Как закрыть мой профиль Facebook?
Справочный центр
Мы обновляем версию сайта Facebook.com для мобильных браузеров. Ещё
Открытие профиля
Эта функция пока доступна только в некоторых странах и на определенных устройствах.
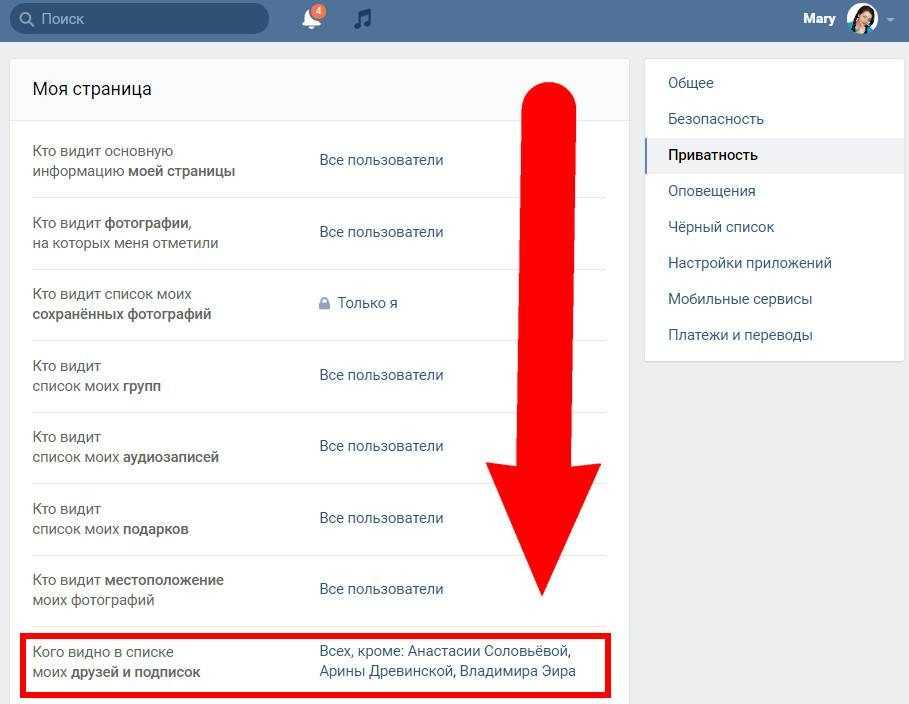
Если вы видите значок в профиле человека, это значит, что он закрыл свой профиль и ограничил доступ к своему контенту для людей, которых нет в списке его друзей на Facebook.
Когда человек закрывает профиль, следующий контент видят только его друзья:
Фото и публикации профиля.
Полноразмерные фото профиля и обложки.
Истории.
Новые публикации и фото.
Кроме того:
Все общедоступные публикации, которыми этот человек поделился ранее, станут доступны только его друзьям.
Будет включена функция проверки профиля и меток.
Сведения из раздела «Информация» его профиля будут видны только частично.
Другие способы управления конфиденциальностью
Если вы не можете закрыть профиль, управляйте конфиденциальностью своих данных с помощью настроек конфиденциальности:
Используйте проверку конфиденциальности.
Выберите аудиторию публикации.
Измените основную информацию в профиле и выберите, кому она будет доступна.
Измените настройки конфиденциальности истории.
Включите функцию проверки профиля.
Примените функцию проверки меток.
Включите защиту фото профиля.
Управляйте настройками для добавления в друзья и подписок.
Выберите, кто может находить ваш профиль с помощью вашего электронного адреса и номера мобильного телефона.
Статья оказалась полезной?
Кто просматривает ваш профиль Facebook?
Как включить защиту фото профиля на Facebook?
Раздел «Прозрачность профиля» в профессиональном режиме
Блокировка профилей на Facebook
Удаление, деактивация и повторная активация дополнительного профиля Facebook
© 2023 Meta
Af-SoomaaliAfrikaansAzərbaycan diliBahasa IndonesiaBahasa MelayuBasa JawaBisayaBosanskiBrezhonegCatalàCorsuCymraegDanskDeutschEestiEnglish (UK)English (US)EspañolEspañol (España)EsperantoEuskaraFilipinoFrançais (Canada)Français (France)FryskFulaFurlanFøroysktGaeilgeGalegoGuaraniHausaHrvatskiIkinyarwandaInuktitutItalianoIñupiatunKiswahiliKreyòl AyisyenKurdî (Kurmancî)LatviešuLietuviųMagyarMalagasyMaltiNederlandsNorsk (bokmål)Norsk (nynorsk)O’zbekPolskiPortuguês (Brasil)Português (Portugal)RomânăSarduShonaShqipSlovenčinaSlovenščinaSuomiSvenskaTiếng ViệtTürkçeVlaamsZazaÍslenskaČeštinaślōnskŏ gŏdkaΕλληνικάБеларускаяБългарскиМакедонскиМонголРусскийСрпскиТатарчаТоҷикӣУкраїнськакыргызчаҚазақшаՀայերենעבריתاردوالعربيةفارسیپښتوکوردیی ناوەندیܣܘܪܝܝܐनेपालीमराठीहिन्दीঅসমীয়াবাংলাਪੰਜਾਬੀગુજરાતીଓଡ଼ିଆதமிழ்తెలుగుಕನ್ನಡമലയാളംසිංහලภาษาไทยພາສາລາວမြန်မာဘာသာქართულიአማርኛភាសាខ្មែរⵜⴰⵎⴰⵣⵉⵖⵜ中文(台灣)中文(简体)中文(香港)日本語日本語(関西)한국어
Информация
Конфиденциальность
Условия и правила
Рекламные предпочтения
Вакансии
Файлы cookie
Создать объявление
Создать Страницу
▷ Какие страницы закрыть от индексации: запрет индексации страниц
33296
| How-to | – Читать 14 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Инструкцию одобрил
Tech Head of SEO в TRINET. Group
Group
Рамазан Миндубаев
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Содержание:
- Причины запретить индексацию страницы
- Какие страницы не индекстровать
- Как закрыть страницы от индексации
3.1. Как закрыть сайт от индексации Google - Как проверить, сколько страниц закрыто от индексации
- Заключение
FAQ
Причины запретить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта (корзина, страница оплаты, результатов поиска, авторизация и т.д.), данные с персональной информацией, наборы фильтров каталога товара в электронной коммерции (множественный выбор фильтров по цене, цвету, фактуре и другое).
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое периодически сканирует поисковая система. Для всех сайтов это значение количества страниц разное и не постоянное и в том числе зависит от типа сайта и частоты его обновления. В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
Схема сканирования, индексирования и ранжирования сайта
Хотите прямо сейчас проверить, какие страницы вашего сайта индексируются и находятся в топе поисковой выдачи? А по каким фразам ранжируется ваш конкурент? Попробуйте Serpstat (нужно зарегистрироваться и после вы получите доступ к бесплатным инструментам). Если хотите доминировать на своем рынке — используйте Serpstat и достигайте большей эффективности в онлайн.
Какие закрыть страницы от индексации
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковых систем. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
Закрыть сайт от индексации в robots.txt можно следующим содержимым (первая директива — означает обращение ко всем краулерам, вторая директива — запрещает сканировать все URL сайта):
User-agent: *
Disallow: /
Эти две строчки запретят доступ к сайту всем роботам поисковых систем.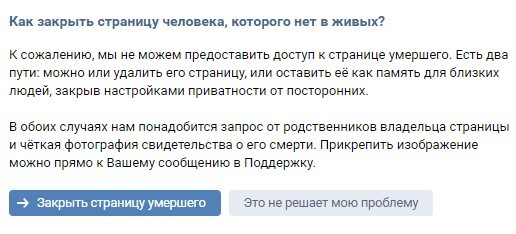
Если нужно при этом разрешить сканировать конкретные URL, нужно добавить директиву Allow: /namepage$ где /namepage URL страницы разрешенной к сканированию. Директива разрешения сканирования доминирует над запретом (для конкретного URL), а значек $ отменяет применение по умолчанию не выводимывого символа «*». То есть если не поставить $ — мы разрешим сканировать вложенные URL относительно родителя, такие как /namepage/indexpage.html и т.д.
Запрет индексации для сайта на сервере NGINX осуществляется с помощью добавления кода add_header X-Robots-Tag «noindex, nofollow»; в файл .conf.
Копии сайта
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в роботс закрыть от индексации все страницы печати.
Ненужные документы
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Пример индексации pdf-файла на сайте
Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические данные сайта
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Форма авторизации в админку OpenCart
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.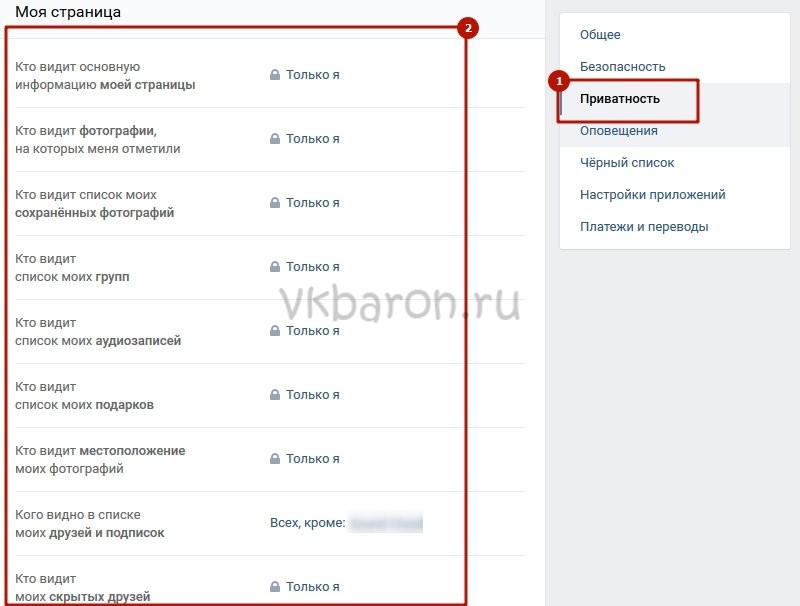
Страницы сортировки
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Страницы пагинации
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
- Как провести анализ индексации сайта
- SEO-аудит сайта с помощью Serpstat: обзор инструмента
- Как автоматизировать поиск ошибок на сайте: Аудит сайта теперь доступен в API Serpstat
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Чтобы закрыть страницу от индексации, используйте атрибут noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Это позволяет полностью закрыть страницу, оставив роботам возможность переходить по размещенным на странице ссылкам. Если это не нужно, замените follow на nofollow:
<meta name=»robots» content=»noindex, nofollow»/>
При использовании данных методов страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Как закрыть сайт от индексации Google
Вы можете также закрыть доступ к сайту только ботам Google. Добавьте для этой цели данный метатег внутри <head> </head> всех страниц ресурса:
<meta name=»googlebot» content=»noindex, nofollow»/>
Через robots доступ к сайту ботам Google закрывается так:
User-agent: googlebot
Disallow: /
Еще можно запретить доступ к каким-либо статьям сайта роботам Google Новостей, тогда они не появятся в Google News:
<meta name=»Googlebot-News» content=»noindex, nofollow»>.
Файл robots.txt
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
User-agent: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthType Basic AuthName "Password Protected Area" AuthUserFile путь к файлу с паролем Require valid-user
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления.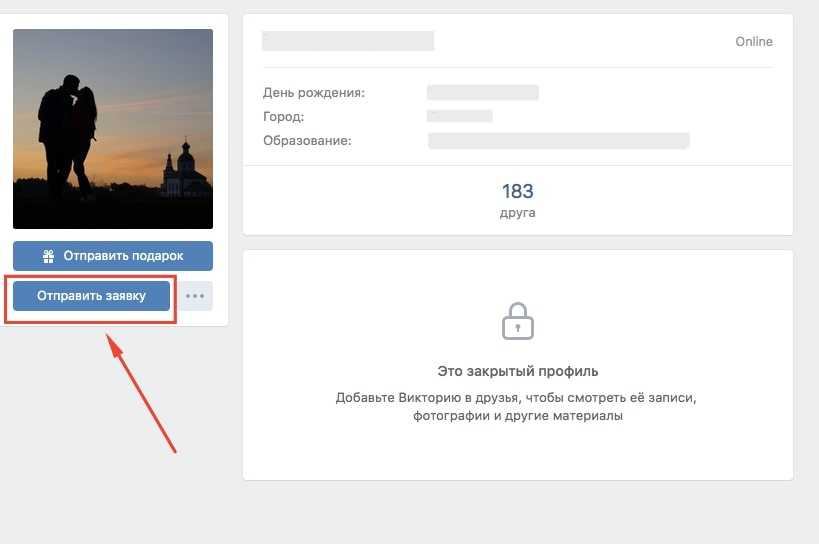
Удаление URL-адресов из индекса в Search Console
Как проверить, сколько страниц закрыто от индексации
С помощью Аудита сайта Serpstat можно быстро проверить сайт на наличие технических ошибок и узнать, сколько страниц не проиндексировано.
Для того, чтобы это сделать нужно всего лишь нажать на кнопку ниже, и у вас будет возможность создать проект для сайта ↓
В появившихся настройках можно указать имя домена и количество страниц, которые нужно просканировать краулеру:
Запуск аудита в Serpstat
Выбор типа сканирования и указание лимита страниц
Когда сканирование будет закончено, на графике в Суммарном отчете можно проверить, какое количество страниц из указанных не проиндексировано:
Проверка индексации страниц в Аудите Serpstat
Хотите узнать, как с помощью Serpstat найти и исправить технические ошибки на сайте?
Оставьте заявку и наши специалисты проконсультируют вас по продвижению вашего проекта, поделятся учебными материалами и инсайтами рынка!
| Заказать бесплатную консультацию |
Error get alias
Заключение
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
Как запретить индексацию сайта?
Запретить доступ ботов поисковых систем к сайту можно с помощью нескольких способов: добавления метатега robots со значением noindex в html-код; указания директивы Disallow в файле robots.txt; установки пароля для доступа к сайту в конфигурационном файле .htaccess. Также можно блокировать доступ к отдельным каталогам и документам.
Как временно закрыть сайт от индексации
Чтобы закрыть сайт от индексации, добавьте метатег name=»robots» content=»noindex, nofollow» в раздел всех веб-страниц или добавьте директиву User-agent: * Disallow: / в файл robots.txt.
Как закрыть сайт от индексации WordPress
Чтобы закрыть сайт WordPress от индексации, зайдите в админку CMS, выберите раздел «Настройки» → «Чтение». Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Задавайте вопросы в комментариях или пишите в техподдержку.:) А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
7 дней бесплатно
Оцените статью по 5-бальной шкале
4.11 из 5 на основе 45 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как включить HTTP/2 для сайта
How-to
Анастасия Сотула
Как проверить посещаемость сайта в системах аналитики и без счетчика
How-to
Анастасия Сотула
Что такое SEO продвижение сайтов: SEO оптимизация сайта пошагово
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе.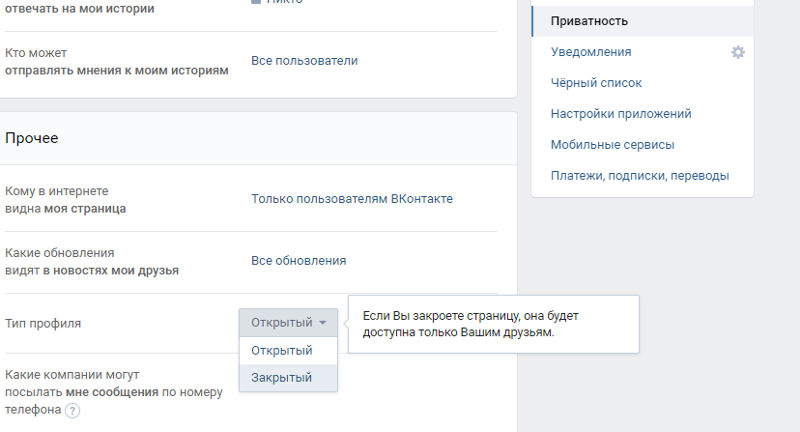 Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
просмотр веб-страниц — page.close() не работает должным образом в Playwright и asyncio
Я написал веб-скрапер, который должен асинхронно очистить несколько сотен страниц в Playwright-Python после входа в систему. Я наткнулся на aiometer от @Florimond Manca (https://github.com/florimondmanca/aiometer), чтобы ограничить запросы в основной асинхронной функции — это работает хорошо.
Проблема, с которой я столкнулся в данный момент, заключается в закрытии страниц после того, как они были очищены. Асинхронная функция просто увеличивает количество загружаемых страниц, как и должно быть, но значительно увеличивает потребление памяти, если загружено несколько сотен.
Как закрыть страницы после очистки (в функции очистки)?
асинхронный импорт
импортировать инструменты
из playwright.async_api импортировать async_playwright
из bs4 импортировать BeautifulSoup
импортировать панд как pd
импортный айометр
URL = [
"https://scrapethissite.com/pages/ajax-javascript/#2015",
"https://scrapethissite.com/pages/ajax-javascript/#2014",
"https://scrapethissite.com/pages/ajax-javascript/#2013",
"https://scrapethissite.com/pages/ajax-javascript/#2012",
"https://scrapethissite.com/pages/ajax-javascript/#2011",
"https://scrapethissite.com/pages/ajax-javascript/#2010"
]
асинхронная очистка определения (контекст, URL):
страница = ожидание контекста.
new_page()
ожидание page.goto(url)
ожидание page.wait_for_load_state(state="networkidle")
ожидание page.wait_for_timeout(1000)
#Получение результатов со страницы
html = ожидание page.content()
суп = BeautifulSoup(html, "lxml")
таблицы = суп.find_all('таблица')
dfs = pd.read_html (str (таблицы))
дф=дфс[0]
print("Фрейм данных на странице "+URL+" очищен")
страница.закрыть
вернуть дф
асинхронное определение основного (urls):
async с async_playwright() как p:
браузер = ожидание p.chromium.launch (без головы = ложь)
контекст = ожидание browser.new_context()
master_results = pd.DataFrame()
асинхронно с aiometer.amap(
functools.partial (очистка, контекст),
URL,
max_at_once=5, # Ограничить максимальное количество одновременно запущенных задач.
max_per_second=3, # Ограничьте скорость запросов, чтобы не перегружать сервер.
) в результате:
async для данных в результатах:
печать (данные)
master_results = pd. concat([master_results,data], ignore_index=True)
печать (мастер_результаты)
asyncio.run(основной(urls))

 concat([master_results,data], ignore_index=True)
печать (мастер_результаты)
asyncio.run(основной(urls))
concat([master_results,data], ignore_index=True)
печать (мастер_результаты)
asyncio.run(основной(urls))
Я пробовал использовать ключевое слово await до того, как page.close() или context.close() выдает ошибку: «TypeError: объектный метод не может использоваться в выражении «ожидание»».
- просмотр веб-страниц
- python-asyncio
- драматург
- драматург-python
После прочтения нескольких страниц, даже в трекеры ошибок документации Playwright на github: https://github.com/microsoft/playwright/ Issues/10476 , я нашел проблему: Я забыл добавить круглые скобки в свою функцию page.close.
страница.close()
Так просто, но на это у меня ушло несколько часов. Вероятно, это часть обучения программированию.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Установить WinDbg — драйверы Windows
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
WinDbg — это отладчик, который можно использовать для анализа аварийных дампов, отладки живого кода пользовательского режима и режима ядра, а также проверки регистров ЦП и памяти.
Установить WinDbg
Эта последняя версия предлагает более современный пользовательский интерфейс с обновленным интерфейсом, полноценными возможностями сценариев, расширяемой моделью отладочных данных, встроенной поддержкой отладки во времени (TTD) и множеством дополнительных функций.
Дополнительные сведения см. в разделе Обзор WinDbg.
Загрузить WinDbg
Выберите Установить , и отладчик загрузится и установится.
WinDbg также будет периодически проверять наличие новых версий в фоновом режиме и при необходимости выполнять автоматическое обновление.
Примечание
Ранее выпущенная как WinDbg Preview в Microsoft Store, эта версия использует тот же базовый механизм, что и WinDbg (классическая) , и поддерживает все те же команды, расширения и рабочие процессы.
Чтобы получить последнюю версию и остаться на ней, установите WinDbg, как описано на этой странице. WinDbg Preview не будет получать дальнейшие обновления в Microsoft Store.
Требования
- Поддерживаемые операционные системы:
- Windows 11 (все версии)
- Юбилейное обновление Windows 10 (версия 1607) или новее
- Архитектуры процессора:
- x64 и ARM64
Поиск и устранение неисправностей
Если вы столкнулись с трудностями при установке или обновлении WinDbg, см. раздел Устранение неполадок при установке с помощью файла установщика приложений.
Если вы обнаружите какие-либо ошибки или у вас есть запрос на функцию, вы можете нажать кнопку обратной связи на ленте, чтобы перейти на страницу GitHub, где вы можете зарегистрировать новую проблему.
Начало работы с WinDbg
Чтобы начать работу с WinDbg, см. раздел Начало работы с отладкой Windows.