soon
Coming soon extensions for Joomla
Ecommerce
Расширения электронной коммерции для Joomla
Отзывы
Расширения отзывов для Joomla
Откройте для себя плагины и приложения для других платформ
Найдите больше приложений для вашей платформы
Другие расширения
Найдите больше
Классные расширения
Чистая приведенная стоимость Модель: VK-2809 — Отчеты об исследованиях рынка и консультации
- Обзор отчета
- Ключевые игроки
- Вопросы-Ответы
- Методология
Обзор
Оценка стоимости лекарств — сложная практика, требующая глубоких знаний о самом лекарстве, рынке в настоящее время и в будущем, знания о притоке и оттоке денежных средств и потенциальных показателях успеха для каждого этапа лечения наркотиками.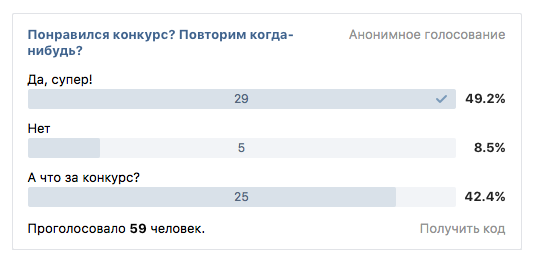 разработка. Компания GlobalData выполнила всю эту работу за вас, используя свою базу данных Gold Standard Drug Intelligence для создания высокоценных моделей чистой приведенной стоимости для закупок по каждому лекарственному средству.
разработка. Компания GlobalData выполнила всю эту работу за вас, используя свою базу данных Gold Standard Drug Intelligence для создания высокоценных моделей чистой приведенной стоимости для закупок по каждому лекарственному средству.
Модель операционной прибыли препарата
VK-2809 Сведения о препарате
VK-2809 (MB-07811) разрабатывается для лечения гиперхолестеринемии, неалкогольного жирового стеатогепатита (НАСГ), фиброза печени и неалкогольного фиброза болезнь (НАЖБП). Препарат-кандидат выпускается в виде капсул и вводится перорально. Он нацелен на бета-рецептор гормона щитовидной железы (TR-бета). Это пролекарство MB-07344. Препарат-кандидат разработан на основе технологической платформы HepDirect для воздействия на печень. Он также разрабатывался для лечения болезни накопления гликогена типа 1а и Х-сцепленной адренолейкодистрофии.
Покрытие отчета
GlobalData учитывает такие факторы, как патентное право, известные и планируемые процессы утверждения регулирующими органами, денежные потоки, потенциальные применимые пациенты, маржинальность лекарств, расходы компании и расчетные цены. Сочетание этих точек данных с анализом мирового класса GlobalData создает ценные модели, которые компании могут использовать, чтобы помочь в процессах оценки для каждого препарата или компании.
Сочетание этих точек данных с анализом мирового класса GlobalData создает ценные модели, которые компании могут использовать, чтобы помочь в процессах оценки для каждого препарата или компании.
| Быстрый просмотр — VK-2809Данные чистой приведенной стоимости | |
| Название лекарства | · ВК-2809 |
| Административный путь | · Оральный |
| Терапевтические зоны | · Желудочно-кишечный тракт · Нарушения обмена веществ · Заболевания опорно-двигательного аппарата · Генетические расстройства |
| Ключевые производители | · Viking Therapeutics Inc (Metabasis Therapeutics Inc) |
| Статус разработки лекарств | · Этап II |
Причины для покупки
- Лучше понять количественную ценность конкретного лекарства
- Создание или поддержка внутренних моделей NPV для повышения точности
- Понимание ожидаемой прибыли от препарата с учетом прогнозов доходов и затрат с использованием общедоступных и частных наборов данных.

Ключевые игроки
Viking Therapeutics Inc
Часто задаваемые вопросы
Модель NPV GlobalData — это модель премиум-класса, предоставляющая полностью интерактивный инструмент прогнозирования и оценки, основанный на оценках Analyst Consensus, позволяющий пользователям анализировать и настраивать оценки фармацевтических активов, включая лекарства или сегменты. Инструмент предоставляет 17-летние прогнозы лекарств от компаний с прогнозными данными о продажах в фармацевтической отрасли, включая признанные мировые фирмы и новые биотехнологические компании, что позволяет получить доступ к критически важной информации для облегчения принятия стратегических решений в отношении фармацевтических активов.
Модель NPV Модель включает модель прогнозируемого дохода, за которой следуют запатентованная модель истечения срока действия патента, модель операционной прибыли, чистая прибыль (применяется налоговая ставка) и дисконтированный денежный поток (применяются ставки дисконтирования) для получения чистой приведенной стоимости (NPV). для выбранного фармацевтического актива
для выбранного фармацевтического актива
- Все продажи лекарств и прогнозы в рамках модели NPV рассчитываются в моделях, основанных на нашей собственной компании. В этих моделях прогнозы Analyst Consensus строятся с использованием отчетов брокеров для конкретных компаний для создания прогнозов продаж для каждого препарата и сегмента.
- Продажи и прогнозы не привязаны к показаниям, если препараты одобрены или находятся в разработке для нескольких показаний. См. отчеты Анализа заболеваний GlobalData для получения прогнозов продаж по конкретным показаниям.
- NPV с поправкой на риск используют LoA GlobalData и PTSR для индикации на самой высокой стадии разработки. Пожалуйста, обратитесь к методологии вероятности одобрения для получения более подробной информации об этом контенте.
Методология
- Модель NPV включает в себя 7-летний консенсусный прогноз аналитиков, полученный с помощью инструмента GlobalData Sales and Forecast, и алгоритм динамического трехлетнего исторического средневзвешенного прогноза, прогнозирующий доходы на следующие 10 лет, что дает общий 17-летний прогноз. диапазон для выбранного актива.
- Прогнозы полностью настраиваются с использованием как годовой корректировки темпов роста, так и долгосрочного демпфера темпов роста, который влияет на траекторию выбранного актива. Прогнозируемая дата окончания может быть изменена, чтобы сократить прогнозируемый период актива, если у компании есть ограниченные по времени права интеллектуальной собственности.
- В модели срока годности сроки годности препаратов заранее определены по регионам. Эти даты истечения срока годности для продаваемых препаратов получены из базы данных GlobalData Regulatory Milestones, а для препаратов, находящихся в стадии разработки, используется запатентованная методология GD. К каждому потоку доходов можно применять несколько коэффициентов эрозии, предлагая широкий спектр возможных сценариев.
- Чтобы получить чистую приведенную стоимость выбранного актива, необходимо определить прибыльность препарата путем исключения его затрат. Модель чистой приведенной стоимости имеет предварительно установленные для конкретной компании маржи для себестоимости проданных товаров (COGS), торговых, общих и административных (S, G&A) и других расходов с использованием последних финансовых результатов для этой компании и собственной методологии GlobalData. GlobalData обновляет эти данные о марже ежегодно после завершения финансового года компании.
- После вычета затрат на Лекарство, чтобы получить чистую приведенную стоимость для выбранного актива, необходимо определить чистую прибыль Лекарства, исключив его налоговые расходы на прибыль. Модель NPV имеет предустановленную эффективную налоговую ставку (ETR) для конкретной компании, используя последние финансовые результаты для этой компании. GlobalData обновляет эту налоговую ставку ежегодно после завершения финансового года компании.
- После вычета затрат на лекарство и налогов, чтобы получить чистую приведенную стоимость для выбранного актива, необходимо определить дисконтированный денежный поток лекарства (DCF), используя средневзвешенную стоимость капитала компании (WACC) для учета времени. значение денег. WACC — это процентная ставка, которую компания, как ожидается, будет платить в среднем всем держателям своих ценных бумаг для финансирования своих активов. Ее также называют ставкой дисконтирования, которая используется для определения приведенной стоимости будущих денежных потоков. Модель NPV имеет предварительно установленную ставку WACC, используя последние финансовые результаты для этой компании. GlobalData обновляет эту ставку WAAC ежегодно после завершения 9 финансового года компании.0185
- NPV с поправкой на риск включает вероятность того, что лекарство не будет одобрено и, следовательно, не принесет никаких доходов и не понесет затрат, связанных с производством коммерческого продукта (COGS), расходов на продажу (SG&A) и других расходов, связанных с продаваемым лекарством. Таким образом, процент вероятности одобрения умножается на доход от лекарств и все расходы, связанные с продажей.
 диапазон для выбранного актива.
диапазон для выбранного актива. GlobalData обновляет эти данные о марже ежегодно после завершения финансового года компании.
GlobalData обновляет эти данные о марже ежегодно после завершения финансового года компании. Модель NPV имеет предварительно установленную ставку WACC, используя последние финансовые результаты для этой компании. GlobalData обновляет эту ставку WAAC ежегодно после завершения 9 финансового года компании.0185
Модель NPV имеет предварительно установленную ставку WACC, используя последние финансовые результаты для этой компании. GlobalData обновляет эту ставку WAAC ежегодно после завершения 9 финансового года компании.0185купить сейчас
Добавить в корзину
Валюта долларов США
Одинокий
500 долларов
Может использоваться только индивидуальным покупателем
Самый популярныйМногопользовательские
750 долларов
Может совместно использоваться неограниченным количеством пользователей в пределах одного корпоративного местоположения, например. региональный офис
региональный офис
Предприятие
1000 долларов
Может совместно использоваться по всему миру неограниченным количеством пользователей внутри закупочной корпорации, например. все сотрудники одной компании
[email protected]
Тел.: +44 (0) 20 7947 2960
Требование каждого клиента уникально. Мы понимаем это и можем настроить отчет на основе ваших конкретных требований к исследованиям, касающимся понимания рынка, инноваций, стратегии и планирования, а также конкурентной разведки. Вы также можете приобрести отдельные разделы отчета или запросить отчет по конкретной стране.
Личная информация и информация о транзакциях защищены от несанкционированного использования.
«Платформа GlobalData — наш основной инструмент для разведывательных служб. GlobalData предоставляет простой способ доступа к комплексным аналитическим данным по нескольким секторам, что, по сути, делает его универсальной аналитической платформой для проведения тендеров и обращения к клиентам.
GlobalData очень ориентирован на клиента, с высоким уровнем персонализированных услуг, которые приносят пользу повседневному использованию. Высокодетализированные аналитические и прогнозные отчеты по проектам могут использоваться в различных отделах и областях рабочих процессов, от оперативного до стратегического уровня, и часто помогают принимать стратегические решения. Решения GlobalData Analytics и визуализации внесли положительный вклад в подготовку управленческих презентаций и стратегических документов».
Менеджер по бизнес-аналитике и маркетингу, SAL Heavy Lift «COVID-19 оказал значительное влияние на наш бизнес, а информация о COVID-19 от GlobalData помогла нам принять более взвешенные стратегические решения. Эти два основных момента очень помогли понять прогнозы на будущее в отношении наших бизнес-подразделений. Мы также используем базу данных проектов для поиска новых проектов для Liebherr-Werk, чтобы использовать их в качестве дополнительного источника для продвижения нового бизнеса».