Поиск целевой аудитории ВК: поиск меломанов
Время на прочтение: 5 минут(ы)Фанатам музыкантов помимо концертов можно предлагать развлекательные услуги или мерч с символикой их кумира. Как найти таких пользователей в ВК? Для этого нам поможет поиск исполнителей и композиций.
TargetHunter может искать как по всему ВК определенных исполнителей и композиции Поиск > Меломаны (https://vk.targethunter.ru/search/music), так и среди заданной входной базы Сбор > Меломаны (https://vk.targethunter.ru/take/music).
Как собрать меломанов, у которых есть определенный исполнитель в трек-листе
ВАЖНО: Парсинг по аудио в ВК «белыми способами» возможен только для аудиозаписей, которые были добавлены в ВК до декабря 2016 года включительно. Это техническое ограничение ВК, которое парсер TargetHunter не обходит.
Лайфхак: Прежде, чем приступать к поиску меломанов, узнайте годы творчества исполнителя (поможет поиск на просторах интернета).
Если альбомы выходили вплоть до декабря 2016 года, смело пользуйтесь поиском/сбором меломанов.
Если музыканты стали творить в 2017 году и позднее, тогда сразу переходите к разделу Как собрать меломанов в ВК после 2017 года
А мы собираем меломанов, в этом нам поможет инструмент Поиск > Меломаны (https://vk.targethunter.ru/search/music)
Во входных данных вводим исполнителя и название композиции, например, Пикник — Инкогнито. Период, за который была добавлена композиция, оставляем пустым или в конце периода указываем декабрь 2016 года.
Так мы найдем пользователей, у кого в трек-листе есть эта композиция.
Если нам нужно найти людей, кто в принципе фанатеет от Пикника, тогда во входных данных мы оставляем только исполнителя (Пикник). В разделе Количество аудиозаписей можем указать ОТ 3 (так мы отсечем тех, кто случайно добавил какую-нибудь композицию). Снова помним о периоде добавления аудио (оставляем пустым или указываем окончание — декабрь 2016).
Полученные данные пользователей можем сохранять в виде ссылок, ID, загружать в облачный список или сразу в рекламный кабинет
Если у нас есть определенная база пользователей, например, ваши клиенты, то мы можем узнать, есть ли среди них фанаты заданных исполнителей. Зачем это может понадобиться?
Возможно, вы разыграете среди своих клиентов мерч с символикой их любимого исполнителя или подарите что-то связанное с их кумиром. Тут все зависит от вас. А мы разберемся, как найти меломанов в имеющейся базе.
Заходим в инструмент Сбор > Меломаны (https://vk.targethunter.ru/take/music). Во входных данных загружаем уже имеющуюся базу, даем ссылки на сообщества или выбираем из результатов парсинга. Возьмем для примера сообщество TargetHunter.
Тут важно помнить: чем больше входная база, тем дольше будет выполняться задача.
В поле Ключевая фраза введем Пикник — Инкогнито. Период добавления композиции оставляем пустым.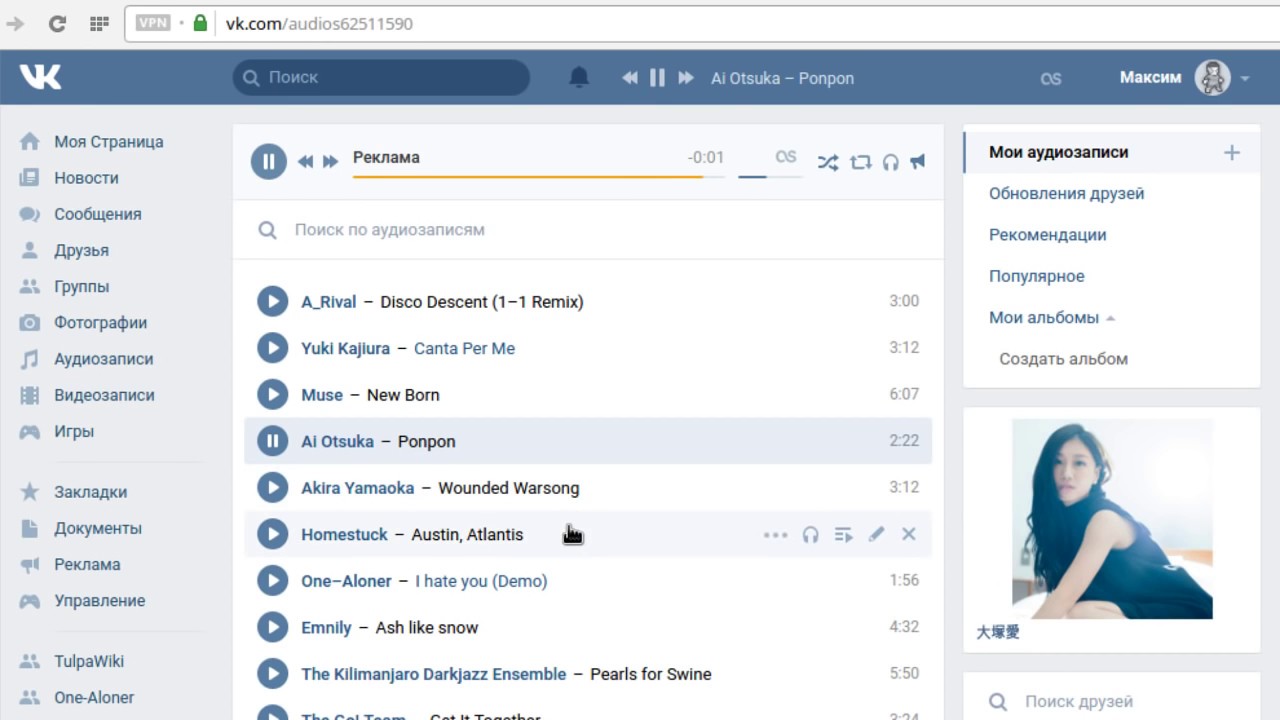
В результате мы найдем подписчиков сообщества TargetHunter, у которых в аудиозаписях есть трек группы Пикник.
Как собрать меломанов в ВК после 2017 года
А как же найти фанатов музыкантов, творчество которых стало популярно в 2017 году и позднее? Это можно сделать через поиск композиций в постах или через активности в видеозаписях.
Поиск композиций в постах
Идем в инструмент Поиск > Новости (https://vk.targethunter.ru/search/news).
Задаем ключевую фразу, например, Тима Белорусских, отмечаем точное вхождение. Обязательно указываем период поиска (максимально допустимый период 1 год, поэтому если нужен поиск за несколько лет, разбиваем его по 1 году). Тип сообщений — только посты. Вложения — только с вложениями. Кто автор — пользователи.
Открываем полученные результаты. У нас получилось больше 90 тыс пользователей, которые с 1 января 2020 года и до середины июля добавили себе на стену пост с аудиозаписями Тимы Белорусских.
Проверим? Нажмите на любую ссылку с именем пользователя
Вот что мы увидим: пост с нужной нам композицией, бинго!
TargetHunter отлично справился с заданием!
Поиск композиций в видео
Любимые композиции можно сохранять в формате видео. Разбираемся, как найти меломанов этим способом.
Заходим в инструмент Поиск > Видеозаписи (https://vk.targethunter.ru/search/video) Вводим название исполнителя, например, Тима Белорусских, и запускаем задачу.
В полученных результатах проведем фильтрацию: добавим минус-слова (например, караоке, минус, аккорды, Tik Tok), применим фильтрацию. Теперь мы можем сохранить или выгрузить в РК пользователей, у которых добавлены видеозаписи с нужным нам исполнителем.
Получилась довольно горячая ЦА.
Можно ли найти еще кого-то? Конечно, теперь мы можем собрать активности (лайки и комментарии) с найденных видеозаписей.
Для этого нам пригодится инструмент Активности > По объекту > Видеозаписи (https://vk. targethunter.ru/track/object/video)
targethunter.ru/track/object/video)
Во входных данных выбираем задачу, где мы находили видео с предыдущего шага. Отмечаем активности (лайки, комментарии) и запускаем парсер.
Таким образом мы собрали менее горячую ЦА, но, как минимум, она знакома с творчеством исполнителя и проявляет к нему интерес.
Поиск композиций через профили и группы исполнителей
Можно ли как-то еще собрать фанатов молодых исполнителей?
И снова ответ — да. Музыканты это публичные персоны, которые, как правило, прокачивают свой личный профиль. Можно зайти с этой стороны: найти личную страницу кумира (только предварительно убедиться, что это именно нужный исполнитель, обычно это верифицированный профиль) и спарсить его друзей и подписчиков.
Поиск > Пользователи > Ключевая фраза (ищем по Имени+Фамилии) (https://vk.targethunter.ru/search/users/query) поможет найти страницу кумира.
Сбор > Друзья (https://vk.targethunter.ru/take/friends) найдет нам друзей и подписчиков, среди которых с большой вероятностью будут фанаты исполнителя.
С личными профилями кумиров разобрались. Но мы знаем, что они еще ведут свои паблики (обычно тоже верифицированы) и проводят концерты, пусть даже теперь и в онлайн-формате. Для концертов тоже организуются группы в ВК.
Итак, еще один способ поиска меломанов, найти сообщества и собрать участников.
Поиск > Сообщества > Ключевая фраза (https://vk.targethunter.ru/search/groups/query) найдет нам сообщество и мероприятия исполнителя.
Сбор > Участники (https://vk.targethunter.ru/take/members) выдаст нам поклонников творчества.
Лайфхак: Участников и возможных участников лучше собирать отдельно, т.к. это разная по степени теплоты ЦА.
Как использовать базу меломанов
Вот вам несколько идей:
1. Пригласить на мероприятие фанатов своего кумира.
2. Предложить мерч с символикой любимых исполнителей.
3. Найти фанатов музыкантов, которые похожи по стилю на другого и предложить им послушать творчество нового исполнителя.
4. Если вы нашли пользователей, которые с удовольствием слушают аудиокниги, можете предложить им услуги, связанные с темой книг, которые они слушают.
5. У вас получилась база пользователей, у которых много колыбельных? Что ж, это мамочки, предлагайте им все, что связано с детьми или для них самих.
6. Нашли пользователей, у кого в трек-листах подборки для пробежек? Вот вам и ЦА для продажи товаров и услуг для фитнеса (одежда, обувь, спортпит, тренажеры или персональные тренировки).
7. Получилась база с подборкой аудио на иностранных языках? Предлагайте им курсы, мероприятия или даже поездку в страну изучаемого языка.
Список идей можно продолжать бесконечно. Главное — найти нужную вам ЦА, понять, что ей интересно и сделать предложение, от которого мало кто сможет отказаться.
В TargetHunter можно бесплатно воспользоваться практически любым инструментом в демонстрационных целях и разобраться на практике, как собрать любителей конкретной музыки ВК.
Удачной охоты!
Автор: Лариса Крутикова
Авторизуйтесь через ВК и введите промокод BLOGTH для новых пользователей – 2 дня тарифа «Автоматизация» бесплатно, плюс месяц в подарок при оплате любого тарифа минимум на месяц.
Архитектура и алгоритмы индексации аудиозаписей ВКонтакте / Хабр
Расскажем о том, как устроен поиск похожих треков среди всех аудиозаписей ВКонтакте.
Зачем всё это надо?
У нас действительно много музыки. Много — это больше 400 миллионов треков, которые весят примерно 4 ПБ. Если загрузить всю музыку из ВКонтакте на 64 ГБ айфоны, и положить их друг на друга, получится башня выше Эйфелевой. Каждый день в эту стопку нужно добавлять еще 25 айфонов — или 150 тысяч новых аудиозаписей объёмом 1.5 ТБ.Конечно, далеко не все эти файлы уникальны. У каждого аудио есть данные об исполнителе и названии (опционально — текст и жанр), которые пользователь заполняет при загрузке песни на сайт. Премодерации нет. В результате мы получаем одинаковые песни под разными названиями, ремиксы, концертные и студийные записи одних и тех же композиций, и, конечно, совсем неверно названные треки.
Если научиться достаточно точно находить одинаковые (или очень похожие) аудиозаписи, можно применять это с пользой, например:
- не дублировать в поиске один трек под разными названиями;
- предлагать прослушать любимую композицию в более высоком качестве;
- добавлять обложки и текст ко всем вариантам песни;
- усовершенствовать механизм рекомендаций;
- улучшить работу с жалобами владельцев контента.
Пожалуй, первое, что приходит в голову — это ID3-теги. У каждого mp3-файла есть набор метаданных, и можно принимать во внимание эту информацию как более приоритетную, чем то, что пользователь указал в интерфейсе сайта при загрузке трека. Это самое простое решение. И оно не слишком хорошее — теги можно редактировать вручную, и они совсем не обязательно соответствуют содержимому.
Итак, вся ассоциированная с файлом информация, которая у нас есть, человекозависима и может быть недостоверна. Значит, нужно приниматься за сам файл.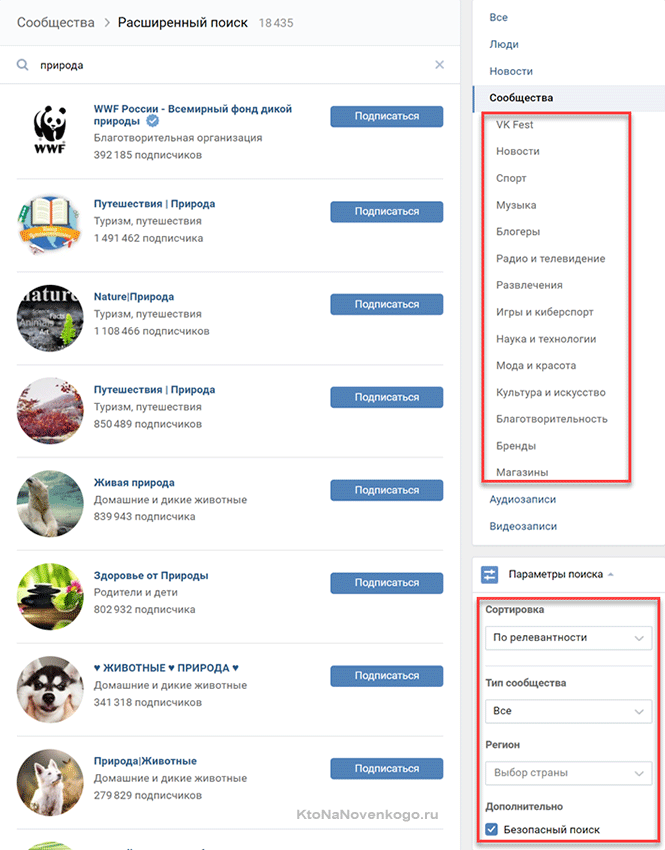
Мы поставили перед собой задачу определять треки, которые одинаковы или очень похожи на слух, анализируя при этом только содержимое файла.
Кажется, кто-то уже это делал?
Поиск похожих аудио — довольно популярная история. Ставшее уже классическим решение используется всеми подряд, от Shazam’а до биологов, изучающих вой волков. Оно основано на акустических отпечатках.Акустический отпечаток — это представление аудиосигнала в виде набора значений, описывающих его физические свойства.
Проще говоря, отпечаток содержит в себе некую информацию о звуке, причем эта информация компактна — её объём сильно меньше, чем у исходного файла. Композиции, похожие на слух, будут иметь одинаковые отпечатки, и наоборот, у отличных по звучанию песен отпечатки не будут совпадать.
Мы начали с попытки использовать одно из готовых решений на C++ для генерации акустических отпечатков. Прикрутили к нему свой поиск, протестировали на реальных файлах и поняли, что для значительной части выборки результаты плохие. Один и тот же трек успешно «маскируется» эквалайзером, добавлением фонового шума или джинглов, склейкой с фрагментом другого трека.
Один и тот же трек успешно «маскируется» эквалайзером, добавлением фонового шума или джинглов, склейкой с фрагментом другого трека.
Вот как это выглядит (в сравнении с исходным треком):
Лайв-исполнение
Эхо
Ремикс
Во всех этих случаях человек легко поймёт, что это одна и та же композиция. У нас много файлов с подобными искажениями, и важно уметь получать хороший результат и на них. Стало ясно, что нам нужна собственная реализация генератора отпечатков.
Генерация отпечатка
Что ж, у нас есть аудиозапись в виде mp3-файла. Как превратить его в компактный отпечаток?Нужно начать с декодирования аудиосигнала, который в этот файл упакован. MP3 представляет собой цепочку фреймов (блоков), в которых содержатся закодированные данные об аудио в формате PCM (pulse code modulation) — это несжатый цифровой звук.
Чтобы получить PCM из MP3, мы использовали библиотеку libmad на С и собственную обертку для неё на Go. Позднее сделали выбор в пользу прямого использования ffmpeg.
Так или иначе, в результате мы имеем аудиосигнал в виде массива значений, описывающих зависимость амплитуды от времени. Можно представить его в виде такого графика:
Аудиосигнал
Это тот звук, который слышит наше ухо. Человек может воспринимать его как одно целое, но на самом деле звуковая волна представляет собой комбинацию множества элементарных волн разной частоты. Что-то вроде аккорда, состоящего из нескольких нот.
Мы хотим знать, какие частоты есть в нашем сигнале, а особенно — какие из них наиболее «характерны» для него. Прибегнем к каноническому способу получения таких данных — быстрое преобразование Фурье (FFT).
Подробное описание математического аппарата выходит за рамки этой статьи. Узнать больше о применении преобразования Фурье в области цифровой обработки сигналов Вы можете, например, в этой публикации.
В нашей реализации используется пакет GO-DSP (Digital Signal Processing), а именно github.com/mjibson/go-dsp/fft — собственно FFT и github. com/mjibson/go-dsp/window — для оконной функции Ханна.
com/mjibson/go-dsp/window — для оконной функции Ханна.
Спектрограмма — это визуальное представление всех трёх акустических измерений: времени, частоты и амплитуды сигнала. Она выражает значение амплитуды для определённого значения частоты в определённый момент времени.
Например:
Спектрограмма эталонной дорожки
По оси X отсчитывается время, ось Y представляет частоту, а значение амплитуды обозначается интенсивностью цвета пикселя. На иллюстрации приведена спектрограмма для «эталонного» сигнала с равномерно повышающейся частотой. Для обычной песни спектрограмма выглядит, например так:
Спектрограмма обычной дорожки
Это довольно подробный «портрет» аудиодорожки, из которого можно (с определённой аппроксимацией) восстановить исходный трек. С точки зрения ресурсов, хранить такой «портрет» полностью невыгодно. В нашем случае это потребовало бы 10 ПБ памяти — в два с половиной раза больше, чем весят сами аудиозаписи.
Мы выбираем ключевые точки (пики) на спектрограмме, основываясь на интенсивности спектра, чтобы сохранять только самые характерные для этого трека значения. В результате объём данных сокращается примерно в 200 раз.
Ключевые значения на спектрограмме
Осталось собрать эти данные в удобную форму. Каждый пик однозначно определяется двумя числами — значениями частоты и времени. Добавив все пики для трека в один массив, получим искомый акустический отпечаток.
Сравнение отпечатков
Допустим, мы проделали всё вышеописанное для двух условных треков, и теперь у нас есть их отпечатки. Вернёмся к исходной задаче — сравнить эти треки с помощью отпечатков и выяснить, похожи (одинаковы) они или нет.Каждый отпечаток — массив значений. Попробуем сравнивать их поэлементно, сдвигая треки по временной шкале относительно друг друга (сдвиг нужен, например, чтобы учесть тишину в начале или в конце трека). На одних смещениях совпадений в отпечатках будет больше, на других — меньше.
Треки с общим фрагментом и разные треки
Похоже на правду. Для треков с общим фрагментом этот фрагмент нашелся и выглядит как всплеск числа совпадений на определённом временном смещении. Результат сравнения — «коэффициент сходства», который зависит от числа совпадений с учетом смещения.
Программная реализация Go библиотеки для генерации и сравнения отпечатков доступна на GitHub. Вы можете увидеть графики и результаты для собственных примеров.
Теперь надо встроить всё это в нашу инфраструктуру и посмотреть, что получится.
Архитектура
Движки генерации отпечатков и индексирования/поиска в архитектуре ВК
Движок для генерации отпечатков работает на каждом сервере для загрузки аудио (их сейчас около 1000). Он принимает на вход mp3-файл, обрабатывает его (декодирование, FFT, выделение пиков спектра) и выдаёт акустический отпечаток этого аудио.
Нагрузка распараллеливается на уровне файлов — каждый трек обрабатывается в отдельной горутине. Для средней аудиозаписи длительностью 5-7 минут обработка занимает 2-4 секунды. Время обработки линейно растет с увеличением длительности аудио.
Для средней аудиозаписи длительностью 5-7 минут обработка занимает 2-4 секунды. Время обработки линейно растет с увеличением длительности аудио.
Акустические отпечатки всех треков, хоть и с некоторой потерей точности, займут около 20 ТБ памяти. Весь этот объём данных нужно где-то хранить и уметь быстро к нему обращаться, чтобы что-нибудь в нём найти. Эту задачу решает отдельный движок индексирования и поиска.
Он хранит данные об отпечатках в виде обратных (инвертированных) индексов:
Обратный индекс
Чтобы добиться быстродействия и сэкономить на памяти, мы используем преимущества структуры самого отпечатка. Отпечаток — это массив, и мы можем рассматривать отдельные его элементы (хэши), которые, как Вы помните, соответствуют пикам спектра.
Вместо того, чтобы хранить соответствие «трек» → «отпечаток», мы разбиваем каждый отпечаток на хэши и храним соответствие «хэш» → «список треков, в отпечатках которых он есть». Индекс прореженный, и 20 ТБ отпечатков в виде индекса займут около 100 ГБ.
Как это работает на практике? В движок поиска приходит запрос с аудиозаписью. Нужно найти похожие на неё треки. Из хранилища скачивается отпечаток для этого аудио. В индексе выбираются строчки, содержащие хэши этого отпечатка. Из соответствующих строк выбираются часто встречающиеся треки, для них скачиваются отпечатки из хранилища. Эти отпечатки сравниваются с отпечатком исходного файла. В результате возвращаются самые похожие треки с соответствующими совпавшими фрагментами и условным «коэффициентом сходства» для этих фрагментов.
Движок индексирования и поиска работает на 32 машинах, написан на чистом Go. Здесь по максимуму используются горутины, пулы внутренних воркеров, параллелится работа с сетью и глобальным индексом.
Итак, вся логика готова. Давайте соберем отпечатки всей музыки, проиндексируем и начнём с ними работать. Кстати, сколько времени это займёт?
Мы запустили индексацию, подождали пару дней и оценили сроки. Как оказалось, результат будет примерно через год. Такой срок неприемлем — нужно что-то менять.
Такой срок неприемлем — нужно что-то менять.
Внедрение sync.Pool везде, где только можно, выкроило 2 месяца. Новый срок: 10 месяцев. Это всё ещё слишком долго. Надо лучше.
Оптимизируем тип данных — выбор треков по индексу был реализован слиянием массива. Использование container/heap вместо массива обещает сэкономить половину времени. Получаем 6 месяцев выполнения. Может, можно ещё лучше?
Затачиваем container/heap под использование нашего типа данных вместо стандартных интерфейсов, и выигрываем ещё месяц времени. Но нам и этого мало (то есть много).
Правим stdlib, сделав собственную реализацию для container/heap — ещё минус 2 месяца, итого остаётся 3. В четыре раза меньше первых оценок!
И, наконец, обновление версии Go с 1.5 на 1.6.2 привело нас к финальному результату. 2.5 месяца потребовалось в итоге на создание индекса.
Что получилось?
Продакшн-тестирование выявило несколько кейсов, которые мы не учли изначально. Например, копия трека с немного изменённой скоростью воспроизведения:Ускоренная дорожка
Для слушателя это практически одно и то же, небольшое ускорение не воспринимается как существенное отличие. К сожалению, наш алгоритм сравнения отпечатков считал такие треки совсем разными.
К сожалению, наш алгоритм сравнения отпечатков считал такие треки совсем разными.
Чтобы это исправить, мы добавили немного преобработки. Заключается она в поиске наибольшей общей подпоследовательности (Longest Common Subsequence) в двух отпечатках. Ведь амплитуда и частота не меняются, меняется в этом случае только соответствующее значение времени, а общий порядок следования точек друг за другом сохраняется.
LCS
Нахождение LCS позволяет определить коэффициент «сжатия» или «растяжения» сигнала по шкале времени. Дальше дело за малым — сравниваем отпечатки как обычно, применив к одному из них найденный коэффициент.
Применение алгоритма поиска LCS значительно улучшило результаты — многие треки, которые прежде не находились по отпечатку, стали успешно обрабатываться.
Еще один интересный случай — совпадение по фрагментам. Например, минус какой-то популярной песни с записанным поверх него любительским вокалом.
Совпадения фрагментов треков
Мы раскладываем результат сравнения по времени и смотрим на число совпадений для каждой секунды трека. На картинке выше как раз пример любительской записи поверх минуса в сравнении с исходным треком этого минуса. Интервалы с отсутствием совпадений — вокал, пики совпадений — молчание (т.е. чистый минус, который аналогичен исходной дорожке). В такой ситуации мы считаем число фрагментов с совпадениями и вычисляем условный «коэффициент сходства» по числу самих совпадений.
На картинке выше как раз пример любительской записи поверх минуса в сравнении с исходным треком этого минуса. Интервалы с отсутствием совпадений — вокал, пики совпадений — молчание (т.е. чистый минус, который аналогичен исходной дорожке). В такой ситуации мы считаем число фрагментов с совпадениями и вычисляем условный «коэффициент сходства» по числу самих совпадений.
После кластеризации похожих треков отдельные кластеры оказались значительно больше остальных. Что там? Там — интересные ситуации, в которых не очень понятно, чем их правильно считать. Например, всем известная Happy Birthday to You. У нас есть несколько десятков вариантов этой песни, которые отличаются только именем поздравляемого. Считать их разными или нет? То же касается и версий трека на разных языках. Эти искажения и их сочетания стали серьёзной проблемой на этапе запуска.
Нам пришлось изрядно доработать механизм с учётом этих и других не вполне обычных ситуаций. Сейчас система работает должным образом в том числе и на таких сложных кластерах, и мы продолжаем совершенствать её, встречаясь с новыми неординарными преобразованиями. Мы умеем находить песни под вымышленными названиями, ускоренные, с врезками джинглов и без вокала. Поставленная задача была выполнена, и, несомненно, ещё не раз пригодится в дальнейшей работе по развитию сервиса рекомендаций, поиска по музыке и аудиораздела в целом.
Мы умеем находить песни под вымышленными названиями, ускоренные, с врезками джинглов и без вокала. Поставленная задача была выполнена, и, несомненно, ещё не раз пригодится в дальнейшей работе по развитию сервиса рекомендаций, поиска по музыке и аудиораздела в целом.
P.S. Это первая статья из цикла давно обещанных нами историй про техническую сторону ВКонтакте.
Помимо Хабра, мы будем публиковать их в своём блоге на русском и английском языках. Задать вопрос авторам статей тоже можно не только здесь, но и в отдельном сообществе ВК.
Как добавить аудио в «ВК». Скачать с компьютера и с сайта
«Как добавить аудиозапись в ВК?» — этот вопрос обычно задают начинающие пользователи социальной сети «ВКонтакте». Но прежде чем получить на него ответ, необходимо сказать несколько слов о том, что это за проект.
Безусловно, социальная сеть «ВКонтакте» является самой популярной среди русскоязычного сегмента Интернета. Изначально проект, запущенный еще в 2006 году, позиционировал себя как ресурс, где студенты могли общаться. Однако за довольно короткое время сайт завоевал сердца нескольких миллионов человек, а в 2010 году рубеж в 100 миллионов пользователей был преодолен.
Однако за довольно короткое время сайт завоевал сердца нескольких миллионов человек, а в 2010 году рубеж в 100 миллионов пользователей был преодолен.
«ВКонтакте» позволяет людям общаться, играть в интересные приложения, просматривать различные видео, обмениваться фотографиями, создавать группы по интересам или вступать в них. Здесь могут заработать более предприимчивые пользователи.
Скачать музыку с сервера «ВКонтакте»
«Пользователи», зарегистрировавшиеся в этой социальной сети недавно, возможно, не успели разобраться, как добавить аудиозапись в «ВК», поэтому попробуем им помочь. На самом деле у вас есть два варианта, и вы можете воспользоваться любым из них.
Первый способ, позволяющий скачать музыку на свою страницу, это поиск аудиозаписей на сервере ВКонтакте. Стоит отметить, что лучше использовать его, так как если добавить аудио с компьютера, то можно нарушить авторские права и приобрести серьезные проблемы — прецеденты уже были.
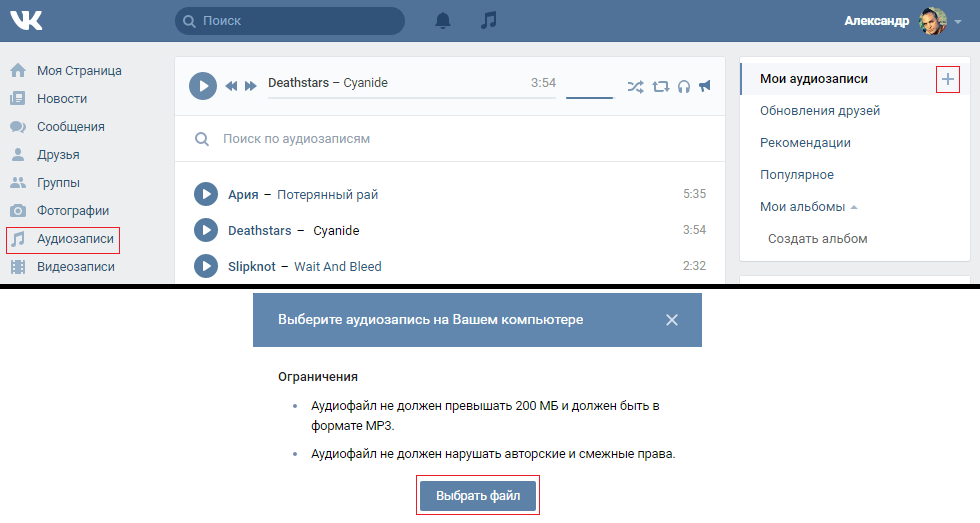
Итак, для того, чтобы скачать аудиозаписи в «ВК», вам необходимо зайти в соответствующий раздел («Мои записи») и написать в поле поиска название песни или исполнителя. Откроется список, в котором нужно выбрать подходящий вариант и справа нажать «+».
Откроется список, в котором нужно выбрать подходящий вариант и справа нажать «+».
После выполнения этой операции песня появится в ваших аудиозаписях.
Загрузка с компьютера
Если вы хотите добавить во «ВКонтакте» музыку, которая хранится на вашем устройстве, то вам поможет следующий алгоритм действий:
- Откройте свою страницу в социальной сети и перейдите в раздел «Мои аудиозаписи».
- В меню справа вы увидите кнопку «Мои аудиозаписи». Нужно нажать на «+».
- В открывшемся окне нажмите кнопку «Выбрать файл», а затем укажите путь к аудиозаписи.
- Нажмите «Открыть» и дождитесь окончания загрузки.
Обратите внимание на требования к загружаемому файлу: он не должен нарушать авторские права, должен «весить» не более 200 МБ и иметь формат MP3. Кстати, бывают ситуации, когда не получается с первого раза скачать музыку с устройства на сервер. В этом случае повторите эту операцию.
Теперь вы знаете, как добавить аудио в «ВК» со своего устройства, чтобы вы могли слушать любимые песни и делиться ими с другими пользователями социальной сети.
Редактирование загруженного файла
Как правило, музыкальный файл, скачанный с компьютера, необходимо отредактировать — указать имя исполнителя и название песни. Возможно, вы хотите внести какие-то изменения в добавленную с сервера запись (исправление названия трека, группы). Вы уже знаете, как скачать аудиозапись в «ВК», поэтому мы продолжим ее редактировать позже.
Сначала откройте раздел, где находится ваша музыка на сайте. Выберите аудиозапись и нажмите кнопку с карандашом справа. Откроется окно, в котором можно указать название музыкального произведения и исполнителя.
Нажав кнопку «Дополнительно», вы сможете указать жанр для трека, а также прописать текст песни. По завершении редактирования сохраните изменения, нажав соответствующую кнопку.
Заключение
Итак, теперь вы знаете, как добавить аудиозапись в «ВК», а это значит, что вы можете выкладывать музыку на свою страницу в этой социальной сети.
Кроме того, вы можете отправить его через личные сообщения или добавить себя на стену, чтобы другие пользователи знали о ваших музыкальных предпочтениях.
Balanced Audio Technology Предварительный усилитель VK-5 и усилители мощности VK-60/75 VK-5i, декабрь 1997 г.
Роберт Дойч снова написал о VK-5 i в декабре 1997 г. (Том 20 № 12) :Слушая через предусилитель Jeff Rowland Design Group Synergy, я заметил мелкие детали, такие как вдохи флейтиста Криса Нормана на его компакт-диске Beauty of the North (Dorian DOR-90190) и точность фортепианной техники Гипериона Найта. на Stereophile ‘s Rhapsody Компакт-диск (STPH010-2). Низкоуровневые шумы и ощущение атмосферы на недавней записи Делоса Berlioz Te Deum (DE 3200) были очерчены с четкостью, которая превосходила во всем остальном превосходный BAT VK-5 i за 4495 долларов.
Инструменты и голоса были определены в пространстве с большой точностью, VK-5 и — которые я не считал слабыми в этом отношении — звучали очень слегка завуалировано по сравнению с ними. Это особенно впечатляло переходные процессы, такие как разнообразные перкуссионные звуки All Star Percussion (Golden String GS CD 005). У Synergy также был более глубокий, лучше контролируемый бас, что заметно по щипковым басам и большим барабанам.
У Synergy также был более глубокий, лучше контролируемый бас, что заметно по щипковым басам и большим барабанам.
Хотя Synergy по чистоте, воспроизведению басов, точности звуковой сцены и детализации опережала VK-5 и , я обнаружил, что последние превосходят их в способности воспроизводить инструментальные и вокальные текстуры в естественной, гармонически точной форме. способ. У Synergy, конечно же, нет того чрезмерно вытравленного звука, который у многих людей ассоциируется с полупроводниковыми; в нем нет никакой резкости или резкости, кроме того, что явно связано с источником.
И все же… с VK-5 i «Valse Frontenac» на Краса Севера звучал более расслабленно, менее «резко», аккордеон имел больше горько-сладкого качества, характерного для настоящего инструмент, а не его электронная копия. С VK-5 i Сильвия Макнейр ( Sure Thing: The Jerome Kern Songbook , Philips 442 129-2) более правдоподобно представляла в комнате, хотя Synergy позволила мне легче сосредоточиться на деталях.