X арт-проектов про технологию распознавания лиц
Чем опасна технология распознавания лиц? Всегда ли стоит ее бояться и в каких случаях она может быть полезна обществу? Как она вообще работает? Можно ли скрыться от умного алгоритма? Предлагаем присмотреться поближе к технологии распознавания лиц, а также способам и последствиям ее использования. В этом нам помогут художественные проекты с соответствующей тематикой и памятка от Tactical Tech, представленная на онлайн-выставке Data CTRL Centre.
Материал создан в поддержку проекта Гёте-Института Data CTRL Centre.
•
О чем речь?
Сперва разберемся в терминологии. Термины Face Detection и Face Recognition на русский почти всегда переводятся одинаково — «распознавание лиц». На самом деле, первую фразу было бы корректнее перевести как «определение лиц»: этот концепт не подразумевает установление личности человека и алгоритм в этом случае не обращается к базе данных, содержащей изображения лиц, которые нужно отыскать на картинке.
Теперь, когда мы в общих чертах разобрались с устройством технологии, давайте посмотрим, как с ней работают художники.
Data-Masks (2013-2015). Sterling Crispin
Это один из первых художественных проектов на эту тему.
Стерлинг Криспин решил изучить, как работает программа по распознаванию лиц. Художник воспользовался методом обратной инженерии и вычислил элементы, по которым машина узнает, что перед ней человеческое лицо. Получившиеся дата-маски автор превратил в объекты, распечатав на 3D-принтере. Для нас такая маска выглядит как результат странного эксперимента с абстрактными формами, а алгоритм по-прежнему видит в ней лицо.
 Стерлинг Криспин решил изучить, как работает программа по распознаванию лиц. Художник воспользовался методом обратной инженерии и вычислил элементы, по которым машина узнает, что перед ней человеческое лицо. Получившиеся дата-маски автор превратил в объекты, распечатав на 3D-принтере. Для нас такая маска выглядит как результат странного эксперимента с абстрактными формами, а алгоритм по-прежнему видит в ней лицо.
Стерлинг Криспин решил изучить, как работает программа по распознаванию лиц. Художник воспользовался методом обратной инженерии и вычислил элементы, по которым машина узнает, что перед ней человеческое лицо. Получившиеся дата-маски автор превратил в объекты, распечатав на 3D-принтере. Для нас такая маска выглядит как результат странного эксперимента с абстрактными формами, а алгоритм по-прежнему видит в ней лицо.Spirit Is a Bone (2013). Broomberg & Chanarin
Адам Брумберг и Оливер Чанарин также заинтересовались тем, как программа видит и реконструирует человеческие лица. С помощью устройств, которые устанавливают на московских улицах для обеспечения общественной безопасности, они создали серию «портретов» людей разных специальностей — отсылая к известному проекту Августа Зандера «Люди двадцатого столетия» и похожему по затее проекту Хельмара Лерски.
Зловещий параллелизм действительно напрашивается: ведь все системы искусственного интеллекта опираются на выдуманные людьми категории, которые часто бывают поверхностными и ошибочными и приравнивают субъекта к определенной функции. При этом 3D-маски не являются полноценными слепками лица: алгоритм воссоздает форму, складывая между собой данные с нескольких камер. Поэтому лицо лишено теней и текстуры, можно сказать, что оно сведено к минимальному набору характеристик, позволяющих опознать человека.
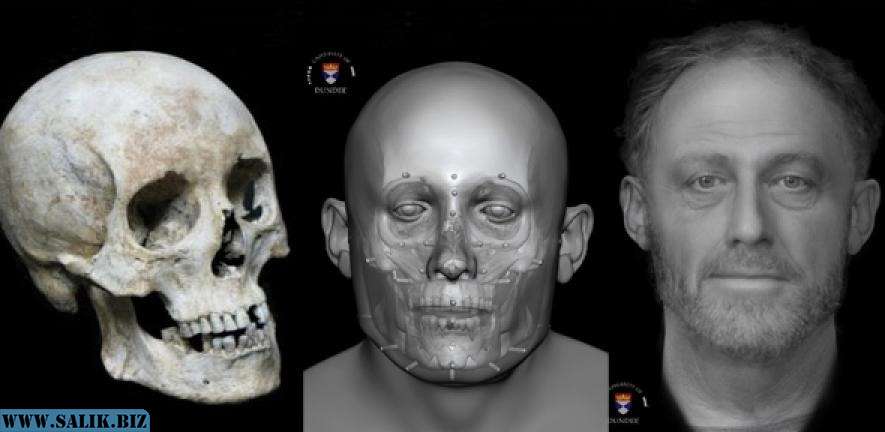
URME Surveillance (2014). Leo Selvaggio
Лео Сельваджио в далеком 2014 году придумал очень простой, но при этом довольно экстравагантный способ спрятаться от расползающихся по городскому пространству распознающих устройств — он предложил всем желающим надеть маску со слепком его собственного лица. Таким образом камеры считывали бы личность Сельваджио вместо настоящей личности владельца маски.
 Проект можно было поддержать на платформе Kickstarter. О том, не пришлось ли автору потом отвечать за чье-то неподобающее поведение, мы информации не нашли.
Проект можно было поддержать на платформе Kickstarter. О том, не пришлось ли автору потом отвечать за чье-то неподобающее поведение, мы информации не нашли.60 из примерно 1 млн изображений с лицами, собранных компанией IBM из FlickrExposing.ai (2021). Adam Harvey
Художник, базирующийся в Берлине, Адам Харви решил изучить, откуда поступают исходные изображения для систем распознавания лиц, а также проверить, можно ли найти в толпе человека по снимку, который тот выложил в соцсети. Будучи студентом HfG в Карлсруэ, Харви начал с создания поискового механизма, который находил похожие картинки в самой большой на тот момент публичной базе данных лиц MegaFace (V2). Большинство фотографий в датасет подгружались из Flickr — без ведома владельцев самих снимков. Программа MegaPixels позволяла проверить, не попала ли чья-то личная фотография в открытый доступ. После того как о проекте Харви написали в The Financial Times, компания Microsoft и несколько университетов отказались от баз данных, которыми пользовались раньше.
Позже Адам Харви продолжил и углубил свое исследование. Совсем недавно — 31 января 2021 года — появился проект Exposing.ai, который уже сканирует шесть разных датасетов и умеет находить снимки не только по фотографии того же человека, но и по никнейму пользователя.

Level of Confidence (2015). Rafael Lozano-Hemmer
Рафаэль Лозано-Хеммер в своей работе «Уровень уверенности» обнажает страшную истину: в этом мире безопасно себя ощущают только те, кто управляет системой, которая якобы призвана охранять общественный порядок. Даже если на каждом углу установить по умной камере, правду все равно можно скрыть, имея доступ к управлению системой видеонаблюдения.
В центре проекта — тайна похищения 43 учеников мексиканской школы Ayotzinapa. Инсталляция была создана спустя полгода после события. Когда зритель подходит к камере, алгоритм начинает сравнивать лицо посетителями с лицами похищенных детей. Затем компьютер показывает фотографию одной из жертв с похожими чертами лица и показывает степень совпадения двух изображений в процентах. Разумеется, машина никогда не выдаст стопроцентный результат, поскольку школьники, скорее всего, были убиты, а участники преступления как следует замели все следы.

Capture (2020). Paolo Cirio
Живой классик медиа-искусства Паоло Кирио в своем проекте Capture демонстрирует, каково это, жить под постоянным надзором и в страхе перед карательным режимом.
Для этой работы Кирио собрал около тысячи снимков, сделанных во время протестных акций во Франции, и вырезал из них лица полицейских.
Европейская комиссия в ответ на жалобу художника заявила, что необходимо на законодательном уровне ограничить сферу применения ИИ.
 Затем художник распечатал портреты полицейских в большом масштабе и развесил на улицах Парижа. Кроме того, Кирио пропустил фотографии через систему распознавания лиц, а затем — создал сайт с теми же самыми снимками, по которым люди могли опознать полицейских. Проект вызвал бурную реакцию: полицейские профсоюзы начали протестовать, опасаясь за безопасность своих коллег; министр внутренних дел Франции выразил в твиттере свое недовольство происходящим; наконец, выставка, на которой должен был быть показан проект, была отменена. В то же время публика и французская пресса работу Кирио встретили с восторгом. Ведь художнику удалось указать на асимметрию использования подобных технологий: власти способны получить информацию практически о любом человеке, попавшем в поле зрения умной камеры, а рядовой житель даже не знает толком, где именно расположены цифровые глаза, как они работают и куда поступают полученные с них данные. Позже Паоло Кирио даже запустил общественную кампанию, призывающую к отмене использования технологий распознавания лиц #BanFacialRecognitionEU.
Затем художник распечатал портреты полицейских в большом масштабе и развесил на улицах Парижа. Кроме того, Кирио пропустил фотографии через систему распознавания лиц, а затем — создал сайт с теми же самыми снимками, по которым люди могли опознать полицейских. Проект вызвал бурную реакцию: полицейские профсоюзы начали протестовать, опасаясь за безопасность своих коллег; министр внутренних дел Франции выразил в твиттере свое недовольство происходящим; наконец, выставка, на которой должен был быть показан проект, была отменена. В то же время публика и французская пресса работу Кирио встретили с восторгом. Ведь художнику удалось указать на асимметрию использования подобных технологий: власти способны получить информацию практически о любом человеке, попавшем в поле зрения умной камеры, а рядовой житель даже не знает толком, где именно расположены цифровые глаза, как они работают и куда поступают полученные с них данные. Позже Паоло Кирио даже запустил общественную кампанию, призывающую к отмене использования технологий распознавания лиц #BanFacialRecognitionEU.
#следуй (2020). Катрин Ненашева
В том же 2020 году Катрин Ненашева вместе со студентами своего курса по арт-активизму придумала проект #следуй. Участники изучали, как с помощью специального мейкапа можно остаться неопознанным для умной камеры и написали чат-бот @followfollow_bot, который делится инструкциями по нанесению защитного грима. По словам художницы, акция носила скорее символический характер, чем практический — ведь алгоритмы постоянно совершенствуются, и мейкап нужно все время перепридумывать. Однако сам факт появления людей с таким гримом на улице помогает единомышленникам сплотиться и воодушевить прохожих на более внимательное и критическое отношение к городским технологиям и тому, что они с собой несут.
•
Отметим, что во многих европейских странах, США, России и Китае по закону участникам общественных мероприятий и митингов запрещено скрывать лица масками и любыми другими аксессуарами, которые «затрудняют установление личности». При этом медицинские маски, по словам экспертов, почти не мешают распознаванию лиц. Получается, что житель большого города фактически лишен права на анонимность. И это всего лишь одно из последствий повсеместного внедрения технологии распознавания лиц. По сути, она начала входить в нашу повседневность около 20 лет назад, но уже привнесла ощутимые изменения в нашу частную и общественную жизнь. Учитывая, что алгоритмы и способы использования технологии все время меняются, сложно сказать, как она повлияет на наше будущее, пока же стоит как минимум изучить основные принципы ее работы.
При этом медицинские маски, по словам экспертов, почти не мешают распознаванию лиц. Получается, что житель большого города фактически лишен права на анонимность. И это всего лишь одно из последствий повсеместного внедрения технологии распознавания лиц. По сути, она начала входить в нашу повседневность около 20 лет назад, но уже привнесла ощутимые изменения в нашу частную и общественную жизнь. Учитывая, что алгоритмы и способы использования технологии все время меняются, сложно сказать, как она повлияет на наше будущее, пока же стоит как минимум изучить основные принципы ее работы.
Тем, кто хочет глубже погрузиться в тему и понять, как меняется культура (визуальная, в особенности) под воздействием технологии распознавания лиц, советуем книгу Portraits of Automated Facial Recognition Лилы Ли-Моррисон.
Использование режима «Люди» для распознавания лиц на фотографиях и видео
Elements Organizer определяет и группирует похожие лица на фотографиях. Узнайте, как добавить имя, чтобы в дальнейшем легко просматривать фотографии и видео, на которых присутствует определенный человек, в режиме просмотра «Люди».
Узнайте, как добавить имя, чтобы в дальнейшем легко просматривать фотографии и видео, на которых присутствует определенный человек, в режиме просмотра «Люди».
Улучшенная технология распознавания лиц Elements Organizer позволяет добавлять имена к людям на фото и видео и систематизировать эти фото и видео по лицам. Для этого перейдите в режим Люди.
В Elements 2020 и более поздних версиях можно выполнять систематизацию и поиск медиафайлов по людям.
Присвойте имена лицам на фотографиях и видео, чтобы упростить систематизацию медиафайлов по людям.
Фотографии на вкладке Люди сортируются по стопкам с людьми, которые распознаны на этих фотографиях. Стопка, связанная с тем или иным человеком, содержит все фотографии и видео человека, которому в Elements Organizer присвоено имя. Например, если человек распознан на 30 медиафайлах разного типа, то они будут отображаться в виде коллекции файлов. На следующем рисунке показано несколько образцов стопок для Джона и Шерон.
Фото лица, которое отображается в качестве обложки стопки, называется изображением профиля.
При импорте медиафайлов Elements Organizer анализирует фотографии и видео в каталоге и группирует похожие лица. Продолжительность анализа может меняться в зависимости от типа файла и каталога. Например, анализ файла RAW займет немного больше времени, чем анализ файла JPEG. Кроме того, анализ видео занимает больше времени по сравнению с анализом фотографий.
На вкладке Без имени отображаются профили всех людей, которым еще не присвоено имя. Здесь, на вкладке Без имени, этим людям можно присвоить имена. Также вы можете исключить лица из стопки, указать, что лицо не должно отображаться в Elements Organizer, или объединить стопки.
Лица, которым присвоены имена, и медиафайлы, на которых распознаны эти лица, отображаются на вкладке С именем. На вкладку Без имени можно вернуться в любом момент и присвоить имена другим лицам без имени.
Просмотр фотографий и видео в стопке
Одно нажатие на стопку открывает список лиц в этой стопке.
Вместо лиц можно просмотреть фотографии и видео, нажав Мультимедиа.
Чтобы вернуться к просмотру лиц, нажмите кнопку Лица.
Нажмите изображение лица человека для отображения связанного с ним медиафайла.
Скрытие и просмотр небольших стопок
По умолчанию Elements Organizer не отображает стопки с небольшим количеством медиафайлов или нечетким изображением лиц. Чтобы просмотреть такие стопки, снимите флажок Скрыть небольшие стопки.
Добавление имен
Нажмите стопку, чтобы отобразить медиафайлы в этой стопке. Чтобы присвоить имена всем медиафайлам в стопке, нажмите кнопку Добавить имя.
Удаление лиц из стопки
Вы можете присвоить имя всем лицам в стопке за один раз. Но, прежде чем это сделать, рекомендуется просмотреть отдельные фотографии в стопке и убедиться, что лица распознаны правильно. Если на некоторых фото изображен другой человек, такие фото можно удалить. Удалить определенные лица из стопки можно одним из следующих способов:
- С помощью команды Это другой человек
- С помощью команды Больше не показывать
Можно выбрать несколько лиц, удерживая клавишу Command (Mac OS) или Ctrl (Windows). Кроме того, выбрать эти лица можно щелчком при нажатой клавише Shift.
Кроме того, выбрать эти лица можно щелчком при нажатой клавише Shift.
Это другой человек
Если лицо распознано неправильно, нажмите кнопку Это другой человек. Лицо будет удалено из текущей стопки и появится в другой стопке на вкладке Без имени. После этого вы сможете присвоить этому лицу другое имя.
Также можно навести курсор мыши на лицо и нажать на появившийся значок белого цвета. Лицо будет удалено из стопки.
Больше не показывать
Чтобы скрыть лицо в Elements Organizer, нажмите Больше не показывать. Лицо больше не будет отображаться в Elements Organizer при присвоении имен. Используйте этот параметр, если не собираетесь присваивать имя этому лицу.
Если лицо скрыто с помощью команды Больше не показывать, присвоить ему имя можно будет только следующими способами:
- Создать новый каталог и импортировать в него медиафайл с лицом.
- Откройте медиафайл, на котором изображено лицо человека, и присвойте лицу имя, как описано в разделе Отметка нераспознанных лиц на фотографиях.

После использования команды Это другой пользователь лицо будет удалено из текущей стопки и появится в другой стопке на вкладке Без имени. Лицо, распознанное на фотографии, можно назначить другому человеку.
Однако при использовании команды Больше не показывать лицо больше не будет отображаться в Elements Organizer.
После удаления неправильно распознанных лиц нажмите кнопку Добавить имена (под стопкой).
Этим действием вы подтверждаете, что на всех фотографиях в стопке изображен пользователь, которому присваивается имя. Все лица будут перемещены на вкладку С именем.
При открытии каталога, созданного в предыдущей версии, происходит следующее:
- Все лица, которым присвоены имена пользователей в предыдущей версии, перемещаются на вкладку С именем в виде стопок.
- Elements Organizer анализирует все лица, которым не присвоены метки, и добавляет их в стопки на вкладке Без имени. Эти лица можно легко отметить, следуя инструкциям в разделе Распознавание лиц на фото на вкладке «Без имени».
- Все метки людей добавляются в категорию меток «Люди» в Elements Organizer 14.

После распознавания лиц на медиафайлах и присвоения имен людям, перейдите на вкладку С именем для последующего упорядочения этих медиафайлов.
Если человек распознан на нескольких медиафайлах, Elements Organizer автоматически определяет лучший снимок для изображения профиля.
Но вы также можете выбрать фото для изображения профиля вручную.
- Выберите из стопки фотографию, которую хотите установить в качестве изображения профиля.
- В меню «Содержимое» нажмите Назначение изображения профилю.
Подтверждение лиц
Все лица, которым присвоено имя на вкладке Без имени, отображаются в разделе Подтвержденные лица. Неотмеченные фотографии, на которых, возможно, изображен тот же человек, отображаются в разделе Это <имя человека>? (имя человека, для которого требуется подтверждение).
Чтобы подтвердить, что лица распознаны правильно, выберите лица и нажмите Подтвердить. Можно выбрать несколько лиц, удерживая клавишу Command (macOS) или Ctrl (Windows). Кроме того, лица можно выбирать щелчком мыши, удерживая клавишу Shift.
Можно выбрать несколько лиц, удерживая клавишу Command (macOS) или Ctrl (Windows). Кроме того, лица можно выбирать щелчком мыши, удерживая клавишу Shift.
Также можно выбрать одно или несколько лиц по отдельности и нажать на символ галочки для подтверждения.
Удаление лиц из стопки человека
Лица других людей можно удалить одним из 2 способов:
- С помощью команды Это другой человек
- С помощью команды Больше не показывать
Работа с этими параметрами осуществляется так же, как описано в разделах Добавление имен ранее в этом документе.
Переименование лиц
Если одно или несколько лиц распознаны неправильно, эти лица можно переименовать, нажав Переименовать.
Можно ввести существующее или новое имя.
Подтверждение новых лиц
В процессе импорта медиафайлов Elements Organizer анализирует лица. На основе этого анализа Elements Organizer может распознать в недавно импортированных медиафайлах человека, которому уже присвоено имя. В таких случаях Elements Organizer отмечает стопку этого человека значком синего цвета на вкладке С именем. Этот значок указывает, что новые распознанные лица могут соответствовать уже добавленному человеку. Нажмите стопку, чтобы отобразились все лица, затем подтвердите лица, как указано ранее в разделе Подтверждение лиц.
В таких случаях Elements Organizer отмечает стопку этого человека значком синего цвета на вкладке С именем. Этот значок указывает, что новые распознанные лица могут соответствовать уже добавленному человеку. Нажмите стопку, чтобы отобразились все лица, затем подтвердите лица, как указано ранее в разделе Подтверждение лиц.
В некоторых случаях может понадобиться объединить несколько стопок (например, если один и тот же человек был распознан как два разных человека). Чтобы объединить стопки, выполните одно из предложенных ниже действий:
- Перетащите одну стопку в другую.
- Выделите нужные стопки и выберите Объединить людей из контекстного меню.
- Выделите нужные стопки и выберите Объединить людей на панели Действие.
На вкладках «Без имени» и «С именем» можно объединить стопки.
На фотографиях и видео могут присутствовать люди, лица которых Elements Organizer не удалось идентифицировать ранее. Например, лица на фотографиях могут быть не распознаны в связи со съемкой с большого расстояния или с неподходящего угла. Таким лицам можно присвоить имя, добавив к ним метку.
Таким лицам можно присвоить имя, добавив к ним метку.
В режиме просмотра Мультимедиа дважды нажмите медиафайл с изображенным на нем лицом, которое требуется отметить.
Для фотографий на панели Действие нажмите кнопку Отметить лицо.
На экране появится прямоугольник, с помощью которого можно отметить лицо. Перетащите прямоугольник на изображение лица человека, которого требуется отметить, и нажмите на символ зеленой галочки рядом с прямоугольником. Вместо прямоугольника появится круг, указывая, что лицо отмечено. Нажмите Добавить имя.
Для видео нажмите кнопку Добавить человека.
Введите имя и нажмите клавишу Enter или Return.
Можно добавить одно или несколько имен на фотографию или видео. Воспользуйтесь одним из следующих способов:
- В контекстном меню фотографии или видеофайла выберите Добавить человека и введите имя. Повторите это действие, чтобы добавить на фотографию или видео другие имена людей.
- Перетащите имя метки (человека) из панели Метки на фотографию или видео.

При добавлении одного или нескольких имен на фотографию или видео этим способом имена отображаются в виде обычного значка в форме лица на вкладке С именем в режиме просмотра Люди. Например, если вы добавили имена «Нита» и «Вальтер» на фотографию нажатием кнопки Добавить человека или путем перетаскивания меток к фотографиям, напротив этих имен на вкладке С именем отображается обычный значок в форме лица.
Этот значок отображается, потому что при добавлении имен таким способом одна фотография или одно видео могут быть связаны с несколькими людьми. Поэтому метка применяется ко всему медиафайлу, а не к определенному лицу.
Систематизация медиафайлов по группам позволяет усовершенствовать распознавание лиц на медиафайлах. При выборе определенной группы отображаются соответствующие стопки медиафайлов с изображением людей. Например, можно создать группу с именем «Работа» и присвоить соответствующие метки медиафайлам с изображением сотрудников.
Нажмите значок «Группы» в правом нижнем углу экрана.
Панель «Группы» служит для добавления и систематизации групп. Нажмите кнопку добавления (+) для создания новой группы людей. По умолчанию созданы три группы: коллеги, семья и друзья.
Введите имя группы.
Для создания дочернего элемента или подгруппы существующей группы выберите ее в раскрывающемся списке «Группа». При создании новой группы не выбирайте ничего в списке «Группа». Введите имя группы.
Нажмите кнопку «ОК».
Добавление пользователей в группу путем перетаскивания
Лица людей можно добавить в группу одним из следующих способов.
- Выберите одну или несколько стопок и перетащите их на имя группы на правой панели.
- Выберите одну или несколько стопок и перетащите имя группы на одну из стопок.
Можно выключить или сбросить анализ лиц в Elements Organizer > Редактирование > Установки > Анализ мультимедиа (Windows) или Elements Organizer > Установки > Анализ мультимедиа (macOS).
Выключение анализа лиц
Elements Organizer автоматически распознает похожие лица и группирует их в стопки. Чтобы отключить автоматическое распознавание лиц на фотографиях и видео, снимите флажки Фото или Видео соответственно.
Сброс анализа лиц
В случае сброса анализа лиц Elements Organizer повторно анализирует все лица в каталоге. При сбросе анализа лиц все существующие стопки, связанные с людьми на вкладке С именем, удаляются. Elements Organizer повторно анализирует лица в текущем каталоге и отображает похожие лица в виде стопок на вкладке Без имени, где им можно присвоить имена.
Чтобы сбросить анализ лиц, нажмите кнопку Сбросить анализ лиц.
Справки по другим продуктам
- Распознавание людей на фотографиях и создание групп людей | Elements Organizer 13
opencv — Как я могу сравнить изображение, чтобы идентифицировать человека на изображении?
Хорошо, давайте попробуем.
Довольно типичным методом является использование так называемых собственных граней. В OpenCV есть целый раздел о распознавании лиц с использованием EigenFaces и аналогичных подходов, которые можно найти по адресу http://docs.opencv.org/modules/contrib/doc/facerec/facerec_tutorial.html
В OpenCV есть целый раздел о распознавании лиц с использованием EigenFaces и аналогичных подходов, которые можно найти по адресу http://docs.opencv.org/modules/contrib/doc/facerec/facerec_tutorial.html
. Но это предполагает, что у вас есть база данных изображений для использования ( но это не плохое место для начала поиска).
Метод с использованием черт лица/изображения:
Этот метод не обязательно настолько эффективен, поскольку он зависит от того, насколько эффективен ваш расчет определенных функций. И точность этого метода зависит от того, насколько хорошо вы определяете свои функции и их весовые коэффициенты. Но, тем не менее, это метод, который не обязательно требует машинного обучения. (хотя это, безусловно, помогло бы!)
Другой способ — попытаться сравнить, насколько похожи исходное и целевое лицо. Это можно сделать, сравнив набор признаков.
Первое, что вам нужно сделать, это решить, содержит ли целевое изображение лицо. Видеть
http://docs.opencv.org/master/d7/d8b/tutorial_py_face_detection.html
или вы можете реализовать алгоритм Виолы-Джонса, найденный здесь.
Видеть
http://docs.opencv.org/master/d7/d8b/tutorial_py_face_detection.html
или вы можете реализовать алгоритм Виолы-Джонса, найденный здесь.
Теперь, если ваш алгоритм распознавания лиц еще не делает этого, вам нужно найти ориентацию, масштаб и положение вашего целевого лица (это будет полезно для поиска определенных характеристик лица человека).
Теперь вам нужно рассчитать черты вашего целевого лица. Вы можете использовать функции изображения и дескрипторы, такие как Fast, SIFT и ORB, для вычисления характеристик изображения и сравнения. см. http://docs.opencv.org/master/dc/dc3/tutorial_py_matcher.html
Или, поскольку вы знаете, как обращаться с лицами, вы можете вычислить признаки, которые помогут различать людей. Примеры:
Расстояние между глазами, форма лица. Длина носа. Высота глаз. расстояние между носом и ртом и т. д.
Сложность заключается в том, чтобы выяснить, как надежно рассчитать метрики признаков, а затем объединить их все в единую метрику. Алгоритмы машинного обучения обычно используются для поиска весовых коэффициентов для объединения каждой метрики.
Алгоритмы машинного обучения обычно используются для поиска весовых коэффициентов для объединения каждой метрики.
Но вы можете использовать некоторые догадки, чтобы выбрать начальные веса, а затем методом проб и ошибок, пока не найдете набор весов, которые вам подходят.
После того, как вы определили веса, вы можете объединить их, найдя квадрат разницы между исходными и целевыми объектами и сложив их все вместе. (это лучше всего работает, если сначала нормализовать все подфункции (т. е. всегда в диапазоне от 0 до 1) и взвесить так, чтобы общая метрика находилась в диапазоне от 0 до 1.
Допустим, у вас есть 5 функций f0, f1, f2, f3, f4, f5 все от 0 до 1 Эти значения представляют собой нормализованную квадратную разницу между исходным и целевым лицом.
и у вас есть 5 весовых коэффициентов: 0,3, 0,1, 0,15, 0,25, 0,2 (сумма до 1)
ваш общий показатель будет
Общий показатель = 0,3 * f0 + 0,1 * f2 + 0,15 * f3 + 0,25 * f4 + 0,2 * f5
Тогда два лица более похожи, если значение ближе к 0, и менее похожи, если значение ближе к 1. В приведенном выше примере функция 0 является наиболее значимой функцией, а функция 2 — наименьшей.
В приведенном выше примере функция 0 является наиболее значимой функцией, а функция 2 — наименьшей.
17 лучших инструментов распознавания изображений
Бренды могут использовать обнаружение изображений, чтобы узнать, где их видят потребители. Без этой информации бренды могут быть слепы к потоку угроз и возможностей, направленных на них каждый день. Получив эти изображения, вы сможете провести анализ, лучше понять свой бренд, узнать своих клиентов и улучшить свою маркетинговую стратегию.
Интернет говорит не только словами, но и образами, поэтому недостаточно просто искать ключевые слова в онлайн-разговорах. Защита авторских прав бренда, наблюдение за тем, где ваши изображения используются (и неправомерно), и расширение вашей сети электронной коммерции — все это веские причины, по которым вам может понадобиться программное обеспечение для распознавания изображений.
Без технологии обнаружения изображений вы не увидите 80% изображений, на которых не упоминается ваш бренд в тексте. С тем же успехом вы могли бы идти вслепую. Более того, эти инструменты могут сделать эту работу в кратчайшие сроки.
С тем же успехом вы могли бы идти вслепую. Более того, эти инструменты могут сделать эту работу в кратчайшие сроки.
Используя одну из этих платформ в качестве бренд-менеджера или коммерческого директора, вы можете получить глубокое представление о том, как ваш бренд или продукт представлен в Интернете, и какие проблемы вам, возможно, придется решить.
Если вы новичок в распознавании изображений, этот блог вам пригодится. При поиске инструмента рекомендуется попробовать несколько из них и выбрать тот, который лучше всего соответствует вашим потребностям.
- Как выбрать средство распознавания изображений
- Средства распознавания изображений
Как выбрать средство распознавания изображений
Для начала задайте себе шесть ключевых вопросов, прежде чем выбрать средство распознавания изображений. Все они имеют сильные и слабые стороны, так что это поможет вам найти именно то, что вам нужно.
1. Можно ли найти любой логотип?
Гибкость и выбор очень важны. Некоторые службы будут иметь ограниченное количество логотипов, которые вы можете искать, в то время как другие позволят вам выбрать любой из них (включая варианты логотипа).
Некоторые службы будут иметь ограниченное количество логотипов, которые вы можете искать, в то время как другие позволят вам выбрать любой из них (включая варианты логотипа).
2. Можете ли вы найти мелкие части логотипа?
Логотипы часто могут быть нечеткими или крошечными на изображениях. Узнайте, может ли инструмент, на который вы смотрите, справиться с этими ситуациями, не обнаружив ваш логотип.
3. Сколько времени занимает добавление нового логотипа?
Некоторым службам может потребоваться много времени для обнаружения логотипа (в некоторых случаях пять недель). Скорость важна, особенно для отслеживания разговоров в реальном времени.
Другие инструменты могут отслеживать ваш логотип всего за несколько часов или, самое большее, несколько дней (например, наше предложение Image Insights).
4. Какова частота ложноположительных результатов?
Ложноположительный результат — это неправильное обнаружение логотипа на изображении, например, когда инструмент считает, что логотип присутствует, когда его нет. Обязательно изучите это при выборе инструмента, поскольку частота ложноположительных результатов зависит от технологии.
Обязательно изучите это при выборе инструмента, поскольку частота ложноположительных результатов зависит от технологии.
5. Можете ли вы сравнить темы разговора между изображениями и текстовыми упоминаниями?
Очень важно иметь возможность сравнивать и сопоставлять данные изображений и текстовых упоминаний в одном месте. Это означает, что вы можете получить полную картину, видя, как различаются два типа.
6. Позволяет ли инструмент искать логотипы без использования ключевых слов?
Некоторые платформы могут идентифицировать упоминания изображения только в связи с определенными ключевыми словами, указанными пользователем. Это означает, что вы пропустите много упоминаний.
Вот почему вам нужно инвестировать в платформу, которая дает вам полный доступ к упоминаниям вашего логотипа и логотипов ваших конкурентов, даже если к нему не прикреплен текст. В возможности поиска логотипа только по изображению нет ничего нового, но технология постоянно совершенствуется, и теперь можно найти изображения, на которых есть только небольшой фрагмент логотипа.
Лучшие инструменты распознавания изображений
Поиск изображений для логотипов обычно является первым шагом, который предпринимают маркетологи и бренд-менеджеры при распознавании изображений. Это хлеб с маслом для понимания того, как бренд представлен в Интернете. Логотип компании будет появляться везде — на собственном веб-сайте и в социальных сетях, на сайтах обзоров, новостных статьях и даже на доменах конкурентов. Скорее всего, вы даже найдете упоминания, о которых не знали.
Вдобавок ко всему, вам может понадобиться отследить неожиданные места появления вашего бренда, основать кампанию на основе визуальных эффектов или убедиться, что фотографии вашего продукта правильно подбираются поисковыми системами с распознаванием изображений продукта.
В прошлом вам приходилось полагаться на замещающий текст внутри изображения, чтобы найти его. Это означало полагаться на то, что кто-то действительно добавит замещающий текст при загрузке изображения, что происходит не всегда. Разработка программного обеспечения и интеграция искусственного интеллекта за последнее десятилетие означают, что распознавание изображений теперь возможно без прикрепления текста. Это открывает совершенно новый мир доступного анализа, в который каждый маркетолог будет стремиться погрузиться.
Разработка программного обеспечения и интеграция искусственного интеллекта за последнее десятилетие означают, что распознавание изображений теперь возможно без прикрепления текста. Это открывает совершенно новый мир доступного анализа, в который каждый маркетолог будет стремиться погрузиться.
Распознавание изображений становится полем конкуренции, и существуют инструменты, которые помогут вам организовывать, анализировать и расставлять приоритеты визуальных элементов так же, как мы в настоящее время тщательно изучаем текст с помощью инструментов социального прослушивания.
В этом блоге мы рассмотрим основные инструменты распознавания изображений и выберем то, что больше всего соответствует потребностям бренда.
Компания Google разработала одну из самых быстрых платформ распознавания изображений, доступных веб-пользователям. Обновление ваших знаний о том, насколько мощным может быть знакомый инструмент, является отличной отправной точкой для тех, кто хочет быстро получить представление о том, насколько широко их бренд или продукты распространились в Интернете.
Инструмент распознавания изображений Google классифицирует неподвижные и движущиеся изображения. С момента запуска в 2014 году он был доработан, чтобы отказаться от замещающего текста. Он позволяет использовать изображения не только на веб-сайтах, но и в социальных сетях.
Google Image Search — бесплатный инструмент. Вы можете получить к нему доступ, щелкнув «Изображения» Google, а затем используя значок камеры в строке поиска.
Компания Google также запустила приложение для распознавания изображений под названием Google Lens. Вы можете прочитать больше о Google Lens ниже.
Неудивительно, что мы упоминаем здесь наш собственный инструмент, потому что мы считаем, что наша команда инженеров разработала лучшее в мире программное обеспечение для распознавания изображений.
Brandwatch находится в авангарде распознавания изображений с тех пор, как команда впервые создала наше программное обеспечение еще в 2017 году, и оно идеально подходит для маркетологов и бренд-менеджеров. Вы можете использовать его для сбора и анализа изображений, содержащих ваш бренд, понимания вашей аудитории и определения хороших (и плохих) тенденций до того, как они станут вирусными. Brandwatch Image Insights — ведущий мировой инструмент, оптимизированный для брендов и агентств.
Вы можете использовать его для сбора и анализа изображений, содержащих ваш бренд, понимания вашей аудитории и определения хороших (и плохих) тенденций до того, как они станут вирусными. Brandwatch Image Insights — ведущий мировой инструмент, оптимизированный для брендов и агентств.
После независимого сравнительного анализа технологии наши клиенты обнаружили, что она:
- В 2 раза точнее, чем у ближайшего конкурента
- В 10 раз шире, чем у ближайшего конкурента
- Единственный инструмент, который может отслеживать любой логотип бренда
Amazon погрузилась в игру распознавания изображений в 2016 году, когда она запустила свой инструмент Rekognition, который в основном фокусируется на распознавании лиц при анализе изображений и видео. Из-за этого Rekognition был продан системам безопасности и правительствам по всему миру.
Но Rekognition можно использовать и как идентификатор логотипа. Он использует модели глубокой нейронной сети для обнаружения и маркировки тысяч объектов и сцен на ваших изображениях. Однако он может анализировать только предоставленные вами изображения, а это означает, что если вы хотите найти логотип Nike, вам сначала придется загрузить его тысячами изображений, связанных с Nike.
Однако он может анализировать только предоставленные вами изображения, а это означает, что если вы хотите найти логотип Nike, вам сначала придется загрузить его тысячами изображений, связанных с Nike.
Если вы используете в своих кампаниях узнаваемых фигур, таких как знаменитости или влиятельные лица, это также очень удобно для подбора изображений и видео, в которых они появляются.
Разработчики и исследователи используют Clarifai для создания приложений и управления данными. Clarifai — один из самых точных готовых API-интерфейсов для распознавания изображений, который помогает вам помечать, систематизировать и интерпретировать данные. Он может просеивать неструктурированные изображения, видео, текст и аудио, а его программное обеспечение позволяет организовать весь набор данных.
Это может быть очень полезно для исследования рынка, если вы пытаетесь понять, как тема или аудитория распространяются в Интернете, или получить представление о новой теме. Вы также можете быстро и легко модерировать контент, научив его ИИ распознавать то, что вы не хотите видеть.
Вы можете протестировать платформу распознавания изображений Clarifai с помощью бесплатного подключаемого модуля API, чтобы убедиться, насколько мощным является этот инструмент.
Google будет упоминаться в этой статье несколько раз, и Google Vision AI делает шаг вперед, чем простой поиск изображений. Машинное обучение позволяет либо обучать собственные модели изображений, либо использовать предварительно обученную платформу Google.
Идея состоит в том, чтобы эффективно классифицировать и хранить тысячи изображений, а также легко проводить проверку качества и поиск товаров. Просто подключите источники изображений, и Vision проанализирует их и расскажет, что они из себя представляют.
Каждому изображению присваиваются ярлыки, похожие лица и объекты классифицируются вместе, и вы даже можете увидеть, насколько видно ваше изображение в безопасном поиске. Это означает, что вы можете анализировать свой собственный контент и контент вашего конкурента, чтобы увидеть, на что реагируют разные аудитории, или почувствовать, чем новая аудитория хочет поделиться.
Вы можете попробовать инструмент бесплатно, как мы сделали с изображением пляжа ниже.
GumGum предоставляет брендам и рекламодателям интеллектуальную платформу для создания рекламы в картинках. Несколько лет назад компания разработала инструмент распознавания изображений, который может находить фотографии в Интернете, в том числе в социальных сетях, которые имеют отношение к вашему бренду.
Это означает, что бренд-менеджер может найти изображения в социальных сетях, таких как Twitter или Instagram, которые включают их бренд или продукт, и добавить их в свою собственную кампанию, сэкономив при этом много времени.
Программное обеспечение GumGum для идентификации брендов является частью общего пакета средств размещения и анализа рекламы как для рекламодателей, так и для издателей.
VISUA начиналась как LogoGrab, компания, созданная бывшими сотрудниками Google, которые поняли, что бренды отстают в своем визуальном маркетинге и защите авторских прав. Они создали это мощное программное обеспечение, которое идентифицирует знаки и логотипы на изображениях. Эта технология настолько мощная, что может даже найти части логотипа и обнаружить его неправильное использование.
Они создали это мощное программное обеспечение, которое идентифицирует знаки и логотипы на изображениях. Эта технология настолько мощная, что может даже найти части логотипа и обнаружить его неправильное использование.
В 2020 году компания расширила свой технический набор за пределы поиска по логотипу бренда, включив в него визуальный ИИ. Теперь, наряду с идентификатором логотипа, VISUA может выполнять визуальный поиск, обнаружение текста, обнаружение пользовательских объектов, а также обнаружение объектов и сцен. Это отлично подходит для отслеживания изображений, которые могли быть изменены как часть мема или с помощью фильтров.
Brandwatch и VISUA недавно объединились для разработки платформы, идеально подходящей для социальных сетей, но их собственная запатентованная технология является ведущей в мире для поиска изображений и видео.
Технология обнаружения изображений IBM находится в пакете IBM Cloud и помогает брендам понять содержание изображений, что полезно для анализа предыдущих кампаний и маркетинговой деятельности. Например, он может находить человеческие лица, приблизительный возраст и пол, распознавать продукты питания, действовать как идентификатор бренда и находить похожие изображения в коллекции.
Например, он может находить человеческие лица, приблизительный возраст и пол, распознавать продукты питания, действовать как идентификатор бренда и находить похожие изображения в коллекции.
Более того, вы можете классифицировать изображения и создавать наборы данных, чтобы лучше понять ваш контент. Звучит здорово, правда? Бренды также могут обучить эту технологию, создав специальное обнаружение для поиска типа одежды в розничной торговле, выявления испорченных фруктов в инвентаре и т. д.
IBM предлагает свои технологии трех уровней: Lite, Standard и Premium. Даже версия Lite позволяет обнаруживать 1000 изображений в месяц на пользовательских и предварительно обученных моделях.
Imagga — это универсальная платформа для распознавания изображений, которая превосходно подходит для категоризации. Его API можно настроить для создания мгновенных данных организации изображений, которые маркетологи могут использовать при планировании стратегии.
Распознавание лиц, модерация контента для взрослых NSFW и визуальный поиск также являются частью пакета Imagaa, что означает, что вы можете прорваться через шум, чтобы найти изображения, которые действительно резонируют с тем, что вы пытаетесь обнаружить.
Но, пожалуй, наиболее практичными преимуществами пакета Imagaa являются функции обрезки и цвета, которые могут преобразить ваши изображения на основе результатов вашего уже основательного исследования.
Это не кричаще, но Filestack может обрабатывать большие пакеты изображений и быстро обрабатывать, маркировать и классифицировать файлы по понятным группам. Он интегрируется со службами обмена файлами, поэтому даже новичок в распознавании изображений может просматривать множество изображений, скажем, с мероприятия или нового клиента, и классифицировать их на другом конце.
Быстрый и эффективный Filestack предлагает различные методы загрузки изображений, а его функция многокомпонентной загрузки позволяет пользователям загружать изображения небольшими и более управляемыми фрагментами. Если вы имеете дело с огромным количеством изображений для брендов или маркетинговых кампаний, это сэкономит вам огромное количество времени.
Microsoft Azure Custom Vision — одно из самых гибких программ для распознавания изображений. Это требует, чтобы вы построили свою собственную модель из исходных блоков всего нескольких изображений. Оттуда вы можете позволить ему работать бесплатно, используя его возможности машинного обучения, которые могут делать такие вещи, как классифицировать изображения и действовать как поиск логотипа по изображению.
Это требует, чтобы вы построили свою собственную модель из исходных блоков всего нескольких изображений. Оттуда вы можете позволить ему работать бесплатно, используя его возможности машинного обучения, которые могут делать такие вещи, как классифицировать изображения и действовать как поиск логотипа по изображению.
Пользователи могут полагаться на гибкий интерфейс Azure Custom Vision для навигации по этому программному обеспечению, даже если у вас нет формального обучения. После чего вы можете передавать информацию на другие устройства для запуска распознавания изображений в реальном времени.
Microsoft также позволяет пользователям развертывать Project Trove — биржу, соединяющую разработчиков искусственного интеллекта и фотографов — для сбора ваших изображений и передачи их в Custom Vision. Программное обеспечение для распознавания форм, распознавания лиц, индексации видео и модерации контента также доступны под эгидой Microsoft Cognitive Services.
Подробная маркировка изображений жизненно важна для правильной классификации большого количества изображений. А программное обеспечение V7 для аннотаций AI позволяет пользователям быстро классифицировать изображения на изображениях, выявлять проблемы с качеством и экономить сотни часов умственных усилий.
А программное обеспечение V7 для аннотаций AI позволяет пользователям быстро классифицировать изображения на изображениях, выявлять проблемы с качеством и экономить сотни часов умственных усилий.
Личная аннотация изображения внутри изображения — например, обведение линии вокруг объекта, такого как яблоко в миске с различными фруктами, — занимает в среднем 42 секунды. С V7 это занимает 13 секунд. Если у вас или у сотрудника есть 10 000 изображений для аннотирования, это сэкономит много секунд.
Идеально подходит для дизайнеров, медицинская промышленность также использует V7 для аннотирования рентгеновских снимков. Более того, вы можете хранить всю свою информацию в наборе данных V7.
Visio — это программное обеспечение для распознавания видео, которое предприятия могут использовать для выявления повседневных закономерностей и повышения эффективности. Например, распознавание скопления пешеходов на тротуарах на определенных перекрестках или почему больше автомобилей используют определенный насос на заправочной станции чаще, чем другие.
Его мощное программное обеспечение для распознавания человека отслеживает, обновляет и создает данные, которые приводят к действенным решениям. Это может быть удобно для отслеживания ваших OOH-кампаний или мониторинга мероприятия, которое вы организуете.
Superannotate — это «другое» программное обеспечение для аннотирования изображений, которое часто сравнивают с V7, и технология фактически такая же. Эффективные аннотации к изображениям, видео и тексту означают, что вы можете создавать высококачественные наборы данных без необходимости просматривать каждый элемент.
Оттуда вы можете понять тенденции в ваших изображениях, видео и письменном тексте, организовать кампании и посмотреть, какие изображения более успешны. Это прекрасно для анализа.
Как и в V7, вы можете контролировать проекты по управлению качеством, чтобы наборы данных, которые вы предоставляете, были идеально сглажены.
В индустрии розничной торговли каждый год обрабатываются миллиарды изображений продуктов, и даже небольшие компании могут испытывать трудности с категоризацией, тем более, что COVID-19 привел к росту бизнеса в Интернете, чем когда-либо. Vue.ai помогает розничным фирмам разрабатывать свою стратегию управления контентом, модерируя качество изображений, теги продуктов и таксономию.
Vue.ai помогает розничным фирмам разрабатывать свою стратегию управления контентом, модерируя качество изображений, теги продуктов и таксономию.
Объедините это с системой управления качеством обслуживания клиентов Vue.ai и ее программным обеспечением для автоматизации розничной торговли, которое позволяет брендам создавать виртуальные примерочные и автоматизировать фотографирование продуктов, и вы сможете изменить способ управления и расширить свой сайт электронной коммерции.
Syte — еще одна платформа для розничной торговли, которая использует свой инструмент распознавания изображений, чтобы помочь покупателям найти товары, которые они хотят купить. Подробные теги и описания продуктов быстро улучшают возможности поиска изображения, благодаря чему оно выделяется среди тысяч похожих изображений.
Отсюда маркетологи могут использовать Visual Discovery Suite для идентификации розничных товаров на изображении и сопоставления их со своими продуктами. Используя поиск с камеры, визуальный ИИ распознает продукты, пол, возраст и многое другое, чтобы направить покупателей к тому, что они действительно ищут. Это важно в постоянно растущем мире онлайн-покупок, чтобы помочь вашим клиентам найти ваши продукты как можно проще.
Это важно в постоянно растущем мире онлайн-покупок, чтобы помочь вашим клиентам найти ваши продукты как можно проще.
17. Google Lens
Google Lens находится в приложении Google.com и является мечтой покупателя, предлагая «обратное» распознавание изображений, предоставляя данные, связанные с изображением. Вы можете быстро сфотографировать сумочку, которую кто-то держит в метро, или пару кроссовок, и увидеть их и аналогичные товары, доступные для покупки в Интернете.
Это распознавание изображений, ориентированное на покупателя, которое выходит далеко за рамки розничной торговли. Переводите языки, фотографируйте текст, мгновенно отвечайте на вопросы «что это за логотип», узнавайте о достопримечательностях рядом с вами и даже фотографируйте меню, чтобы получить изображение каждого блюда.
Также можно искать сохраненные изображения на вашем телефоне через Google Lens, который обходит базовый ИИ телефона, который группирует изображения в папки. Понимание того, как ваши продукты отображаются в этом приложении, является новой частью SEO, которая вскоре может изменить то, как компании представляют изображения и логотипы — от цвета и деталей в изображениях брендов до моделей, используемых в фотосессиях.
