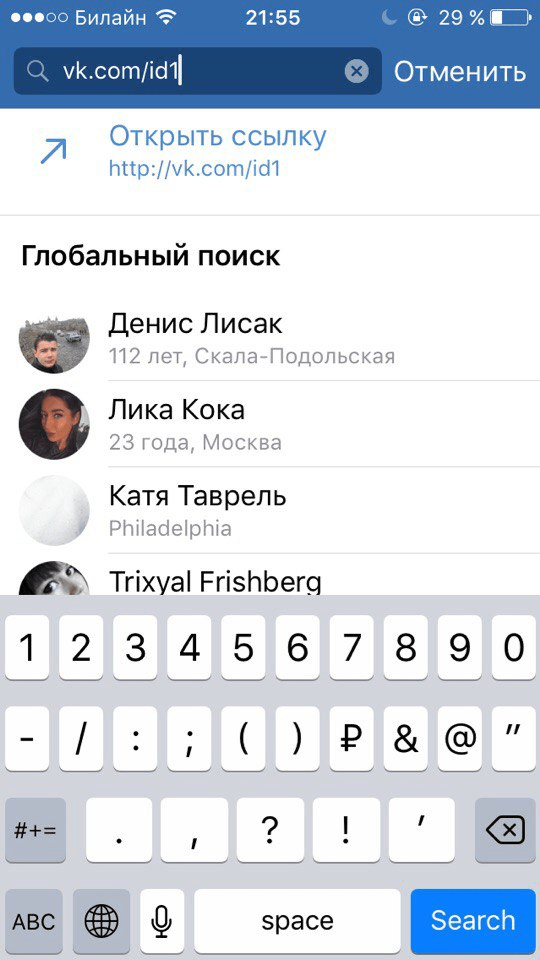
Вычислить статистику движения—Portal for ArcGIS
Эта функция в настоящее время поддерживается только в Map Viewer Classic (прежнее название Map Viewer). Она будет доступна в следующей версии нового Map Viewer.
Инструмент Вычислить статистику движения рассчитывает статистику движения и измеряет признаки для точечных объектов с поддержкой времени, представляющих один или несколько движущихся объектов. Точечные данные с поддержкой времени должны включать объекты, представляющие момент времени.
Схема рабочего процесса
Анализ с помощью GeoAnalytics Tools
Анализ, выполняемый с помощью GeoAnalytics Tools работает с использованием распределенной обработки по нескольким компьютерам ArcGIS GeoAnalytics Server и ядрам. GeoAnalytics Tools и стандартные инструменты анализа ArcGIS Enterprise имеют различные параметры и возможности. Более подробно об этих различиях см. в разделе Различия между инструментами анализа объектов.
Терминология
| Термин | Описание |
|---|---|
Геодезический | Линия, нарисованная на сфере. |
Плоскостной | Расстояние по прямой линии, как измеренное на плоской поверхности (то есть на декартовой плоскости). Это также называется Евклидовым расстоянием. |
Текущий | Отдельный момент времени, заданный начальным временем и не имеющий конечного времени. |
Сегмент | Сегмент трека — это путь между двумя последовательными наблюдениями в треке. |
Отслеживание | Последовательность пространственных объектов, у которых включено время с мгновенным типом времени. |
 Геодезическая линия, нарисованная на глобусе, представляет собой кривизну геоида Земли.
Геодезическая линия, нарисованная на глобусе, представляет собой кривизну геоида Земли. Пространственные объекты определяются как последовательность при помощи идентификатора трека и упорядочены во времени. Например, у городской коммунальной службы может быть парк снегоуборочной техники, в котором записывается местоположение каждой снегоуборочные машины каждые 10 минут. ID транспортного средства может представлять собой отдельные треки.
Пространственные объекты определяются как последовательность при помощи идентификатора трека и упорядочены во времени. Например, у городской коммунальной службы может быть парк снегоуборочной техники, в котором записывается местоположение каждой снегоуборочные машины каждые 10 минут. ID транспортного средства может представлять собой отдельные треки.Пример
Городские службы осуществляют мониторинг снегоуборочной техники и хотят более точно отслеживать передвижение транспортных средств. Они могут использовать инструмент Вычислить статистику движения для определения мест простоя и времени, затраченного на холостой ход, средних и максимальных скоростей за заданное время, общего пройденного расстояния и другой статистики.
Примечания по использованию
Инструмент Вычислить статистику движения принимает в качестве входных данных точечный слой с поддержкой времени и обогащает точки статистикой движения и измерениями. Расчеты основаны на времени входных объектов и значениях геометрии.
Результатом работы инструмента Вычислить статистику движения является копия входных точек с новым полем для каждой вычисленной статистики.
Вы можете указать одно или более полей для идентификации треков. Треки представлены с помощью уникальной комбинации одного или нескольких полей трека. Например, если поля flightID и Destination используются в качестве идентификаторов трека, следующие объекты ID007, Solden и ID007, Tokoyo попадут в два отдельных трека, поскольку они имеют отличающиеся значения в поле Destination.
Статистика, начинающаяся с Min-, Max-, Avg- или Tot- рассчитывается с использованием текущего наблюдения и ряда предыдущих наблюдений, определяемых параметром Выбрать число точек, которые будут использоваться в вычислениях. Другие показатели статистики всегда рассчитывается с использованием только текущего и предыдущего наблюдения и не учитывают количество указанных точек. Вы можете рассматривать этот параметр как количество наблюдений от текущего времени назад. Например, если вы выберете 5 в качестве числа точек и запросите группу статистики Скорость, то текущие и предыдущие четыре наблюдения будут использоваться для вычисления значений MinSpeed, MaxSpeed и AvgSpeed в каждом наблюдении, в то время как значения Speed будут вычисляться только с использованием текущего и предыдущего наблюдения в каждой точке. Количество точек должно быть больше одного, по умолчанию — три.
Например, если вы выберете 5 в качестве числа точек и запросите группу статистики Скорость, то текущие и предыдущие четыре наблюдения будут использоваться для вычисления значений MinSpeed, MaxSpeed и AvgSpeed в каждом наблюдении, в то время как значения Speed будут вычисляться только с использованием текущего и предыдущего наблюдения в каждой точке. Количество точек должно быть больше одного, по умолчанию — три.
Если в истории трека меньше наблюдений, чем количество точек, статистика, начинающаяся с Min-, Max-, Avg- или Tot- вычисляется с использованием всех наблюдений в истории трека.
По умолчанию все поддерживаемые показатели статистики вычисляются для каждой входной точки, если это возможно. Вы можете включить или исключить статистические группы с помощью флажка Выбрать один или несколько типов статистики движения.
В приведенных ниже таблицах описываются статистические показатели, рассчитанные для каждой группы. Термин окно истории треков относится ко всем наблюдениям, определенным параметром Выбрать число точек, которые будут использоваться в вычислениях.
- Расстояние
Статистика Описание Расстояние
Расстояние, пройденное от предыдущего наблюдения к текущему.
Общее расстояние
Сумма расстояний, пройденных между наблюдениями в окне истории треков.
Минимальное расстояние
Минимальное расстояние, пройденное между наблюдениями в окне истории треков.
Максимальное расстояние
Максимальное расстояние, пройденное между наблюдениями в окне истории треков.

Среднее расстояние
Среднее значение расстояния, пройденного между наблюдениями в окне истории треков.
- Скорость
Статистика Описание Скорость
Скорость перемещения от предыдущего наблюдения к текущему.
Минимальная скорость
Минимальная скорость между наблюдениями в окне истории треков.
Максимальная скорость
Максимальная скорость между наблюдениями в окне истории треков.
Средняя скорость
Сумма расстояний между наблюдениями в окне истории треков, деленная на сумму продолжительностей между наблюдениями в окне истории треков.
- Acceleration
Статистика Описание Acceleration
Разница между текущей скоростью и предыдущей скоростью делится на текущую продолжительность.
Минимальное ускорение
Минимальное ускорение, рассчитанное в окне истории треков.
Максимальное ускорение
Максимальное ускорение, рассчитанное в окне истории треков.
Среднее ускорение
Разница между текущей и первой скоростями в окне истории треков делится на сумму продолжительностей между наблюдениями в окне истории треков.
- Продолжительность
Статистика Описание Продолжительность
Время, прошедшее с момента предыдущего наблюдения.
Общая продолжительность
Сумма продолжительностей в окне истории треков.
Минимальная продолжительность
Минимальная продолжительность в окне истории треков.
Максимальная продолжительность
Максимальная продолжительность в окне истории треков.
Средняя продолжительность
Сумма продолжительностей в окне истории треков, деленная на количество точек.
- Высота
Статистика Описание Высота
Текущая высота наблюдения.
Изменение высоты
Разница между текущей и предыдущей высотой.
Общее изменение высоты
Сумма изменений высоты между точками в окне истории треков. Значение может быть отрицательным.
Минимальная высота
Минимальная высота в окне истории треков.
Максимальная высота
Максимальная высота в окне истории треков.
Средняя высота
Сумма высот в окне истории треков, деленная на количество точек.
- Уклон
Статистика Описание Уклон
Отношение изменения высоты к расстоянию между текущим и предыдущим наблюдениями.
Мин. уклон
Минимальный уклон в окне истории треков.
Максимальный уклон
Максимальный уклон в окне истории треков.
Средний уклон
Сумма уклонов в окне истории треков, деленная на количество точек.
- Простой
Статистика Описание Idling
True, если расстояние между текущим наблюдением и предыдущим меньше значения Допуска расстояния простоя, а длительность между текущим наблюдением и предыдущим равна по меньшей мере значению Допуска времени простоя.
False, если одно или оба из этих условий не выполняются.Общее время простоя
Сумма длительностей в окне истории треков, удовлетворяющих критериям простоя.
Процент времени простоя
Процентное время обнаруженного простоя.
- Направление
Статистика Описание Направление
Угол перемещения от предыдущего наблюдения к текущему.


 False, если одно или оба из этих условий не выполняются.
False, если одно или оба из этих условий не выполняются.Статистика не вычисляется для первого объекта в каждом треке. Статистика в группе Ускорение не вычисляется для первых двух объектов в каждом треке.
Статистика в группе Ускорение не вычисляется для первых двух объектов в каждом треке.
Результирующие значения выражены в единицах измерения, заданных параметрами Единица измерения расстояния, Единица измерения продолжительности, Единица измерения скорости, Единица измерения ускорения и Единица измерения высоты. По умолчанию используются метры, секунды, метры в секунду (м/с) и метры в секунду в квадрате (м/с2).
Есть два метода определения расстояния на выбор: плоскостной и геодезический. По умолчанию – Геодезический. Плоскостной метод измеряет расстояния с помощью Евклидовой плоскости и не вычисляет статистику по всей линии дат. Когда вы используете геодезический метод для вычисления расстояния, пространственная привязка может быть перемещена, вычисления пересекают линию даты, когда это необходимо.
Применение временного интервала разделяет треки на заданные интервалы. Например, если вы установили временную границу равной 1 дню, начиная с 9:00 утра 1 января 1990 года, каждый трек усекается в 9:00 утра для каждого дня. Такое разбиение позволяет ускорить обработку, т.к. небольшие треки для анализа создаются быстрее. Если разбиение на повторяющиеся интервалы может влиять на результаты анализа и рекомендуется для обработки больших данных. Используйте параметры Временной интервал и Время для выравнивания временных интервалов до, чтобы указать необязательное разбиение временных границ.
Такое разбиение позволяет ускорить обработку, т.к. небольшие треки для анализа создаются быстрее. Если разбиение на повторяющиеся интервалы может влиять на результаты анализа и рекомендуется для обработки больших данных. Используйте параметры Временной интервал и Время для выравнивания временных интервалов до, чтобы указать необязательное разбиение временных границ.
Если опция Использовать текущий экстент карты включена, будут анализироваться только те объекты, которые отображаются в текущем экстенте. Если опция отключена, анализ будет выполнен для всех входных объектов входного слоя, даже если они находятся вне текущего экстента карты.
Ограничения
Входными данными должны быть точечные слои с включенным временем, имеющие тип Текущий. Любые объекты, не имеющие временных атрибутов или геометрии, не будут включены в выходной слой.
Как работает инструмент Вычислить статистику движения
В разделе ниже описывается работа инструмента Вычислить статистику движения.
Уравнения и вычисления
В таблице ниже приведены статистические расчеты для приведенного выше примера. Все вычисления оцениваются в точке с ID p5 и используют окно истории треков 4. Расчеты включают в себя ID точек p2, p3, p4 и p5. Наблюдение считается простоем, если оно переместилось менее чем на 32 метра за 1 минуту.
| Статистика | Формула | Пример |
|---|---|---|
Расстояние | 35 м | |
Общее расстояние | 80 + 30 + 35 = 145 м | |
Скорость | Расстояние / Продолжительность | 35 / 60 = 0. |
Средняя скорость | Общее расстояние / Общая продолжительность | 145 / 180 м/с |
Acceleration | (0,58 – 0,5) / 60 = 0,001 м/с2 | |
Среднее ускорение | (Скорость (последняя) – Скорость (первая)) / Общая продолжительность | (0,58 – 1,33) / 60 = -0,01 м/с2 |
Продолжительность | 60 с | |
Общая продолжительность | 60 + 60 + 60 = 180 с | |
Высота | 5 м | |
Изменение высоты | 5 – 4 = 1 м | |
Общее изменение высоты | 5 – 0 = 5 м | |
Уклон | Изменение высоты / Расстояние | 1 / 35 |
Средний уклон | Общее изменение высоты / Общее расстояние | 5 / 145 |
Idling | False | |
Общее время простоя | 60 секунд | |
Процент времени простоя | 1 / 3 | |
Направление | 0 |
 58 м/с
58 м/сПример ArcGIS API for Python
Инструмент Вычислить статистику движения доступен в ArcGIS API for Python.
Этот пример вычисляет расстояние и статистику времени ожидания для грузовиков доставки.
# Import the required ArcGIS API for Python modules
import arcgis
from arcgis.gis import GIS
# Connect to your ArcGIS Enterprise portal and confirm that GeoAnalytics is supported
portal = GIS("https://myportal.domain.com/portal", "gis_publisher", "my_password", verify_cert=False)
if not portal.geoanalytics.is_supported():
print("Quitting, GeoAnalytics is not supported")
exit(1)
# Search for and list the big data file shares in your portal
search_result = portal.content.search("", "Big Data File Share")
# Look through the search results for the big data file share of interest
bd_layer = next(x for x in search_result if x.title == "bigDataFileShares_TruckingGPSPoints")
# Run the Calculate Motion Statistics tool
result = arcgis.geoanalytics.data_enrichment.calculate_motion_statistics(input_layer = bd_layer,
track_fields = "truckID",
track_history_window = 4,
motion_statistics="Distance,Idle", dist_method="Geodesic",
idle_tol_dist="500",
idle_tol_unit="Meters",
idle_time_tol="30",
idle_time_tol_unit="Minutes",
time_boundary_split="1",
split_unit="Days",
time_bound_ref="655213515000",
distance_unit="Feet",
duration_unit="Seconds",
output_name = "CMS_results")
# Visualize the results if you are running Python in a Jupyter Notebook
processed_map = portal. map()
processed_map.add_layer(result)
processed_map
Похожие инструменты
Используйте инструмент Вычислить статистику движения для вычисления таких признаков, как скорость, ускорение, дирекционный угол и многих других для точечных объектов с поддержкой времени, представляющих движущиеся объекты. Другие инструменты могут применяться для решения похожих, но немного отличающихся задач.
Инструменты анализа Map Viewer Classic
Если вы пытаетесь присоединить атрибуты из сетки нескольких переменных к точечному слою, используйте инструмент Обогатить из сетки нескольких переменных.
Инструменты анализа ArcGIS Pro
Инструмент Вычислить статистику движения также доступен в ArcGIS Pro.
Для запуска инструмента из ArcGIS Pro ваш активный портал проекта должен быть запущен с версией ArcGIS Enterprise 10.9 или более поздней. В версии 10.9 вход на портал необходимо выполнить под учетной записью, имеющей права доступа для выполнения пространственного анализа на данном портале.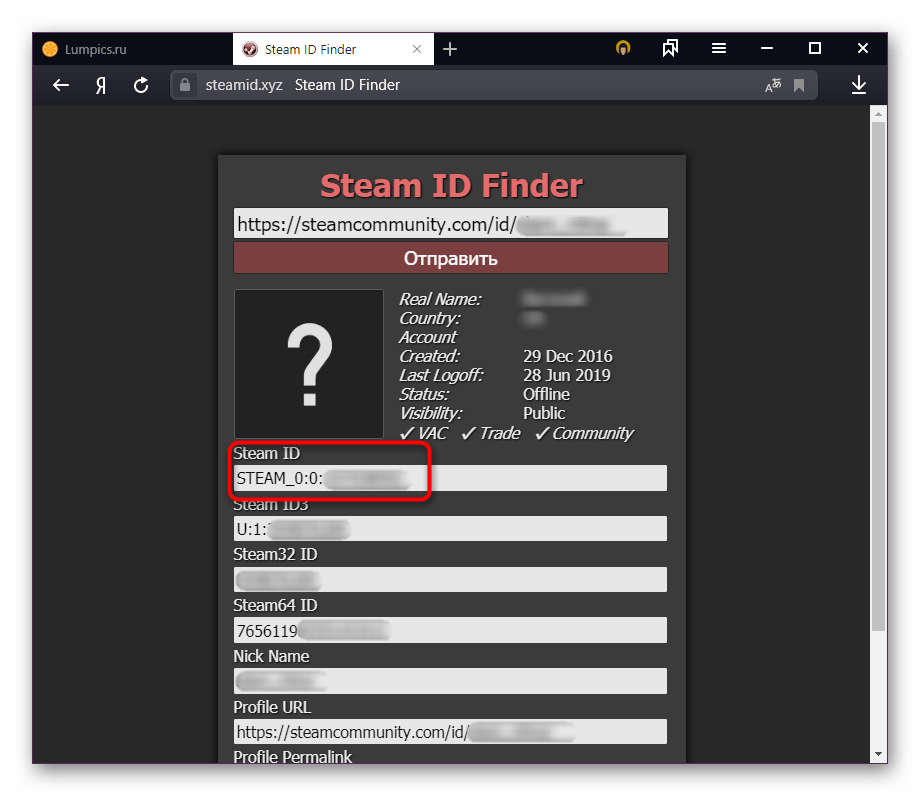
Инструмент Вычислить статистику движения выполняет функцию, аналогичную инструменту Классификация событий движения в ArcGIS Pro.
Отзыв по этому разделу?
Специфичность — CSS | MDN
Специфичность — это способ, с помощью которого браузеры определяют, какие значения свойств CSS наиболее соответствуют элементу и, следовательно, будут применены. Специфичность основана на правилах соответствия, состоящих из селекторов CSS различных типов.
Специфичность представляет собой вес, придаваемый конкретному правилу CSS. Вес правила определяется количеством каждого из типов селекторов в данном правиле. Если у нескольких правил специфичность одинакова, то к элементу применяется последнее по порядку правило CSS. Специфичность имеет значение только в том случае, если один элемент соответствует нескольким правилам. Согласно спецификации CSS, правило для непосредственно соответствующего элемента всегда будет иметь больший приоритет, чем правила, унаследованные от предка.
Примечание: Примечание: Взаимное расположение элементов в дереве документа не влияет на специфичность.
Типы селекторов
В следующем списке типы селекторов расположены по возрастанию специфичности:
- селекторы типов элементов (например,
h2) и псевдоэлементов (например,::before). - селекторы классов (например,
.example), селекторы атрибутов (например,[type="radio"]) и псевдоклассов (например,:hover). - селекторы идентификаторов (например,
#example).
Универсальный селектор (*), комбинаторы (>, ~, ‘«’) и отрицающий псевдокласс (:not()) не влияют на специфичность. (Однако селекторы, объявленные внутри :not(), влияют)
Стили, объявленные в элементе (например, style="font-weight:bold"), всегда переопределяют любые правила из внешних файлов стилей и, таким образом, их специфичность можно считать наивысшей.
Важное исключение из правил —
!importantКогда при объявлении стиля используется модификатор !important, это объявление получает наивысший приоритет среди всех прочих объявлений. Хотя технически модификатор !important не имеет со специфичностью ничего общего, он непосредственно на неё влияет. Поскольку !important усложняет отладку, нарушая естественное каскадирование ваших стилей, он не приветствуется и следует избегать его использования. Если к элементу применимы два взаимоисключающих стиля с модификатором !important, то применён будет стиль с большей специфичностью.
Несколько практических советов:
- Всегда пытайтесь использовать специфичность, а
!importantиспользуйте только в крайних случаях - Используйте
!importantтолько в страничных стилях, которые переопределяют стили сайта или внешние стили (стили библиотек, таких как Bootstrap или normalize. css) - Никогда не используйте
!important, если вы пишете плагин или мэшап. - Никогда не используйте
!importantв общем CSS сайта.
 css)
css)Вместо !important можно:
- Лучше использовать каскадные свойства CSS
- Использовать более специфичные правила. Чтобы сделать правило более специфичным и повысить его приоритет, укажите один элемент или несколько перед нужным вам элементом:
<div> <span>Text</span> </div>
div#test span { color: green } div span { color: blue } span { color: red }
Вне зависимости от порядка следования правил, текст всегда будет зелёным, поскольку у этого правила наибольшая специфичность (при этом, правило для голубого цвета имеет преимущество перед правилом для красного, несмотря на порядок следования).
Вам придётся использовать !important если:
А) Первый сценарий:
- У вас есть общий файл стилей, устанавливающий правила для внешнего вида сайта.
- Вы пользуетесь (или кто-то другой пользуется) весьма сомнительным средством — объявлением стилей непосредственно в элементах

В таком случае вам придётся объявить некоторые стили в вашем общем файле CSS как !important, переопределяя, таким образом, стили, установленные в самих элементах.
Пример из практики: Некоторые плохо написанные плагины jQuery, использующие присваивание стилей самим элементам.
Б) Ещё сценарий:
#someElement p {
color: blue;
}
p.awesome {
color: red;
}
Как сделать цвет текста в абзацах awesome красным всегда, даже если они расположены внутри #someElement? Без !important у первого правила специфичность больше и оно имеет преимущество перед вторым.
Как преодолеть !important
A) Просто добавьте ещё одно правило с модификатором !important, у которого селектор имеет большую специфичность (благодаря добавлению типа элемента (тэга), идентификатора (атрибута id) или класса к селектору).
Пример большей специфичности:
table td {height: 50px !important;}
.myTable td {height: 50px !important;}
#myTable td {height: 50px !important;}
Б) Или добавьте правило с модификатором !important и таким же селектором, но расположенное в файле после существующего (при прочих равных выигрывает последнее объявленное правило):
td {height: 50px !important;}
В) Или перепишите первоначальное правило без использования !important.
С более подробной информацией можно ознакомиться по следующим ссылкам:
Когда надо использовать !important в CSS?
Что означает !important в CSS?
Когда в CSS надо использовать модификатор !important
Как преодолеть !important
Как использовать модификатор !important в CSS чтобы сэкономить время
Не исключение —
:not()Отрицающий псевдокласс :not не учитывается как псевдокласс при расчёте специфичности. Однако селекторы, расположенные внутри
Однако селекторы, расположенные внутри :not, при подсчёте количества по типам селекторов рассматриваются как обычные селекторы и учитываются.
Следующий фрагмент CSS …
div.outer p {
color: orange;
}
div:not(.outer) p {
color: lime;
}
… применённый к такому HTML …
<div>
<p>Это div.outer</p>
<div>
<p>Это текст в div.inner</p>
</div>
</div>
… отобразится на экране так:
Это div.outer
Это текст в div.inner
Специфичность основана на форме
Специфичность опирается на форму селектора. В следующем примере, при определении специфичности селектора, селектор *[id="foo"] считается селектором атрибута, даже при том, что ищет идентификатор.
Эти объявления стилей …
*#foo {
color: green;
}
*[id="foo"] {
color: purple;
}
… применённые к нижеследующей разметке …
<p>Это пример.</p>
… в результате выглядят так:
Это пример.
Потому что оба правила соответствуют одному и тому же элементу, но селектор идентификатора имеет большую специфичность.
Независимость от расположения
Взаимное расположение элементов, указанных в селекторе не влияет на специфичность правила. Следующие объявления стилей …
body h2 {
color: green;
}
html h2 {
color: purple;
}
… в сочетании со следующим HTML …
<html> <body> <h2>Вот заголовок!</h2> </body> </html>
… отобразится как:
Вот заголовок!
Потому что, хотя оба объявления имеют одинаковое количество типов селекторов, но селектор html h2 объявлен последним.
Непосредственно соответствующие элементы и унаследованные стили
Стили непосредственно соответствующих элементов всегда предпочитаются унаследованным стилям, независимо от специфичности унаследованного правила. Этот CSS …
#parent {
color: green;
}
h2 {
color: purple;
}
. .. с таким HTML …
.. с таким HTML …
<html> <body> <h2>Вот заголовок!</h2> </body> </html>
… тоже отобразится как:
Вот заголовок!
Потому что селектор h2 непосредственно соответствует элементу, а стиль, задающий зелёный цвет, всего лишь унаследован от родителя.
- Калькулятор специфичности: Интерактивный сайт, помогающий вам проверить и понять ваши собственные правила CSS — https://specificity.keegan.st/
- Специфичность селекторов в CSS3 — http://www.w3.org/TR/selectors/#specificity
- Ключевые концепции CSS
- Синтаксис CSS
- @-правила
- комментарии
- специфичность
- наследование
- блочная модель
- режимы компоновки
- модели визуального форматирования
- Схлопывание отступов
- Значения
- начальные
- вычисленные
- используемые
- действительные
- Синтаксис определения значений (en-US)
- Сокращённые свойства
- Замещаемые элементы
Last modified:  000Z»>30 нояб. 2022 г., by MDN contributors
000Z»>30 нояб. 2022 г., by MDN contributors
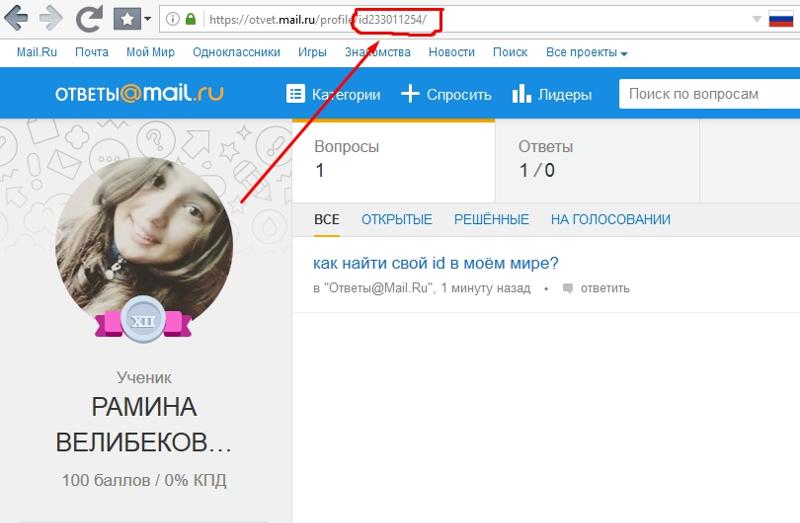
Рассчитать изменение для каждого пациента с данным идентификатором — Общие
Elijawaa #1
Всем привет,
Мне нужна помощь с проектом, над которым я работаю. Я создал новые данные из данных Iris, которые аналогичны тем, над которыми я работаю.,
Для каждого идентификатора пациента я хочу рассчитать произошедшие изменения. Например, для изменения длины чашелистика (т.е. L.Change) у меня есть значение (5,0-4,9).-4,0-5,1=-9). Затем я помещу это значение (-9) в последнюю строку для этого идентификационного номера пациента (таким образом, 1 в данном случае), а затем сделаю то же самое для остальных пациентов.
Я надеялся, что приведенный ниже код сработает, тогда я подумаю, как превратить его в функцию, но получаю следующую ошибку.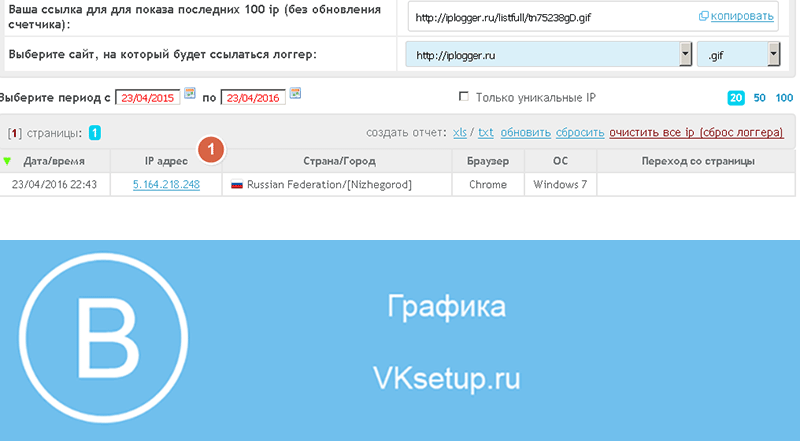
Мне интересно, может ли кто-нибудь помочь мне с функцией для решения этой проблемы. У меня более 900 уникальных идентификационных номеров (наблюдений) и более 30 переменных.
Ошибка: объект «L.Change» не найден
L.Change[4,]==радужная оболочка$Sepal.Length[4,]-радужная оболочка$Sepal.Length[3,]-радужная оболочка$Sepal.Length[2,]-радужная оболочка$Sepal.Length[1,]
ID SEPAL.Length L.CHANGE SEPAL.Width W.Change
1 5,1 Na 3,5 Na
1 4,0 Na 4,0 Na
1 4,9 Na 5,0 Na
1 5,0 Na 9,0 Na
2 6,5 Na 7,0 Na
2 7,0 Na 6.0 Na
2 6,5 Na 7,0 Na
2 7,0 Na 6,0 Na
2 6,5 NA NA
2 3,9 NA 8,5 NA
2 7,0 NA 7,5 NA
3 4,7 NA 3,5 NA
3 7,0 NA 2,6 NA
FJCC #2
Проблема со строкой кода, которую вы разместили, заключается в том, что L. Change не существует вне irisn. Вы должны обращаться к нему как к irisn$L.Change. Кроме того, == сравнивает два объекта на равенство, не присваивая значение левой стороне.
Change не существует вне irisn. Вы должны обращаться к нему как к irisn$L.Change. Кроме того, == сравнивает два объекта на равенство, не присваивая значение левой стороне.
Я не думаю, что это рабочий подход к получению ваших значений, хотя, возможно, кто-то другой найдет способ сделать это в том же духе. Я предлагаю воздержаться от размещения сводных вычислений в специальной колонке в конце группы строк. Это распространено в электронных таблицах, но не очень хорошо согласуется с тем, как работает R. Я позволил себе удалить два столбца «Изменить» и суммировать данные в новый фрейм данных, используя типичные функции R для группировки строк и суммирования результатов. Помогает ли приведенный ниже код вам вообще? Я понимаю, что не знаю, что вам нужно делать дальше, так что это может быть бесполезно для вас.
библиотека(тидыр)
библиотека (dplyr)
DF <- read.csv("/home/fjcc/R/Play/Sepal.txt", sep = " ")
ДФ
#> ID Sepal.Length Sepal.Width
#> 1 1 5.1 3.5
#> 2 1 4.0 4.0
#> 3 1 4,9 5,0
#> 4 1 5,0 9,0
#> 5 2 6,5 7,0
#> 6 2 7,0 6,0
#> 7 2 3,9 8,5
#> 8 2 7,0 7,5
#> 9 3 4,7 3,5
#> 10 3 7,0 2,6
Вычислить <- функция (x, y) {
MaxRow <- max(y)
x[y == MaxRow] - сумма(x[y < MaxRow])
}
DF2 <- DF %>% collect(key = Feature, value = "Value", Sepal. Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
мутировать(RowID = row_number()) %>%
суммировать (изменить = вычислить (значение, RowID))
ДФ2
#> # Таблица: 6 x 3
#> # Группы: ID [3]
#> Изменение функции идентификатора
#>
#> 1 1 Чашелистик.Длина -9#> 2 1 Чашелистик.Ширина -3,5
#> 3 2 Чашелистик.Длина -10,4
#> 4 2 Чашелистик.Ширина -14
#> 5 3 Чашелистик.Длина 2,3
#> 6 3 Сепал.Ширина -0,900
 Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
мутировать(RowID = row_number()) %>%
суммировать (изменить = вычислить (значение, RowID))
ДФ2
#> # Таблица: 6 x 3
#> # Группы: ID [3]
#> Изменение функции идентификатора
#>
Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
мутировать(RowID = row_number()) %>%
суммировать (изменить = вычислить (значение, RowID))
ДФ2
#> # Таблица: 6 x 3
#> # Группы: ID [3]
#> Изменение функции идентификатора
#> Создано 9 декабря 2019 г. пакетом reprex (v0.2.1)
Elijawaa #3
Привет, FJCC,
Спасибо за быстрый ответ на мой вопрос. Я предполагаю, что мои расчеты ранее отклонились от того, что мне было нужно в фактических данных. Итак, что я собираюсь сделать в фактических данных, так это суммировать разницу в каждый момент времени, которая в этом случае будет суммой (4,0-5,1) + (4,9-4,0)+(5,0-4,9) = (-1,1)+(0,9)+(0,1)=-0,1
Итак, с последней строкой, поскольку я не хотел создавать новую строку, я делаю следующее: разницу/изменение, которое произошло в это время, и добавить его к сумме значений предыдущего изменения. Если новый ряд поможет нам это сделать, то это будет хорошо.
Если новый ряд поможет нам это сделать, то это будет хорошо.
Поскольку основное внимание в этом анализе уделяется сумме этих изменений для каждого идентификатора, я хотел бы создать новый столбец с именем изменение (#прямо рядом с каждой переменной). Или создайте это значение изменения в Excel перед импортом в R (как я сделал)
Я возьму для анализа только идентификатор и новые значения (таким образом, сумму изменений).
Спасибо, и я надеюсь, что вы можете помочь мне снова.
ФЕКЦ #4
Если вам нужны только новые значения и идентификаторы для анализа, я бы рассчитал их так. Идея состоит в том, чтобы сдвинуть значения каждой комбинации ID/Feature на одну строку в новом столбце и вычислить сумму различий между исходными данными и сдвинутыми данными. Обратите внимание, что набор данных, который я использовал, имеет только первые два значения ID = 3,9. 0005
0005
библиотека (тидыр)
библиотека (dplyr)
DF <- read.csv("/home/fjcc/R/Play/Sepal.txt", sep = " ")
ДФ
#> ID Sepal.Length Sepal.Width
#> 1 1 5.1 3.5
#> 2 1 4.0 4.0
#> 3 1 4,9 5,0
#> 4 1 5,0 9,0
#> 5 2 6,5 7,0
#> 6 2 7,0 6,0
#> 7 2 3,9 8,5
#> 8 2 7,0 7,5
#> 9 3 4,7 3,5
#> 10 3 7,0 2,6
DF2 <- DF %>% collect(key = Feature, value = "Value", Sepal.Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
мутировать (LeadVal = ведущий (значение)) %>%
суммировать (изменение = сумма (LeadVal - значение, na.rm = TRUE))
ДФ2
#> # Таблица: 6 x 3
#> # Группы: ID [3]
#> Изменение функции идентификатора
#>
#> 1 1 Длина чашелистика -0,1000
#> 2 1 Чашелистик.Ширина 5,5
#> 3 2 Длина чашелистика 0,5
#> 4 2 Разделитель.Ширина 0,5
#> 5 3 Чашелистик.Длина 2,3
#> 6 3 Чашелистик.Ширина -0,900
DF2 <- DF2 %>% mutate(Feature = paste(Feature, "Chg", sep = "_")) %>%
распространение (ключ = функция, значение = изменение)
ДФ2
#> # Таблица: 3 x 3
#> # Группы: ID [3]
#> ID Sepal.Length_Chg Sepal. Width_Chg
#>
#> 1 1 -0,1000 5,5
#> 2 2 0,5 0,5
#> 3 3 2,3 -0,900
 Width_Chg
#>
Width_Chg
#> Создано 10 декабря 2019 г. пакетом reprex (v0.2.1)
Элиджаваа #5
@FJCC Большое спасибо за помощь!!!
Элиджаваа # 6
Привет, FJCC,
Я пытаюсь смоделировать продольные данные с течением времени. Некоторые из переменных продолжаются, а другие являются категориальными. Можете ли вы дать мне руководство о том, как написать код.
Спасибо
FJCC #7
Пожалуйста, создайте новую тему, так как это другой вопрос. Кроме того, у меня нет опыта моделирования продольных данных, но я уверен, что другие люди на форуме могут вам помочь. Если вы подготовите воспроизводимый пример, другим будет намного легче вам помочь.
1 Нравится
Элайджава # 8
Привет, FJCC,
Я использовал первый код, с которым вы мне помогли, на большом наборе данных, состоящем примерно из 3000 строк и более 100 столбцов, и получил такой результат. У меня тоже есть NA в каждой колонке, но я не уверен, что это причина, по которой я получаю это.
image2016×1512 1,28 МБ
Спасибо
FJCC #9
Чтобы узнать, являются ли проблемы NA, добавьте na.rm = TRUE к функции суммирования.
x[y == MaxRow] - sum(x[y < MaxRow], na.rm = TRUE)
Однако, если значение в x[y == MaxRow] равно NA, я не думаю, что это поможет. Имеет ли смысл заменить NA на ноль в этом наборе данных?
Элиджаваа #10
Я буду использовать na.rm=True, чтобы учесть пропущенные значения.
Этот код отлично работает, но я попытался изменить разницу только между первой и последней строками, но это не сработало.
DF2 <- DF %>% collect(key = Feature, value = "Value", Sepal.Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
mutate(LeadVal = lead(Value )) %>%
summ(Change = LeadVal - last(Value), na.rm = TRUE))
DF2
Можно ли также использовать функцию запаздывания для определения разницы?
ФЕКЦ #11
DF <- read.csv("/home/fjcc/R/Play/Sepal.txt", sep = " ")
ДФ
#> ID Sepal.Length Sepal.Width
#> 1 1 5.1 3.5
#> 2 1 4.0 4.0
#> 3 1 4,9 5,0
#> 4 1 5,0 9,0
#> 5 2 6,5 7,0
#> 6 2 7,0 6,0
#> 7 2 3,98,5
#> 8 2 7,0 7,5
#> 9 3 4,7 3,5
#> 10 3 7,0 2,6
библиотека (dplyr)
библиотека (тидыр)
DF2 <- DF %>% collect(key = Feature, value = "Value", Sepal.Length:Sepal.Width) %>%
group_by(ID, Feature) %>%
мутировать (строка = номер_строки ())
MaxRows <- DF2 %>% суммировать (MaxRow = max (Row))
FirstRow = DF2 %>% filter(Row == 1)
LastRow <- DF2 %>% ungroup() %>% semi_join(MaxRows, by = c("ID", "Feature", "Row" = "MaxRow"))
Diffs <- inner_join(FirstRow, LastRow, by = c("ID", "Feature"), suffix = c(".First", ".Last"))
Diffs <- mutate(Diffs, Difference = Value.Last - Value.First)
Различия
#> # Таблица: 6 x 7
#> # Группы: ID, Feature [6]
#> Значение функции ID.Первая строка.Первое значение.Последняя строка.Последняя разница
#>
#> 1 1 Длина чашелистика 5,1 1 5 4 -0,1000
#> 2 2 Длина чашелистика 6,5 1 7 4 0,5
#> 3 3 Длина чашелистика 4,7 1 7 2 2,3
#> 4 1 Чашелистик. Ширина 3,5 1 94 5,5
#> 5 2 Ширина чашелистика 7 1 7,5 4 0,5
#> 6 3 Ширина чашелистика 3,5 1 2,6 2 -0,900
 Ширина 3,5 1 94 5,5
#> 5 2 Ширина чашелистика 7 1 7,5 4 0,5
#> 6 3 Ширина чашелистика 3,5 1 2,6 2 -0,900
Ширина 3,5 1 94 5,5
#> 5 2 Ширина чашелистика 7 1 7,5 4 0,5
#> 6 3 Ширина чашелистика 3,5 1 2,6 2 -0,900
Создано 18 декабря 2019 г. пакетом reprex (v0.2.1)
система закрыто #12
Эта тема была автоматически закрыта через 7 дней после последнего ответа. Новые ответы больше не допускаются.
Как рассчитать возраст в Excel по идентификационному номеру (4 быстрых метода)
При работе в Excel вам может понадобиться узнать возраст людей из их удостоверений личности. Имея это в виду, этот учебник призван объяснить 4 быстрых метода, как вычислить возраст в Excel по идентификационному номеру.
Скачать практическую рабочую тетрадь
4 метода расчета возраста в Excel по идентификационному номеру
1. Рассчитайте возраст по ID (пошаговый метод)
Рассчитайте возраст по ID (пошаговый метод)
1.1 Расчет возраста по идентификатору с помощью функции MID
1.2 Использование функции DATE для извлечения возраста из идентификатора
2. Рассчитайте возраст напрямую по идентификационному номеру
2.1 Расчет возраста с использованием функций DATEDIF и IF
2.2 Расчет возраста с помощью функций DATEDIF и DATE
3. Преобразование идентификационного номера в возраст с помощью инструментов данных
4. Использование кода VBA
Заключение
Статьи по Теме
Загрузить рабочую тетрадь4 метода расчета возраста в Excel по идентификационному номеру
Следует признать, что Microsoft Excel не предлагает никаких встроенных функций для вычисления возраста, однако мы можем объединить несколько функций для преобразования даты рождения в возраст.
Рассмотрим следующий набор данных (в B4:C14 ) с именами людей и их идентификационными номерами . Вообще говоря, первые 6 цифр в идентификационных номерах представляют дату рождения этого человека в формате гг-мм-дд .
Вообще говоря, первые 6 цифр в идентификационных номерах представляют дату рождения этого человека в формате гг-мм-дд .
К счастью, мы можем извлечь дату рождения из идентификационных номеров , чтобы преобразовать их в возраст в годах. Итак, давайте рассмотрим эти методы один за другим.
1. Расчет возраста по ID (пошаговый метод)
Первый метод сочетает в себе различные функции Excel для простого и пошагового расчета возраста по идентификационным номерам.
1.1 Расчет возраста по идентификатору с помощью функции MIDКак следует из названия, Excel MID , СЕГОДНЯ , и INT функции используются в этом методе.
Шаги:
- Во-первых, добавьте столбец Дата рождения и вставьте эту формулу.
=СРЕДН(C5,5,2)&"/"&СРЕДН(C5,3,2)&"/"&СРЕДН(C5,1,2)
Здесь ячейка C5 представляет собой идентификационный номер (аргумент текст ), а следующие два числа представляют аргументы start_num и num_chars соответственно. В этой формуле функция MID извлекает первые 6 цифр из текста ID Number .
В этой формуле функция MID извлекает первые 6 цифр из текста ID Number .
- Во-вторых, вставьте столбец Текущая дата и введите функцию СЕГОДНЯ , которая возвращает текущую дату.
=СЕГОДНЯ()
- В-третьих, рассчитайте Возраст в годах, рассчитав разницу между двумя датами и делением на 365 дней.
- Кроме того, функция INT округляет возраст до ближайшего целого числа.
=INT((E5-D5)/365)
1.2 Использование функции DATE для извлечения возраста из идентификатора
Этот метод аналогичен предыдущему, применяя функции Excel ДАТА , ЛЕВЫЙ , и INT .
шагов:
- Во-первых, добавьте столбец Дата рождения и вставьте эту формулу.

=ДАТА(ЛЕВО(C5,2),СРЕДН(C5,3,2),СРЕДН(C5,5,2))
Здесь ячейка C5 представляет собой идентификационный номер (аргумент text ).
- Затем добавьте столбец Текущая дата и примените функцию СЕГОДНЯ , которая возвращает текущую дату.
=СЕГОДНЯ()
- Затем рассчитайте Возраст в годах, рассчитав разницу между двумя датами и разделив ее на 365 дней.
=INT((E5-D5)/365)
Подробнее: Формула Excel для расчета возраста на определенную дату
2. Рассчитать возраст непосредственно по идентификационному номеру
Если первый метод слишком трудоемок, то наш следующий вычисляет возраст напрямую, без необходимости в дополнительных столбцах.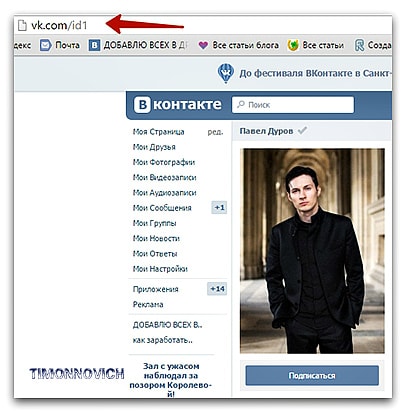 Давайте посмотрим на это в действии.
Давайте посмотрим на это в действии.
Вычисление возраста напрямую смешивает функции DATEDIF , LEFT и IF соответственно, в этом примере ячейка C5 ссылается на идентификационный номер ( text аргумент ) .
=РАЗНДАТ(ДАТА(ЕСЛИ(ЛЕВЫЙ(C5,2)>ТЕКСТ(СЕГОДНЯ(),"ГГ")),"19"&ЛЕВЫЙ(C5,2),"20"&ЛЕВЫЙ(C5,2)СРЕДН( C5,3,2),СРЕДН(C5,5,2)),СЕГОДНЯ(),"у")
Расшифровка формулы
- В этой формуле функция MID получает первые 6 чисел из идентификационного номера в ячейке C5 .
- Затем функция IF проверяет, меньше или больше год, чем текущий год.
- Наконец, функция DATEDIF вычитает год рождения из текущего года и возвращает Age .
2.2 Расчет возраста с помощью функций DATEDIF и DATE
Наш следующий метод еще больше упрощает выражение с помощью функции ДАТА , при этом напрямую определяя возраст человека.
=DATEDIF(DATE(DATE(C5,1,2),MID(C5,3,2),MID(C5,5,2)),СЕГОДНЯ(),"y")
В этом выражении ячейка C5 представляет собой идентификационный номер (аргумент текст ), а два следующих числа относятся к аргументы start_num и num_chars соответственно.
Расшифровка формулы
- Первоначально функция ДАТА принимает 3 аргумента ( год , месяц , день ), которые предоставляются функцией MID .
- Наконец, функция DATEDIF возвращает Age .

3. Преобразование идентификационного номера в возраст с помощью инструментов обработки данных
Вас беспокоит написание сложных выражений и комбинирование функций? Тогда наш третий метод – это ответ на вашу молитву!
Шаг 01. Перейдите к ленте данных
- Во-первых, добавьте столбец ( D5:D14 ) под названием Дата рождения и скопируйте и вставьте все идентификационные номера в этот столбец.
- Затем выберите все ячейки в столбце и нажмите кнопку Текст в столбцы .
Шаг 02: Извлеките дату рождения из идентификационного номера
- Во-вторых, появляется Мастер преобразования текста в столбцы .
- Теперь, на шаге 1, нажмите кнопку Фиксированная ширина , так как все идентификационные номера имеют одинаковое количество цифр.
- Затем щелкните, чтобы переместить курсор сразу после 6-й цифры с левой стороны, как показано на рисунке ниже.
- Наконец, выберите формат Дата из раскрывающегося списка и нажмите Готово , чтобы закрыть диалоговое окно.
Шаг 03: Расчет возраста
- В-третьих, добавьте столбец с именем Текущая дата (E5:E14) и введите функцию СЕГОДНЯ , чтобы получить текущую дату.
- На последнем шаге создайте еще один столбец для Возраст (F5:F14) и вычислите разницу между двумя датами и разделите на 365 дней, чтобы получить Возраст лет.
=INT((E5-D5)/365)
Подробнее: Как рассчитать возраст от дня рождения в Excel (8 простых методов)
4.
 Использование кода VBA
Использование кода VBA Если вам интересно, есть ли способ определить пользовательскую функцию для вычисления возраста по идентификационному номеру? Тогда VBA поможет вам. Прежде чем мы начнем, добавьте столбец Date of Birth и вставьте эту формулу.
=СРЕДН(C5,5,2)&"/"&СРЕДН(C5,3,2)&"/"&СРЕДН(C5,1,2)
Шаг 01. Откройте редактор VBA
- Для начала перейдите на вкладку Developer , а затем на Visual Basic .
Шаг 02: Вставьте код VBA
- Во-вторых, вставьте модуль , куда вы вставите код VBA .
- Для удобства вы можете скопировать код отсюда и вставить его в окно, как показано ниже.
Открытая функция calculate_age (дата_рождения как дата, необязательный result_index как целое число = 0) как вариант
Today_day = день (дата)
Today_month = Месяц (Дата)
Today_year = Год (Дата)
рождения_дата_день = день (дата_рождения)
рождения_дата_месяц = Месяц (дата_рождения)
рождения_дата_год = Год (дата_рождения)
Если дата_месяца_рождения < сегодняшний_месяц Тогда
возраст = сегодняшний_год - дата_рождения_год
ИначеЕсли дата_месяца рождения = сегодняшний_месяц Тогда
Если дата_рождения <= сегодняшний_день Тогда
возраст = сегодняшний_год - дата_рождения_год
Еще
возраст = сегодняшний_год - дата_рождения_год - 1
Конец, если
Еще
возраст = сегодняшний_год - дата_рождения_год - 1
Конец, если
Dim output_array(25) как вариант
output_array(0) = возраст
output_array(1) = Дата
output_array(2) = сегодня_день
output_array(3) = сегодняшний_месяц
output_array(4) = сегодняшний_год
output_array(5) = дата_рождения_день
output_array(6) = день_рождения_месяц
output_array(7) = дата_рождения_год
calculate_age = output_array (result_index)
Завершить функцию Шаг 03: Используйте функцию
- В-третьих, закройте окно VBA и вернитесь на рабочий лист.

