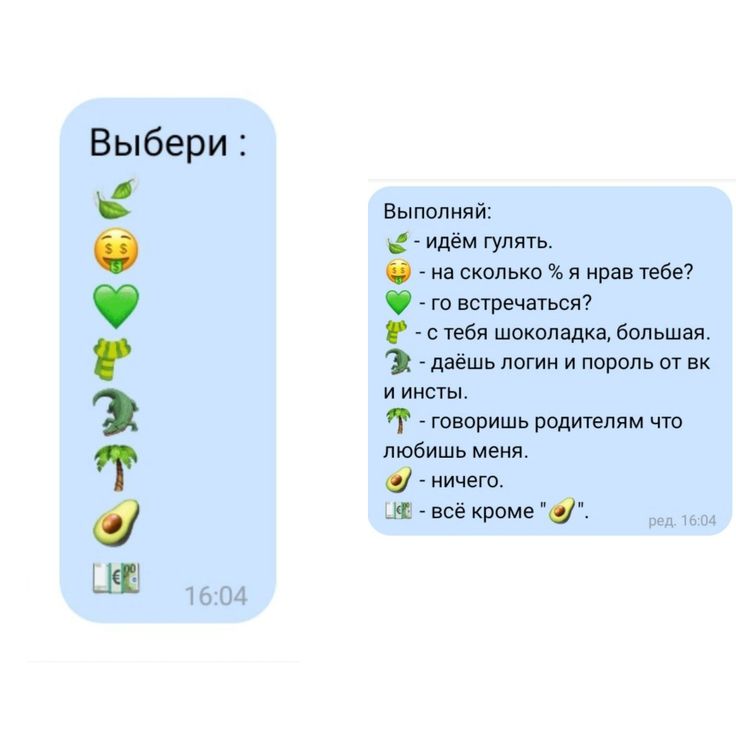
Игра Выбери смайл
Графики роста подписчиков
Лучшие посты
Перейти к посту
Привет-Привет!
Как ваши дела?)
С вами я(Лемурр~)
Админу счастья и добра)
По старинке,анон)
492 74 1 ER 0.1221
Перейти к посту
Девочки это для вас если вы общаетесь с мальчиком который находится не рядом:(
-Делать ещё такие? 🥺
399
167
4
ER 0. 1229
1229
Перейти к посту
Не анон.. хз что это🗿 для парней… И девушек….
358 98 10 ER 0.1010Перейти к посту
Анон))
(Для лд,лп,парня,краша)*^*
(Простите за ошибки)^_^
267
88
4
ER 0. 0777
0777
Перейти к посту
Хороший способ проверисти время с другом/подругой
Можно анон
260 69 1 ER 0.0710
Перейти к посту
Делала 1 раз
Надеюсь пропустишь
P. S Админу печенек☺
S Админу печенек☺
245 62 0 ER 0.0661
Перейти к посту
Приветик, можно анонимно?
Админу денюжек и любви️
191
44
0
ER 0.
Перейти к посту
для интернет друзей)
анонимно пожалуйста🤟
делать ещё?
146 52 0 ER 0.0427
Перейти к посту
Как вам?)
Делала 1 раз, и это больше для друзей))
123
58
2
ER 0.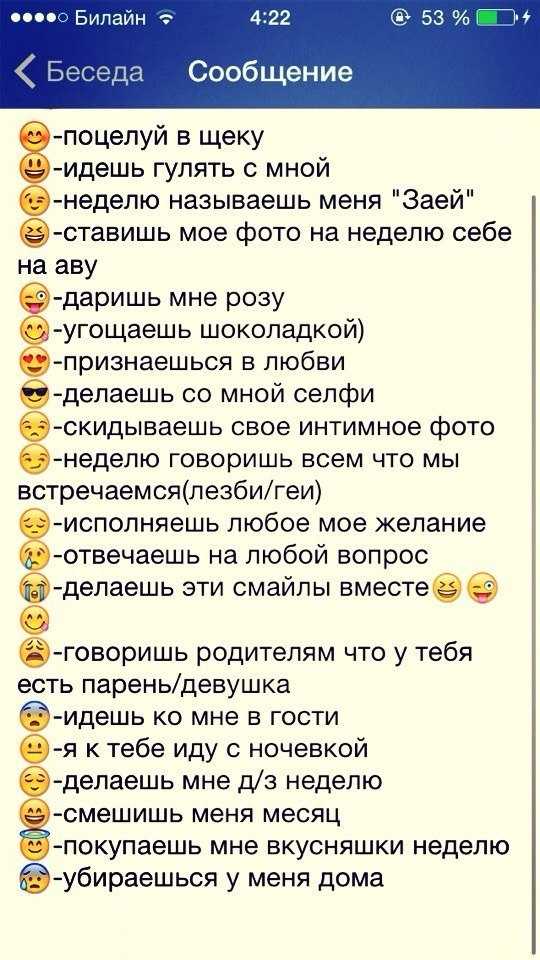 0396
0396
Перейти к посту
А это опять я,в прошлый раз Т9 написал «Антон»,хотя я хотела написать Анон. Админушка, выложи пожалуйста анонимно, спасибо!
98 22 0 ER 0.0258
Групповое коррекционно-развивающее занятие с обучающимися с задержкой психического развития.

Групповое коррекционно-развивающее занятие с обучающимися с задержкой психического развития.
Тема: «Развитие произвольного внимания, зрительной и слуховой памяти.
Автор: Лисасина Олеся Владимировна педагог-психолог
Место работы: Муниципальное образовательное учреждение Иркутского районного Муниципального образования «Мамоновская средняя общеобразовательная школа»
Количество обучающихся: 8 человек (учащиеся 3 — 4 классов)
Продолжительность занятия : 30 мин.
Цель: развитие произвольного внимания, зрительной и слуховой памяти.
Задачи:
- Научить обучающихся концентрировать свое внимание на определенных предметах, объектах.
- Развивать навыки устойчивости, переключения и распределения внимания.
- Развивать волевую сферу
Используемые методы; наглядные, словесные, практические, игровые
Оборудование: Карточки,
тетради, ручки, запись на доске, мяч, презентация, фишки.
Предварительная работа: Психологический настрой
Здравствуйте! Я рада приветствовать вас! Давайте поприветствуем друг друга и наших гостей. Присаживайтесь.
Педагог: “Дети, посмотрите друг на друга и подарите друг другу свои улыбки, затем закройте глаза. Повторяйте за мной: “Я сижу на уроке. Мне хорошо и спокойно. У меня хорошая память, я быстро все запоминаю. Сейчас я начну работа. У меня все получится”.
Мы сейчас с вами провели небольшое психологическое упражнение и настроились на работу в позитивном ключе, а сейчас мы с вами попробуем настроить на работу все клетки нашего головного мозга.
Ход занятия:
Вводная часть
Разминка Упражнение “Ленивые” восьмерки”
Встаньте пожалуйста . Ученики “рисуют” поочередно две вертикальные “восьмерки” и две горизонтальные “восьмерки”:
- Указательным
пальцем правой руки, следя глазами за кончиком пальца.

- Указательным пальцем левой руки, следя глазами за кончиком пальца.
- Указательными пальцами обоих рук, следя глазами за кончиками пальцев.
- Массаж БАТ — массировать точки по 10 сек (мочки ушей, крылья носа, за ухом ямочки, точка между глаз над переносицей «третий глаз», тремя пальцами (указательным, средним и безымянным).

Создаем хорошее настроение.
Составляем «Азбуку хороших слов»: вспомни добрые, хорошие слова на букву «У» (умный, убедительный, уважаемый, уверенный, увлеченный, удалой, умелый, успешный).
Основная часть
- Вызов.
Педагог:– Ребята, вы, любите соревноваться? (Да!)
– Сегодня, предлагаю побороться вам за звание “Самого внимательного” и получить медаль за Внимание и хорошую память. Медаль получит тот, кто наберет больше жетонов за правильные ответы.
Упражнение,
подводящее к теме урока: «Будь внимателен».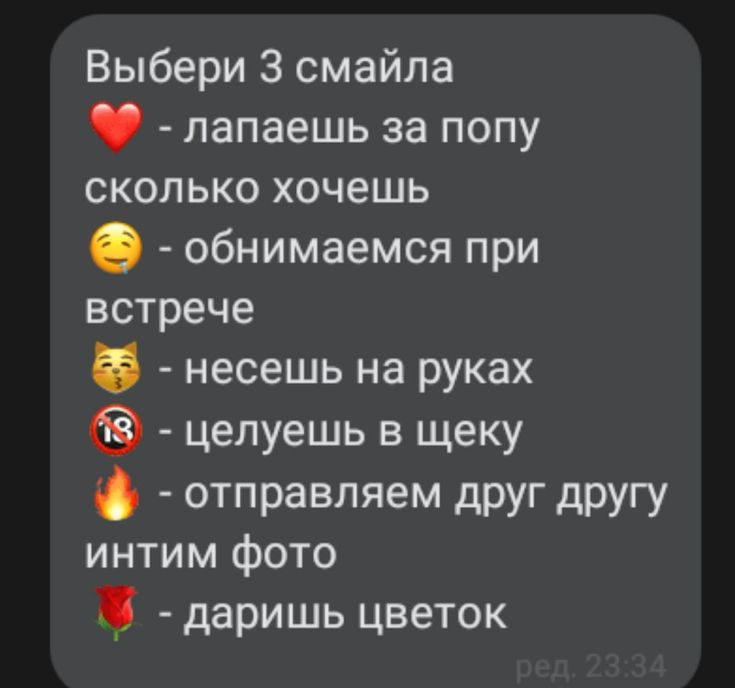 У
вас в руках я вижу карточки, они сейчас пригодятся вам.
У
вас в руках я вижу карточки, они сейчас пригодятся вам.
Задание: «Я буду говорить предложения и если вы согласны со мной, вы должны поднять зеленую карточку, а если нет ,тогда красную»
Предупреждаю, что темп нашей разминки будет быстрый. Итак, начинаем!
Вопросы
- Ворона — перелетная птица?
- Осенью иногда идет дождь?
- Мячик квадратный?
- На улице лето?
- Вода мокрая?
- Два плюс два равно три?
- Все птицы летают?
- Соль сладкая?
- Зимой постоянно идет снег?
- Чай всегда горячий?
Обсуждение.
А теперь ответьте, что мы с Вами сейчас делали?
А как Вы думаете, мы просто играли, или у меня был скрытый интерес?
Да, вы правы: это было упражнение, направленное на развитие внимания.
-Какой процесс помог вам верно ответить на вопросы? (внимание,
память).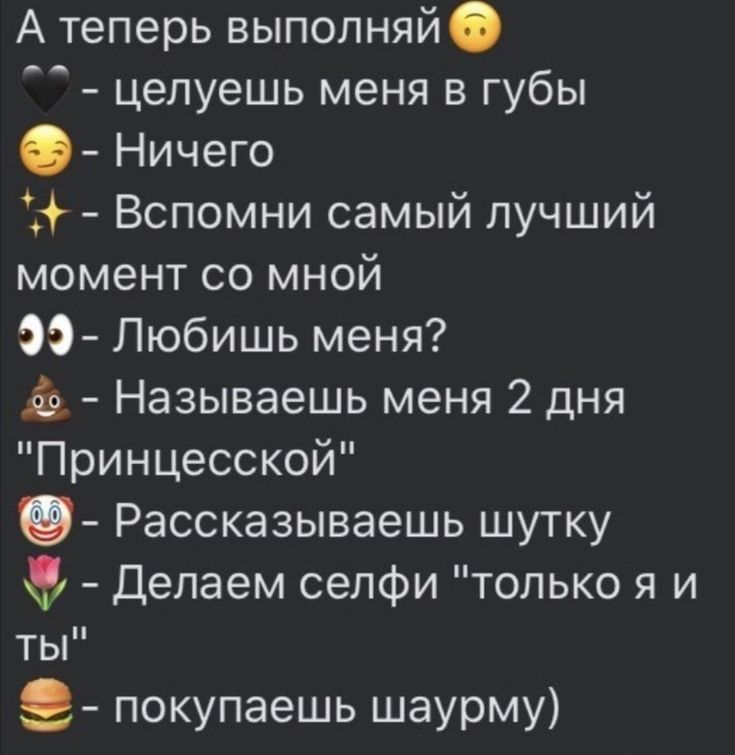 Тема нашего сегодняшнего занятия – развитие внимания. Развитие
произвольного внимания тесно переплетается с развитием запоминания, поэтому в
таких играх ставится задача и на запоминание.
Тема нашего сегодняшнего занятия – развитие внимания. Развитие
произвольного внимания тесно переплетается с развитием запоминания, поэтому в
таких играх ставится задача и на запоминание.
Как вы считаете, каковы цели нашего занятия? Чем мы будем заниматься?
Верно, на сегодняшнем занятии продолжим развивать внимание, продолжим учиться его переключать, распределять, кроме того, будем развивать мелкую моторику, поработаем в парах.
—
Назовите сегодняшнее число. Месяц (декабрь). Какой это месяц по счету? (12) От
какого месяца мы ведем отчет? (январь). Какой месяц будет после февраля?
(март). Какой по счету будет март? (третий)
2.Упражнение на развитие произвольного внимания
« Сосчитай все слоги» На листочках написаны различные слоги. Количество может меняться. Задание: найти все слоги, например, БА. Можно провести как соревнование «Кто быстрее?»
3.Физминутка. Зрительная гимнастика.
- Используйте свой нос в качестве карандаша и напишите в воздухе свое полное имя с закрытыми глазами
- Носом
на потолке, затем на полу.
- Легкими прыжками восьмерками.

4. Найду букву»
Детям раздаются по листку бумаги, на котором нарисованы хаотично согласные и гласные буквы, и выполняют следующие действия:
- Подчеркнуть, синим карандашом согласные буквы, кранным гласные, цифры простым
- Отметить сначала первую букву своего имени, своей фамилии,
- Найди не правильную букву.
5. Упр. по методике Р.С. Немова «Запомни предложение». Пиктограммы
«Сейчас Я буду называть тебе разные слова и предложения, и после этого делать паузу. Во время этой паузы ты должен будешь на листе бумаги нарисовать что-нибудь такое, что позволит тебе запомнить и затем легко вспомнить те слова, которые я произнесла. Постарайся рисунки делать как можно быстрее».
Ребенку последовательно одно за другим зачитываются следующие слова и выражения:
Дом.
Палка. Дерево. Прыгать высоко. Солнце светит. Веселый человек. Дети играют в
мяч. Лодка плывет по реке.
Лодка плывет по реке.
5. Упражнение «Наблюдательность».
Ребёнку предлагается по памяти подробно описать то, что он видел много раз: школьный двор, путь из дома в школу и т.п. Тренируется внимание и зрительная память.
Упражнения, направленные на развитие мышления
6.ФИЗМИНУТКА. Упражнение на коррекцию внимания и формирование межполушарного комиссура “ухо – нос” 3–4 раза (дети выходят в круг).
7. «Превращения слов» Предлагается ряд слов, их нужно :
-превратить в «большие» (глаза — глазище), «маленькие» (стол – столик),
— превратить в похожие слова по смыслу ( алый-красный, бежать-нестись, мчаться, белый-белоснежный, бросать-кидать, метать.)
— превратить в «слова – наоборот» (близко-далеко, длинный-короткий, легкий-тяжелый, помнить-забывать)
8.Расставь числа в порядке возрастания.
9 | 29 | 3 | 27 | ||||
7 | 23 | 4 | 21 | ||||
1 | 11 | 20 | 5 | ||||
6 | 9 | 18 | 10 |
9. Найди слова и подчеркни их:
Найди слова и подчеркни их:
АпарвпаекпвауккапустаимрспвкцаыфвсчждгшогородисмвакывуавкывмсрмиптобедимтспсарвнкпваукнастроениемсачвфцйыфчяыфйябедарптиьмлагкрвеуаыкрекламаимпспамэжхзъжэдхщзжджизньюбжлддлщшзодолкрасотамсавкупрарпэжхзъщшжлдздшлакждзщхджлэьюдобротабтьилоддхщжлзлдеревоьтбтдощгдоьзолжлдпожардюждзщхлжоэодлщштыкваблдлзшщгшщнрудцдцжцжыурокимрплдпнпнрерпнапдругжыавкуавсобакамвавкуавКазахстанмсавкуевнапанпрензоопарксчвысччасыимсавмчмррсрчокнгльтиакргддщборщувыцкепмиитворогдбоьлшщзхжъйфыцучясмпиттокарнаваллдш
Пар, капуста, город, настроение, беда, реклама, жизнь, красота, доброта, дерево, пожар, тыква, урок, круг, собака, Казахстан, зоопарк, часы, борщ, творог, карнавал
Заключение. Оценка деятельности детей.
Психогимнастическое
упражнение. Сделайте глубокий вдох. Руки медленно поднимаются через
стороны вверх. Задержка дыхания на вдохе. Выдох с открытым сильным звуком
А-А-А. Руки медленно опускаются. Вдох. Руки поднимаются до уровня плеч через
стороны.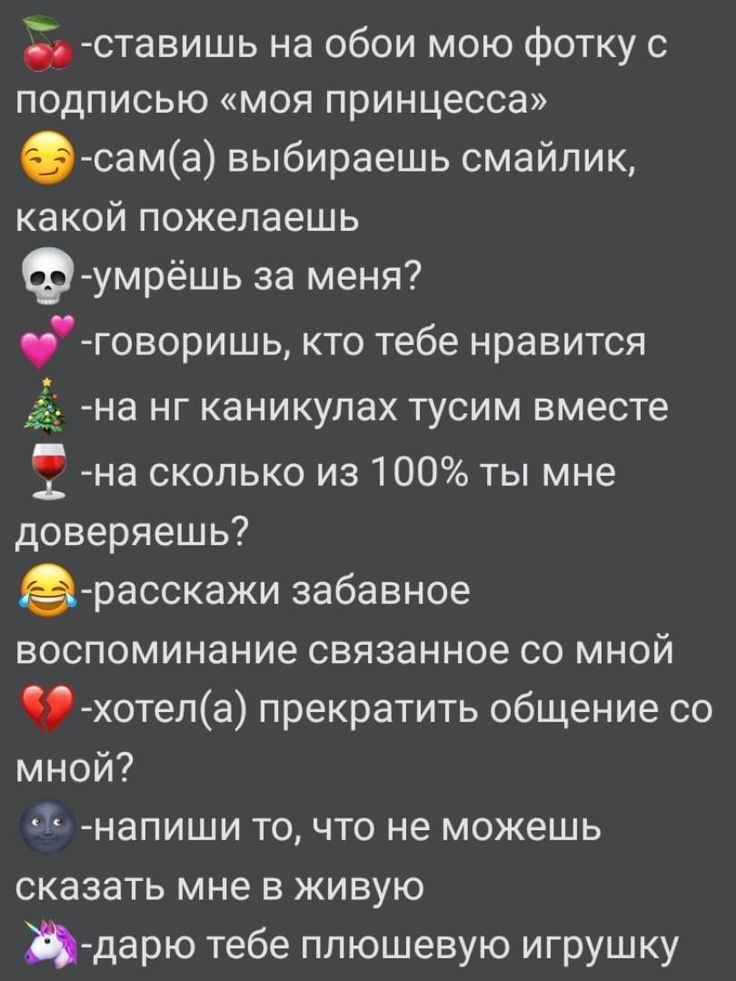 Задержка дыхания. Медленный выдох с сильным звуком О-О-О, обнять себя
за плечи, опустить голову на грудь.
Задержка дыхания. Медленный выдох с сильным звуком О-О-О, обнять себя
за плечи, опустить голову на грудь.
Рефлексия
— что мы сегодня развивали?
— Что было трудным? с чем ты справился легко?
-Какие упражнения выполняли?
— Во время занятия я поняла, что…
— Самым полезным для меня было…
— Больше всего мне понравилось…
Барометр настроения
Посмотри на стол, перед тобой лежат разные смайлики, выбери тот который соответствует твоему настроению после урока.
Педагог: Молодцы, справились со всеми заданиями! Посчитайте все свои жетоны. Определяется победитель, которому вручается медаль “Самый внимательный”. Остальные дети получают поощрительные призы (витамины).
— Мне понравилось работать с вами сегодня. Хочу поаплодировать вам! Спасибо.
Желаю вам успехов и на других уроках. Сегодняшний урок окончен. Спасибо за активную работу.
Список литературы:
Список использованной литературы
1. Акимова
М.К., Козлова В.Т. Коррекционно-раз-вивающие
упражнения для учащихся 3-5 классов. М., 1993.
Акимова
М.К., Козлова В.Т. Коррекционно-раз-вивающие
упражнения для учащихся 3-5 классов. М., 1993.
2. Афонькин C. Ю.. Учимся мыслить логически. Увлекательные задачи для развития логического мышления. СПб.: Издательский дом «Литера», 2002.
3. Венгер Л.А., Венгер АЛ. Домашняя школа мышления. М., 1985.
4. Деннисон П., Деннисон Г, Гимнастика для развития умственных способностей «Брейн джим». М., 1992.
5. Зак А.З. Занимательные игры для развития интеллекта у детей 5-12 лет. М., 1994.
6. Локалова НЛ. 90 уроков психологического развития младших школьников. Книга для учителя начальных классов. М.: «Луч», 1995.
7. Тихомирова Л.Ф. Логика. Дети 7-10 лет. Ярославль: Академия развития: Академия Холдинг, 2001.
8. Худенко ЕД., Мельникова Т.С., Шаховская СЛ. Как научить ребенка думать и говорить? (Упражнения по развитию памяти, внимания, мышления, речи, техники чтения). М., 1993.
Обнаружение контекстных эмоций в текстовых беседах с использованием нейронных сетей / Хабр
В настоящее время общение с диалоговыми агентами становится повседневной рутиной, и для диалоговых систем крайне важно генерировать ответы, максимально приближенные к человеческим.![]() В качестве одного из основных аспектов основное внимание следует уделить предоставлению пользователям эмоционально осознанных ответов. В этой статье мы собираемся описать архитектуру рекуррентной нейронной сети для обнаружения эмоций в текстовых разговорах , который участвовал в SemEval-2019 Task 3 «EmoContext», то есть ежегодном воркшопе по семантической оценке. Цель задачи состоит в том, чтобы классифицировать эмоции (т. е. счастливые, грустные, злые и другие) в наборе разговорных данных, состоящем из трех ходов.
В качестве одного из основных аспектов основное внимание следует уделить предоставлению пользователям эмоционально осознанных ответов. В этой статье мы собираемся описать архитектуру рекуррентной нейронной сети для обнаружения эмоций в текстовых разговорах , который участвовал в SemEval-2019 Task 3 «EmoContext», то есть ежегодном воркшопе по семантической оценке. Цель задачи состоит в том, чтобы классифицировать эмоции (т. е. счастливые, грустные, злые и другие) в наборе разговорных данных, состоящем из трех ходов.
Остальная часть статьи организована следующим образом. Раздел 1 дает краткий обзор задачи EmoContext и предоставленных данных. Разделы 2 и 3 посвящены предварительной обработке текстов и, следовательно, встраиванию слов. В разделе 4 мы описали архитектуру модели LSTM, использованной в нашей заявке. В заключении представлена итоговая производительность нашей системы и исходный код. Модель реализована на Python с использованием библиотеки Keras.
1.
 Данные тренировки
Данные тренировкиЗадание 3 SemEval-2019 «Эмоконтекст» ориентировано на выявление контекстуальных эмоций в текстовой беседе. В EmoContext, учитывая текстовое высказывание пользователя вместе с двумя поворотами контекста в разговоре, мы должны классифицировать, является ли эмоция следующего высказывания пользователя «счастливой», «грустной», «сердитой» или «другой» (таблица 1). Участников беседы всего два: аноним (Tuen-1 и Turn-3) и чат-бот на основе искусственного интеллекта Ruuh (Turn-2). Подробное описание см. в (Chatterjee et al., 2019).
Таблица 1. Примеры набора данных EmoContext (Chatterjee et al., 2019)
| Пользователь (поворот-1) | Разговорный агент (ход-1) | Пользователь (поворот-2) | Истинный класс |
|---|---|---|---|
| Я только что прошел стажировку в Набарде | ВАУ! Это замечательные новости. Поздравляем! | Я заплакал | Счастливый |
| Как ты посмел ударить моего ребенка | Если ты испортишь мою машину, я сделаю то же самое с тобой | Просто попробуйте сделать это один раз | Злой |
| Ты причинил мне боль больше | Ты не это имел в виду. | скажи что любишь меня | Сад |
| Сделаю ночь. | Хорошо. Держи меня в курсе. | Не дает номер WhatsApp. | Другие |
В ходе конкурса нам было доступно 30 160 человеко-размеченных текстов, предоставленных организаторами заданий, из которых около 5 000 образцов из класса «злой», «грустный», «счастливый» и 15 000 из класса «другие» (табл. 2). Наборы для разработки и тестирования, которые также были предоставлены организаторами, в отличие от набора поездов, имеют реальное распределение, которое составляет около 4% для каждого эмоционального класса и остальное для класса «другие». Данные предоставлены Microsoft и их можно найти в официальной группе LinkedIn.
Таблица 2. Распределение меток классов эмоций в наборах данных (Chatterjee et al., 2019).
| Набор данных | Счастливый | Сад | Злой | Другие | Всего |
|---|---|---|---|---|---|
| Поезд | 14,07% | 18,11% | 18,26% | 49,56% | 30160 |
| Дев | 5,15% | 4,54% | 5,45% | 84,86% | 2755 |
| Тест | 5,16% | 4,54% | 5,41% | 84,90% | 5509 |
| Дальний | 33,33% | 33,33% | 33,33% | 0% | 900к |
В дополнение к этим данным мы собрали 900 000 твитов на английском языке, чтобы создать удаленный набор данных из 300 000 твитов для каждой эмоции. Для формирования удаленного набора данных мы использовали стратегию Go et al. (2009), согласно которому мы просто связываем твиты с наличием слов, связанных с эмоциями, таких как «#злой», «#раздраженный», «#счастливый», «#грустный», «#удивленный» и т. д. Список запросов термины были основаны на терминах запроса SemEval-2018 AIT DISC (Duppada et al., 2018).
Для формирования удаленного набора данных мы использовали стратегию Go et al. (2009), согласно которому мы просто связываем твиты с наличием слов, связанных с эмоциями, таких как «#злой», «#раздраженный», «#счастливый», «#грустный», «#удивленный» и т. д. Список запросов термины были основаны на терминах запроса SemEval-2018 AIT DISC (Duppada et al., 2018).
Ключевым показателем производительности EmoContext является микросредняя оценка F1 для трех классов эмоций, т. е. «грустный», «счастливый» и «злой».
по определению preprocessData (dataFilePath, режим):
разговоры = []
метки = []
с io.open(dataFilePath, encoding="utf8") в качестве finput:
finput.readline()
для строки в finput:
строка = строка.strip().split('\t')
для я в диапазоне (1, 4):
строка [i] = маркер (строка [i])
если режим == "поезд":
labels.append(emotion2label[строка[4]])
конв = строка[1:4]
разговоры. append(conv)
если режим == "поезд":
вернуть np.array (разговоры), np.array (метки)
еще:
вернуть np.array (разговоры)
texts_train, labels_train = preprocessData('./starterkitdata/train.txt', mode="train")
texts_dev, labels_dev = preprocessData('./starterkitdata/dev.txt', mode="train")
texts_test, labels_test = preprocessData('./starterkitdata/test.txt', mode="train")
 append(conv)
если режим == "поезд":
вернуть np.array (разговоры), np.array (метки)
еще:
вернуть np.array (разговоры)
texts_train, labels_train = preprocessData('./starterkitdata/train.txt', mode="train")
texts_dev, labels_dev = preprocessData('./starterkitdata/dev.txt', mode="train")
texts_test, labels_test = preprocessData('./starterkitdata/test.txt', mode="train")
append(conv)
если режим == "поезд":
вернуть np.array (разговоры), np.array (метки)
еще:
вернуть np.array (разговоры)
texts_train, labels_train = preprocessData('./starterkitdata/train.txt', mode="train")
texts_dev, labels_dev = preprocessData('./starterkitdata/dev.txt', mode="train")
texts_test, labels_test = preprocessData('./starterkitdata/test.txt', mode="train")
2. Предварительная обработка текстов
Перед любым этапом обучения тексты предварительно обрабатывались текстовым инструментом Ekphrasis (Baziotis et al., 2017). Этот инструмент помогает выполнять исправление орфографии, нормализацию слов, сегментацию и позволяет указать, какие токены следует опустить, нормализовать или аннотировать специальными тегами. На этапе предварительной обработки мы использовали следующие методы.
- URL-адреса, электронные письма, дата и время, имена пользователей, проценты, валюты и числа были заменены соответствующими тегами.
- Повторяющиеся, подвергнутые цензуре, удлиненные и написанные с заглавной буквы термины были аннотированы соответствующими тегами.
- Удлиненные слова были автоматически исправлены на основе встроенного корпуса статистики слов.
- Распаковка хэштегов и сокращений (т.е. сегментация слов) выполнена на основе встроенного корпуса статистики слов.
- Созданный вручную словарь для замены терминов, извлеченных из текста, использовался с целью уменьшения разнообразия эмоций.

Кроме того, Emphasis предоставляет токенизатор, который способен идентифицировать большинство эмодзи, смайликов и сложных выражений, таких как подвергшиеся цензуре, подчеркнутые и удлиненные слова, а также даты, время, валюты и акронимы.
Таблица 3. Примеры предварительной обработки текста.
из ekphrasis.classes.preprocessor import TextPreProcessor из ekphrasis.classes.tokenizer импортировать SocialTokenizer из ekphrasis.
 )': '<счастливый>', 'angru': 'злой', "d-' :":":
'<раздраженный>', ":'-(": '<печальный>', ":-[": '<раздраженный>', '(�?�)': '<радостный>', 'x-d' : '<смех>',
}
text_processor = TextPreProcessor(
# условия, которые будут нормализованы
normalize=['url', 'электронная почта', 'процент', 'деньги', 'телефон', 'пользователь',
'время', 'url', 'дата', 'номер'],
# условия, которые будут аннотированы
annotate={"хэштег", "заглавные буквы", "удлиненный", "повторяется",
'выделено', 'цензура'},
fix_html = True, # исправить токены HTML
# корпус, из которого будет использоваться слово статистика
# для сегментации слов
сегментер = "твиттер",
# корпус, из которого будет использоваться слово статистика
# для исправления орфографии
корректор="твиттер",
unpack_hashtags=True, # выполнять сегментацию слов по хэштегам
unpack_contractions=True, # Распаковать сокращения (нельзя -> не могу)
Spell_correct_elong = True, # коррекция правописания для длинных слов
# выберите токенизатор.
)': '<счастливый>', 'angru': 'злой', "d-' :":":
'<раздраженный>', ":'-(": '<печальный>', ":-[": '<раздраженный>', '(�?�)': '<радостный>', 'x-d' : '<смех>',
}
text_processor = TextPreProcessor(
# условия, которые будут нормализованы
normalize=['url', 'электронная почта', 'процент', 'деньги', 'телефон', 'пользователь',
'время', 'url', 'дата', 'номер'],
# условия, которые будут аннотированы
annotate={"хэштег", "заглавные буквы", "удлиненный", "повторяется",
'выделено', 'цензура'},
fix_html = True, # исправить токены HTML
# корпус, из которого будет использоваться слово статистика
# для сегментации слов
сегментер = "твиттер",
# корпус, из которого будет использоваться слово статистика
# для исправления орфографии
корректор="твиттер",
unpack_hashtags=True, # выполнять сегментацию слов по хэштегам
unpack_contractions=True, # Распаковать сокращения (нельзя -> не могу)
Spell_correct_elong = True, # коррекция правописания для длинных слов
# выберите токенизатор. Вы можете использовать SocialTokenizer или передать свой собственный
# токенизатор должен принимать на вход строку и возвращать список токенов
tokenizer=SocialTokenizer(нижний регистр=True).tokenize,
# список словарей, для замены извлеченных из текста токенов,
# с другими выражениями. Вы можете передать более одного словаря.
dicts=[смайлики, emoticons_additional]
)
токенизация защиты (текст):
текст = " ".join(text_processor.pre_process_doc(текст))
возвращаемый текст
Вы можете использовать SocialTokenizer или передать свой собственный
# токенизатор должен принимать на вход строку и возвращать список токенов
tokenizer=SocialTokenizer(нижний регистр=True).tokenize,
# список словарей, для замены извлеченных из текста токенов,
# с другими выражениями. Вы можете передать более одного словаря.
dicts=[смайлики, emoticons_additional]
)
токенизация защиты (текст):
текст = " ".join(text_processor.pre_process_doc(текст))
возвращаемый текст
3. Вложения слов
Встраивание слов стало неотъемлемой частью любых подходов к глубокому обучению для систем НЛП. Чтобы определить наиболее подходящие векторы для задачи обнаружения эмоций, мы пробуем модели Word2Vec (Миколов и др., 2013), GloVe (Пеннингтон и др., 2014) и FastText (Джоулин и др., 2017), а также предварительно обученные DataStories. векторы слов (Baziotis et al., 2017). Ключевой концепцией Word2Vec является размещение слов, имеющих общий контекст в учебном корпусе, в непосредственной близости друг от друга в векторном пространстве. И модели Word2Vec, и модели Glove изучают геометрические кодировки слов на основе информации об их совместном появлении, но, по сути, первая является прогнозирующей моделью, а вторая — моделью, основанной на подсчете. Другими словами, в то время как Word2Vec пытается предсказать целевое слово (архитектура CBOW) или контекст (архитектура Skip-gram), то есть для минимизации функции потерь, GloVe вычисляет векторы слов, выполняя уменьшение размерности в матрице подсчета совпадений. FastText очень похож на Word2Vec, за исключением того факта, что он использует n-граммы символов для изучения векторов слов, поэтому он может решить проблему отсутствия словарного запаса.
И модели Word2Vec, и модели Glove изучают геометрические кодировки слов на основе информации об их совместном появлении, но, по сути, первая является прогнозирующей моделью, а вторая — моделью, основанной на подсчете. Другими словами, в то время как Word2Vec пытается предсказать целевое слово (архитектура CBOW) или контекст (архитектура Skip-gram), то есть для минимизации функции потерь, GloVe вычисляет векторы слов, выполняя уменьшение размерности в матрице подсчета совпадений. FastText очень похож на Word2Vec, за исключением того факта, что он использует n-граммы символов для изучения векторов слов, поэтому он может решить проблему отсутствия словарного запаса.
Для всех упомянутых выше техник мы использовали тренировочные коляски по умолчанию, предоставленные авторами. Мы обучаем простую модель LSTM (dim = 64) на основе каждого из этих вложений и сравниваем эффективность с помощью перекрестной проверки. Согласно результату, предобученные эмбеддинги DataStories продемонстрировали наилучший средний балл F1.
Чтобы обогатить выбранные вложения слов эмоциональной полярностью слов, мы рассматриваем возможность выполнения дистанционной предобучающей фразы путем точной настройки вложений в автоматически помеченном удаленном наборе данных. Важность использования предварительной подготовки была продемонстрирована в (Deriu et al., 2017). Мы используем удаленный набор данных, чтобы обучить простую сеть LSTM классифицировать злые, грустные и счастливые твиты. Слой эмбеддингов был заморожен на первую тренировочную эпоху, чтобы избежать существенных изменений весов эмбеддингов, а затем разморозился на следующие 5 эпох. После этапа обучения доработанные встраивания были сохранены для дальнейших этапов обучения и размещены в открытом доступе.
деф getEmbeddings (файл):
embeddingsIndex = {}
тусклый = 0
с io.open(file, encoding="utf8") как f:
для строки в f:
значения = строка.split()
слово = значения[0]
embeddingVector = np.asarray (значения [1:], dtype = 'float32')
embeddingsIndex[слово] = вектор внедрения
тусклый = len(embeddingVector)
вернуть embeddingsIndex, тусклый
def getEmbeddingMatrix(wordIndex, embeddings, dim):
embeddingMatrix = np. zeros((len(wordIndex) + 1, тусклый))
для слова я в wordIndex.items():
embeddingMatrix[i] = embeddings.get(слово)
вернуть матрицу встраивания
из keras.preprocessing.text импортировать Tokenizer
вложения, dim = getEmbeddings('emosense.300d.txt')
токенизатор = токенизатор (фильтры = '')
tokenizer.fit_on_texts([' '.join(список(embeddings.keys()))])
wordIndex = токенизатор.word_index
print("Найдено %s уникальных токенов." % len(wordIndex))
embeddings_matrix = getEmbeddingMatrix (wordIndex, embeddings, dim)
 zeros((len(wordIndex) + 1, тусклый))
для слова я в wordIndex.items():
embeddingMatrix[i] = embeddings.get(слово)
вернуть матрицу встраивания
из keras.preprocessing.text импортировать Tokenizer
вложения, dim = getEmbeddings('emosense.300d.txt')
токенизатор = токенизатор (фильтры = '')
tokenizer.fit_on_texts([' '.join(список(embeddings.keys()))])
wordIndex = токенизатор.word_index
print("Найдено %s уникальных токенов." % len(wordIndex))
embeddings_matrix = getEmbeddingMatrix (wordIndex, embeddings, dim)
zeros((len(wordIndex) + 1, тусклый))
для слова я в wordIndex.items():
embeddingMatrix[i] = embeddings.get(слово)
вернуть матрицу встраивания
из keras.preprocessing.text импортировать Tokenizer
вложения, dim = getEmbeddings('emosense.300d.txt')
токенизатор = токенизатор (фильтры = '')
tokenizer.fit_on_texts([' '.join(список(embeddings.keys()))])
wordIndex = токенизатор.word_index
print("Найдено %s уникальных токенов." % len(wordIndex))
embeddings_matrix = getEmbeddingMatrix (wordIndex, embeddings, dim)
4. Архитектура нейронной сети
Рекуррентная нейронная сеть (RNN) — это семейство искусственных нейронных сетей, специализирующихся на обработке последовательных данных. В отличие от традиционных нейронных сетей, RRN предназначены для работы с последовательными данными путем совместного использования своих внутренних весов при обработке последовательности. Для этого в графе вычисления РРН предусмотрены циклы, отражающие влияние предыдущей информации на настоящую. В качестве расширения RNN сети с долговременной кратковременной памятью (LSTM) были введены в 1997 (Хохрайтер и Шмидхубер, 1997). В LSTM повторяющиеся ячейки связаны особым образом, чтобы избежать проблем с исчезновением и взрывом градиента. Традиционные LSTM сохраняют информацию только из прошлого, поскольку обрабатывают последовательность только в одном направлении. Двунаправленные LSTM объединяют выходные данные двух скрытых слоев LSTM, движущихся в противоположных направлениях, где один движется вперед во времени, а другой движется назад во времени, что позволяет одновременно получать информацию как из прошлого, так и из будущего состояния (Шустер и Паливал, 19).97).
В качестве расширения RNN сети с долговременной кратковременной памятью (LSTM) были введены в 1997 (Хохрайтер и Шмидхубер, 1997). В LSTM повторяющиеся ячейки связаны особым образом, чтобы избежать проблем с исчезновением и взрывом градиента. Традиционные LSTM сохраняют информацию только из прошлого, поскольку обрабатывают последовательность только в одном направлении. Двунаправленные LSTM объединяют выходные данные двух скрытых слоев LSTM, движущихся в противоположных направлениях, где один движется вперед во времени, а другой движется назад во времени, что позволяет одновременно получать информацию как из прошлого, так и из будущего состояния (Шустер и Паливал, 19).97).
Рисунок 1: Архитектура уменьшенной версии предлагаемой архитектуры. Блок LSTM для первого витка и для третьего витка имеют общие веса.
Общий обзор нашего подхода представлен на рисунке 1. Предлагаемая архитектура нейронной сети состоит из модуля встраивания и двух двунаправленных модулей LSTM (dim = 64). Первый блок LSTM предназначен для анализа высказывания первого пользователя (т. е. первого и третьего поворотов разговора), а второй предназначен для анализа высказывания второго пользователя (т. е. второго хода). Эти два модуля изучают не только представление семантики и тональности, но и то, как фиксировать особенности разговора, характерные для пользователя, что позволяет более точно классифицировать эмоции. На первом этапе каждое высказывание пользователя подается в соответствующий двунаправленный модуль LSTM с использованием предварительно обученных вложений слов. Затем эти три карты объектов объединяются в плоский вектор объектов, а затем передаются в полностью связанный скрытый слой (dim = 30), который анализирует взаимодействия между полученными векторами. Наконец, эти функции проходят через выходной слой с функцией активации softmax, чтобы предсказать окончательную метку класса. Чтобы уменьшить переоснащение, слои регуляризации с гауссовым шумом были добавлены после слоя встраивания, выпадающие слои (Srivastava et al.
Первый блок LSTM предназначен для анализа высказывания первого пользователя (т. е. первого и третьего поворотов разговора), а второй предназначен для анализа высказывания второго пользователя (т. е. второго хода). Эти два модуля изучают не только представление семантики и тональности, но и то, как фиксировать особенности разговора, характерные для пользователя, что позволяет более точно классифицировать эмоции. На первом этапе каждое высказывание пользователя подается в соответствующий двунаправленный модуль LSTM с использованием предварительно обученных вложений слов. Затем эти три карты объектов объединяются в плоский вектор объектов, а затем передаются в полностью связанный скрытый слой (dim = 30), который анализирует взаимодействия между полученными векторами. Наконец, эти функции проходят через выходной слой с функцией активации softmax, чтобы предсказать окончательную метку класса. Чтобы уменьшить переоснащение, слои регуляризации с гауссовым шумом были добавлены после слоя встраивания, выпадающие слои (Srivastava et al. , 2014) были добавлены в каждую единицу LSTM (p = 0,2) и перед скрытым полносвязным слоем (p = 0,1).
, 2014) были добавлены в каждую единицу LSTM (p = 0,2) и перед скрытым полносвязным слоем (p = 0,1).
из keras.layers import Input, Dense, Embedded, Concatenate, Activation, \
Dropout, LSTM, двунаправленный, GlobalMaxPooling1D, GaussianNoise
из keras.models импорт Модель
def buildModel (embeddings_matrix, sequence_length, lstm_dim, hidden_layer_dim, num_classes,
шум=0,1, отсев_lstm=0,2, отсев=0,2):
turn1_input = Вход (форма = (sequence_length,), dtype = 'int32')
turn2_input = Вход (форма = (sequence_length,), dtype = 'int32')
turn3_input = Вход (форма = (sequence_length,), dtype = 'int32')
embedding_dim = embeddings_matrix.shape[1]
embeddingLayer = Embedding(embeddings_matrix.shape[0],
embedding_dim,
веса = [embeddings_matrix],
input_length = длина последовательности,
обучаемый = Ложь)
turn1_branch = EmbeddingLayer (turn1_input)
turn2_branch = EmbeddingLayer (turn2_input)
turn3_branch = EmbeddingLayer (turn3_input)
turn1_branch = GaussianNoise (шум, input_shape = (нет, sequence_length, embedding_dim)) (turn1_branch)
turn2_branch = GaussianNoise (шум, input_shape = (нет, sequence_length, embedding_dim)) (turn2_branch)
turn3_branch = GaussianNoise (шум, input_shape = (нет, sequence_length, embedding_dim)) (turn3_branch)
lstm1 = Двунаправленный (LSTM (lstm_dim, dropout = dropout_lstm))
lstm2 = Двунаправленный (LSTM (lstm_dim, dropout = dropout_lstm))
turn1_branch = lstm1(turn1_branch)
turn2_branch = lstm2 (turn2_branch)
turn3_branch = lstm1 (turn3_branch)
x = конкатенация (ось = -1) ([turn1_branch, turn2_branch, turn3_branch])
x = отсев (отсев) (x)
x = плотный (hidden_layer_dim, активация = 'relu') (x)
вывод = плотный (количество_классов, активация = 'softmax') (x)
модель = Модель (входы = [turn1_input, Turn2_Input, Turn3_Input], выходы = выход)
model. compile (потеря = 'categorical_crossentropy', оптимизатор = 'адам', метрики = ['acc'])
модель возврата
модель = buildModel (embeddings_matrix, MAX_SEQUENCE_LENGTH, lstm_dim = 64, hidden_layer_dim = 30, num_classes = 4)  compile (потеря = 'categorical_crossentropy', оптимизатор = 'адам', метрики = ['acc'])
модель возврата
модель = buildModel (embeddings_matrix, MAX_SEQUENCE_LENGTH, lstm_dim = 64, hidden_layer_dim = 30, num_classes = 4)
compile (потеря = 'categorical_crossentropy', оптимизатор = 'адам', метрики = ['acc'])
модель возврата
модель = buildModel (embeddings_matrix, MAX_SEQUENCE_LENGTH, lstm_dim = 64, hidden_layer_dim = 30, num_classes = 4) 5. Результаты
В процессе поиска оптимальной архитектуры мы экспериментировали не только с количеством ячеек в слоях, функциями активации и параметрами регуляризации, но и с архитектурой нейронной сети. Подробную информацию об этой фразе можно найти в оригинальной статье.
Модель, описанная в предыдущем разделе, продемонстрировала лучшие результаты в наборе данных для разработчиков, поэтому ее использовали на финальном этапе оценки конкурса. В последнем тестовом наборе данных он достиг 72,59.% микросреднего балла F1 для эмоциональных занятий, при этом максимальный балл среди всех участников составил 79,59%. Однако это намного выше официального базового уровня, опубликованного организаторами заданий, который составлял 58,68%.
Исходный код модели и встраивания слов доступны на GitHub.
Полную версию статьи и документ с описанием задачи можно найти на сайте ACL Anthology.
Набор обучающих данных находится в официальной группе соревнований в LinkedIn.
Цитата:
@inproceedings{smetanin-2019-emosense,
title = "{E}mo{S}ense на {S}em{E}val-2019 Задача 3: Двунаправленная сеть {LSTM} для контекстного обнаружения эмоций в текстовых разговорах",
автор = "Сметанин, Сергей",
booktitle = "Материалы 13-го Международного семинара по семантической оценке",
год = "2019",
address = "Миннеаполис, Миннесота, США",
издатель = "Ассоциация вычислительной лингвистики",
URL-адрес = "https://www.aclweb.org/anthology/S19-2034",
страницы = "210--214",
} SCIRP Открытый доступ
Издательство научных исследований
Журналы от A до Z
Журналы по темам
- Биомедицинские и биологические науки.
- Бизнес и экономика
- Химия и материаловедение.
- Информатика. и общ.
- Науки о Земле и окружающей среде.
- Машиностроение
- Медицина и здравоохранение
- Физика и математика
- Социальные науки. и гуманитарные науки

Журналы по тематике
- Биомедицина и науки о жизни
- Бизнес и экономика
- Химия и материаловедение
- Информатика и связь
- Науки о Земле и окружающей среде
- Машиностроение
- Медицина и здравоохранение
- Физика и математика
- Социальные и гуманитарные науки
Публикация у нас
- Подача статьи
- Информация для авторов
- Ресурсы для экспертной оценки
- Открытые специальные выпуски
- Заявление об открытом доступе
- Часто задаваемые вопросы
Публикуйте у нас
- Представление статьи
- Информация для авторов
- Ресурсы для экспертной оценки
- Открытые специальные выпуски
- Заявление об открытом доступе
- Часто задаваемые вопросы
Подпишитесь на SCIRP
Свяжитесь с нами
клиент@scirp. org org | |
| +86 18163351462 (WhatsApp) | |
| 1655362766 | |
| Публикация бумаги WeChat |
| Недавно опубликованные статьи |
| Недавно опубликованные статьи |
Подпишитесь на SCIRP
Свяжитесь с нами
клиент@scirp.  |