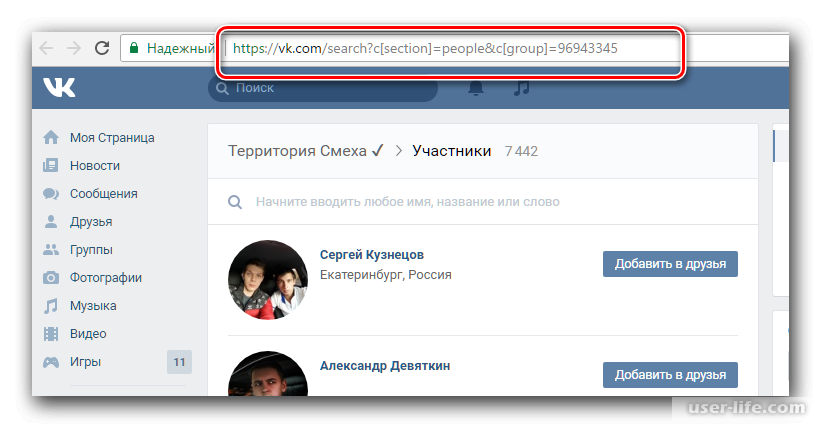
как развивалось распознавание речи ВКонтакте — ВКонтакте на vc.ru
С миллионами часов голосовых и звуком «ъ».
5980 просмотров
Привет! На связи команда прикладных исследований ВКонтакте. Недавно мы открыли доступ для сторонних разработчиков к ASR — технологии распознавания речи, которая считывает голос и переводит его в текст. Как это работает, для чего нужно и почему мы решили поделиться нашими наработками с миром? Рассказываем обо всём по порядку.
Что такое ASR
ASR, или automatic speech recognition, — это технология, которая помогает переводить устную речь в текст. После этого с текстом можно делать почти что угодно: передавать в поиск или переводить в голосовые команды для техники, использовать для управления в играх и сервисах. Чаще всего ASR используют в голосовых помощниках, умных устройствах, для расшифровки аудио и видео. Но области применения ограничены только фантазией разработчиков и исследователей — мы увидим ещё немало крутых кейсов.
Идея переводить голос в текст появилась очень давно, однако с практикой был статус «всё сложно». Как итог, технология ASR начала становиться массовой только несколько лет назад. Тогда мы и начали исследовать, как использовать распознавание речи в продуктах: в первую очередь в расшифровке голосовых сообщений, которую мы запустили два года назад.
С чего начиналась технология ASR ВКонтакте
Почему мы начали с распознавания голосовых? Всё просто — так мы примирили два лагеря: тех, кому дует, и тех, кому душно. Прочитать текстовое сообщение — быстрее, чем послушать голосовое. По тексту проще найти, у какого именно выхода из метро вы назначили встречу, так легче воспринимать числа, адреса и номера телефонов. Но записывать голосовые бывает удобнее, чем печатать, — особенно когда едешь за рулём, моешь посуду или появилась минутка между рабочими встречами.
Распознавание речи помогло найти компромисс. Благодаря ему можно общаться так, как хочется: слушать или читать, говорить или печатать.
Люди становятся ближе друг другу — и это самое ценное.

Расшифровка голосовых — что внутри
Чтобы всё работало, мы используем наши собственные технологии и щепотку волшебства. После того как пользователь записывает аудио, оно попадает на сервер. Там запись обрабатывают три нейросети.
- Акустическая модель отвечает за распознавание звуков. Она поймёт вас, даже если вы пытаетесь найтись с другом в шумном баре или среди гула на футбольном матче.
- Языковая модель формирует из звуков слова. Здесь происходит магия вне Хогвартса: набор звуков превращается в текст на экране.
- Пунктуационная модель определяет границы предложения, расставляет знаки препинания и заглавные буквы. Это нужно, чтобы на выходе получился связный логичный текст.
Что касается датасетов, то здесь мы всё тоже делали сами. Вот как мы собирали данные для обучения модели.
- Разработали модель, которая генерировала тексты. Мы создавали специальные тексты, которые зачитывали наши тестеры. Среди них были специально сгенерированные нейронкой выражения и комментарии из публичных постов в сообществах — это тоже разговорная речь, где есть место и «кринжовым мемам», и нецензурным выражениям. Благодаря модели подготовили короткие тексты — длиной от 3 до 30 слов.
- Попросили бета-тестировщиков из рядов VK Testers надиктовать эти тексты в голосовых. Ребята говорили как обычно и записывали голосовые в разных условиях: выходили к шумным дорогам, включали воду. А иногда мы искусственно добавляли шум к аудио — чтобы данные для обучения были максимально близки к жизни.
В результате нейросети умеют убирать паузы из записи, понимать неразборчивую речь, ненормативную лексику, заимствования, сокращения — это уникальные умения для подобных решений на рынке. Сленг стал для нас отдельным испытанием, но без его расшифровки в голосовых было бы не обойтись.
Наши модели понимают, чем «крипота» отличается от «кринжа», кто такие «краш», «кун» и «тян», — и легко распознают все эти слова в речи.
 Наши модели понимают, чем «крипота» отличается от «кринжа», кто такие «краш», «кун» и «тян», — и легко распознают все эти слова в речи.
Наши модели понимают, чем «крипота» отличается от «кринжа», кто такие «краш», «кун» и «тян», — и легко распознают все эти слова в речи.Сперва можно было расшифровывать только голосовые не дольше 30 секунд. Но потом мы пошли дальше, и сейчас в текст можно переводить записи до 2 часов. Это все голосовые, которыми пользователи делятся друг с другом. Хотя ситуации бывают разными: иногда забываешь заблокировать телефон, прежде чем положить его в карман, — и друзья получают голосовые с тремя часами АСМР-шуршания.
Что говорят пользователи
Можно долго рассказывать о наших технологиях, но намного важнее — что говорят о них пользователи. А многие из них оказались довольны расшифровкой: фича спасает тех, кто не любит слушать голосовые. Пользователи отмечают, что текст распознаётся чётко — даже с учётом пунктуации. И что инструмент доступен бесплатно в отличие от других подобных решений на рынке.
Конечно, распознавание не может быть абсолютно точным — ни одна нейросеть не создаст расшифровку, корректную на 100% (к слову, это не под силу и человеку). Забавные ошибки случаются и у нас, это рождает шутки и мемы. Например, ВКонтакте есть целое сообщество, подписчики которого делятся друг с другом забавными результатами расшифровки голосовых.
Забавные ошибки случаются и у нас, это рождает шутки и мемы. Например, ВКонтакте есть целое сообщество, подписчики которого делятся друг с другом забавными результатами расшифровки голосовых.
Ещё оказалось, что ошибочные расшифровки можно использовать как механику для конкурсов. Такая идея пришла организаторам онлайн-игр по вселенной Гарри Поттера: в голосовых звучал рассказ от лица Джинни Уизли, Полумны Лавгуд и Невилла Долгопупса. По распознанному тексту нужно было отгадать, где находились персонажи.
Для особо внимательных мы приберегли пасхалки — например, распознавание звука «ъ». Мы умеем и такое! Фича быстро приобрела фанатов и запустила челлендж: пользователи снимали, как пытаются произнести твёрдый знак так, чтобы он попал в расшифровку. Некоторые из таких видео собрали миллионы просмотров.
Кстати, у нас есть ещё пара идей для челленджей. Попробуйте пораспознавать разные виды смеха — сможете отличить «ихихих» от «ахахаха»? Ещё можно посмотреть, как расшифруются ваши фырканья и кряхтения — то есть обычные звуки, которые издаёт офисный сотрудник после долгого рабочего дня. И, наконец, квест для самых продвинутых — повторить ЪУЪ из того самого мема. Mission impossible. Или нет?
И, наконец, квест для самых продвинутых — повторить ЪУЪ из того самого мема. Mission impossible. Или нет?
Как результат, наш сервис по распознаванию речи стал одним из самых высоконагруженных среди подобных решений на русском языке. Каждый месяц пользователи ВКонтакте отправляют друг другу больше 2 млрд голосовых. Это миллионы часов аудио, которые обрабатывают нейросети.
ASR в других наших продуктах
Когда мы поняли, что распознавание голосовых оправдало ожидания (наши и пользователей), решили двигаться дальше и начать внедрять ASR в другие продукты. Так на платформе VK Видео появились автоматические субтитры. Они помогают смотреть видео без звука — это удобно, когда хочется отвлечься во время рабочего перерыва и не мешать коллегам. Или когда наушники далеко — например, по пути домой в метро.
Для автоматических субтитров мы взяли лучшее, что было в ASR: применили подход, похожий на тот, что использовали в голосовых. Но внесли несколько изменений.
Но внесли несколько изменений.
• Обучили нейтральную языковую модель — потому что лексика в видео сильно отличается от того, как общаются пользователи в чатах. В итоге мы научились работать не только с разговорной речью, но и с литературной.
• Специально для видео разработали ещё одну модель. Она распределяет текст по кадрам, чтобы субтитры появлялись точно в момент, когда спикер произносит фразу.
Сейчас мы активно работаем над диаризацией — это когда речь разделяется на реплики. Так фразы разных спикеров в расшифровке будут самостоятельными, даже если собеседники общаются без заметных пауз.
И автосубтитры, и распознавание голосовых сообщений работают на основе модели шумоподавления. Мы используем её в VK Звонках, чтобы важному конфколу не помешали соседи с дрелью или громкие беседы рядом с переговоркой.
Также мы используем распознавание речи в роликах, чтобы формировать умные рекомендации. С помощью ASR алгоритмы лучше понимают, про что видео и у кого оно вызовет интерес.
Открываем доступ к ASR
Если технология успешно работает в наших продуктах, почему бы ею не поделиться? Ведь чем больше проектов с распознаванием речи будет на рынке, тем окажется лучше для всех его участников: повысится качество решений, появятся новые нестандартные идеи. Так подумали мы — и открыли доступ к ASR для сторонних разработчиков.
Для распознавания можно выбрать одну из двух моделей.
- Нейтральная модель подходит для разборчивой речи, как в интервью или телешоу, — её мы используем для субтитров.
- Спонтанная модель лучше распознаёт речь со сленгом и ненормативной лексикой — как у нас в голосовых.
Мы ориентировались в первую очередь на независимых разработчиков, которые находятся в начале своего пути. Решение подойдёт для перспективных стартапов, личных pet-проектов, сервисов платформы VK Mini Apps, обучения и саморазвития. Если вы создаёте свою инди-игру, можете внедрить голосовое управление — такое встречается нечасто, поэтому вызовет интерес у аудитории.
Планы
Мы уже получили много запросов на доступ к ASR, в том числе от крупных брендов. Возможно, совсем скоро наша технология появится в хорошо знакомых сервисах — с нетерпением ждём!
Что ещё по планам?
• Продолжим обучать нейросети, чтобы они корректно распознавали актуальную лексику. Язык постоянно развивается, в речи появляется всё больше слов. И мы постоянно обучаем модели на новых данных, чтобы они понимали, что такое «нёрф» и «катка в кс». Йоу-йоу, сноубординг, дискета!
• Продолжим повышать точность распознавания речи. Возможно, станет меньше мемов с неверными расшифровками. Но мы готовы пойти на такую жертву 🙂
• Будем улучшать пунктуационную модель и инструменты для шумоподавления, чтобы ни один сосед с дрелью вам не помешал.
• Посмотрим, в каких ещё продуктах ВКонтакте пригодится ASR. Тысячи наших инженеров бьются над тем, чтобы мы могли распознавать речь котиков. Шутка! Хотя кто знает — может быть, и такие задачи ждут нас в будущем.
Тысячи наших инженеров бьются над тем, чтобы мы могли распознавать речь котиков. Шутка! Хотя кто знает — может быть, и такие задачи ждут нас в будущем.
Потенциал ASR огромен, так что нам только предстоит узнать все возможности технологии. А пока мы будем продолжать развивать распознавание речи — и, конечно, держать вас в курсе всех новостей.
Газета «Речь», новый выпуск — Речь
← 29 июня 2023
Объявление в газету
Оформить подписку
Благоустройство
30 июня 2023Клумбы готовы покорять комиссию
Источник: Речь
30 июня 2023
Выделили средства на поликлинику
Поправки в областной бюджет внесли депутаты ЗСО
Финансы
30 июня 2023Украл за восемь тысяч, а продал за полторы
Общество
30 июня 2023В центре большие перемены
Транспорт•Благоустройство
30 июня 2023Кино придет через неделю
Культура
30 июня 2023Чем опасны переедание и гиподинамия
Медицина
Подпишись на телеграм-канал 35MEDIA
Канал о главных событиях Вологодчины. Интересуемся жизнью соседей и тоже рассказываем об этом
Интересуемся жизнью соседей и тоже рассказываем об этом
ЛЕНТА НОВОСТЕЙ
Лента новостей
ВСЕ НОВОСТИ
Лето пока жарой не балует. Успели ли вы открыть купальный сезон?
Да, уже накупались
23.33%
Нет, вода еще не прогрелась
41.43%
Нет, рядом нет приличных мест для купания
24.76%
Я – морж, купаюсь круглый год
Не умею плавать, никогда не купаюсь
Анонимно илиОтправьте свою новость в редакцию, расскажите о проблеме или подкиньте тему для публикации. Сюда же загружайте ваши видео и фото.
Предложить новость(8172) 280-003Вологда
(8202) 57-11-11Череповец
Владимир Путинпрезидент РФ
«Предлагаю пособия на ребенка до полутора лет, а также единое детское пособие выплачивать в течение всего периода времени, на который они назначены, независимо от того, увеличился доход семьи или нет. Сейчас, если доход даже незначительно увеличивается, то социальные выплаты прекращаются. А значит, стимулов искать новую работу, более высокооплачиваемую, у человека нет. Это нужно изменить. Работать должно быть выгодно, а государственная поддержка должна служить дополнительным доходом к зарплате, а не ее заменой».
А значит, стимулов искать новую работу, более высокооплачиваемую, у человека нет. Это нужно изменить. Работать должно быть выгодно, а государственная поддержка должна служить дополнительным доходом к зарплате, а не ее заменой».
16 Июня 2023
1
30 июня 2023, 14:14
Вологжанин, по вине которого утонули его жена и 6-летний сын, предстанет перед судом
2
30 июня 2023, 09:50
Малыш родился в машине скорой помощи в Вологде
3
30 июня 2023, 13:43
Лучшего директора школы выбрали накануне в Череповце
4
30 июня 2023, 14:41
Родственников потерявшей память женщины ищут в Череповецком районе
5
30 июня 2023, 12:32
Полина Морозова делает первые шаги после реанимации
01 июля, суббота
18:59:14
Коронавирус
227580 (+17) чел
USD 88.38
EUR 96. 02
02
Как получить идентификатор сеанса преобразования речи в текст и идентификатор транскрипции — Azure Cognitive Services
Редактировать Твиттер LinkedIn Фейсбук Электронная почта- Статья
Если вы используете преобразование речи в текст и вам нужно открыть запрос в службу поддержки, вас часто просят предоставить идентификатор сеанса или идентификатор транскрипции проблемных транскрипций для устранения проблемы. В этой статье объясняется, как получить эти идентификаторы.
Примечание
- Идентификатор сеанса используется для преобразования речи в текст и речи в режиме реального времени.
- Идентификатор транскрипции используется в пакетной транскрипции.

Получение идентификатора сеанса
Преобразование речи в текст в режиме реального времени и преобразование речи используют пакет SDK для обработки речи или REST API для коротких аудио.
Чтобы получить идентификатор сеанса, при использовании SDK необходимо:
- Включить ведение журнала приложений.
- Найдите идентификатор сеанса в журнале.
Если вы используете Speech SDK для JavaScript, получите идентификатор сеанса, как описано в этом разделе.
Если вы используете Speech CLI, вы также можете получить идентификатор сеанса в интерактивном режиме. Подробности смотрите в этом разделе.
В случае Speech to text REST API для короткого аудио вам необходимо «вставить» информацию о сеансе в запросы. Подробности смотрите в этом разделе.
Включите ведение журнала в пакете SDK для распознавания речи
Включите ведение журнала для вашего приложения, как описано в этой статье.
Получить идентификатор сеанса из журнала
Откройте файл журнала, созданный вашим приложением, и найдите SessionId: . Номер, который будет следовать, является идентификатором сеанса, который вам нужен. В следующем примере выдержки из журнала
Номер, который будет следовать, является идентификатором сеанса, который вам нужен. В следующем примере выдержки из журнала 0b734c41faf8430380d493127bd44631 — это идентификатор сеанса.
[874193]: 218 мс SPX_DBG_TRACE_VERBOSE: audio_stream_session.cpp:1238 [0000023981752A40]CSpxAudioStreamSession::FireSessionStartedEvent: запуск события SessionStarted: SessionId: 0b734c41faf8430380 д493127бд44631
Получить идентификатор сеанса с помощью JavaScript
Если вы используете Speech SDK для JavaScript, вы получаете идентификатор сеанса с помощью события sessionStarted из класса Recognizer.
См. пример получения идентификатора сеанса с помощью JavaScript в этом примере. Найдите распознаватель.sessionStarted = onSessionStarted; , а затем для функция onSessionStarted .
Получить идентификатор сеанса с помощью Speech CLI
Если вы используете Speech CLI, вы увидите идентификатор сеанса в СЕССИЯ НАЧАЛА и СЕССИЯ ОСТАНОВЛЕНА сообщений консоли.
Вы также можете включить ведение журнала для своих сеансов и получить идентификатор сеанса из файла журнала, как описано в этом разделе. Запустите соответствующую команду Speech CLI, чтобы получить информацию об использовании журналов:
spx help распознать журнал
spx помогите перевести журнал
Предоставление идентификатора сеанса с помощью REST API для коротких аудио
В отличие от Speech SDK, преобразование речи в текст REST API для коротких аудио не создает автоматически идентификатор сеанса. Вам нужно сгенерировать его самостоятельно и предоставить в запросе REST.
Создайте GUID внутри вашего кода или с помощью любого стандартного инструмента. Используйте значение GUID без дефисов и других разделителей . В качестве примера мы будем использовать 9f4ffa5113a846eba289aa98b28e766f .
В составе запроса REST используйте выражение X-ConnectionId=. Для нашего примера образец запроса будет выглядеть так:
https://westeurope.
 stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&X-ConnectionId=9f4ffa5113a846eba289aa98b28e766f
stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&X-ConnectionId=9f4ffa5113a846eba289aa98b28e766f
9f4ffa5113a846eba289aa98b28e766f будет вашим идентификатором сеанса.
Получение идентификатора транскрипции для пакетной транскрипции
API пакетной транскрипции — это подмножество REST API преобразования речи в текст.
Требуемый идентификатор транскрипции — это значение GUID, содержащееся в основном элементе self тела ответа, возвращаемого запросами, такими как Transcriptions_Create.
Ниже приведен пример тела ответа на запрос Transcriptions_Create. Значение GUID 537216f8-0620-4a10-ae2d-00bdb423b36f , найденный в первом элементе self , является идентификатором транскрипции.
{
"я": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/537216f8-0620-4a10-ae2d-00bdb423b36f",
"модель": {
"я": "https://eastus. api.cognitive.microsoft.com/speechtotext/v3.1/models/base/824bd685-2d45-424d-bb65-c3fe99e32927"
},
"ссылки": {
«файлы»: «https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/537216f8-0620-4a10-ae2d-00bdb423b36f/files»
},
"характеристики": {
"диаризацияВключена": ложь,
"wordLevelTimestampsEnabled": ложь,
"каналы": [
0,
1
],
"punctuationMode": "Продиктовано и автоматически",
"profanityFilterMode": "В маске"
},
"lastActionDateTime": "2021-11-19Т14:09:51З",
"статус": "Не запущен",
"createdDateTime": "2021-11-19T14:09:51Z",
"локаль": "ru-RU",
"displayName": "тест транскрипции"
}
 api.cognitive.microsoft.com/speechtotext/v3.1/models/base/824bd685-2d45-424d-bb65-c3fe99e32927"
},
"ссылки": {
«файлы»: «https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/537216f8-0620-4a10-ae2d-00bdb423b36f/files»
},
"характеристики": {
"диаризацияВключена": ложь,
"wordLevelTimestampsEnabled": ложь,
"каналы": [
0,
1
],
"punctuationMode": "Продиктовано и автоматически",
"profanityFilterMode": "В маске"
},
"lastActionDateTime": "2021-11-19Т14:09:51З",
"статус": "Не запущен",
"createdDateTime": "2021-11-19T14:09:51Z",
"локаль": "ru-RU",
"displayName": "тест транскрипции"
}
api.cognitive.microsoft.com/speechtotext/v3.1/models/base/824bd685-2d45-424d-bb65-c3fe99e32927"
},
"ссылки": {
«файлы»: «https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/537216f8-0620-4a10-ae2d-00bdb423b36f/files»
},
"характеристики": {
"диаризацияВключена": ложь,
"wordLevelTimestampsEnabled": ложь,
"каналы": [
0,
1
],
"punctuationMode": "Продиктовано и автоматически",
"profanityFilterMode": "В маске"
},
"lastActionDateTime": "2021-11-19Т14:09:51З",
"статус": "Не запущен",
"createdDateTime": "2021-11-19T14:09:51Z",
"локаль": "ru-RU",
"displayName": "тест транскрипции"
}
Примечание
Используйте тот же метод, чтобы определить разные идентификаторы, необходимые для отладки проблем, связанных с Custom Speech, например при загрузке набора данных с помощью запроса Datasets_Create.
Примечание
Вы также можете просмотреть все существующие транскрипции и их идентификаторы транскрипций для данного ресурса Speech с помощью запроса Transcriptions_Get.
Обратная связь
Просмотреть все отзывы о странице
Раннее выявление нарушений речи, языка и слуха
Вас беспокоит речь, язык или слух вашего ребенка? Знайте признаки и своевременно обращайтесь за помощью.
На этой странице:
- Определите знаки
- Речевые расстройства
- Нарушения звуков речи
- Заикание
- Нарушения голоса
- Потеря слуха
- Действуйте сегодня
- В поисках помощи
Определите признаки
Дети развиваются со своей скоростью. Некоторые дети рано начинают ходить и говорить. Другие занимают больше времени. Большинство детей осваивают навыки в пределах возрастного диапазона, например, от 12 до 18 месяцев. У ребенка, которому требуется больше времени для освоения навыка, могут возникнуть проблемы.
Важно, чтобы вы знали, чего ожидать. Ниже приведены некоторые признаки проблем с речью, языком и слухом. Вы увидите ожидаемый возрастной диапазон рядом с каждым навыком.
Вы увидите ожидаемый возрастной диапазон рядом с каждым навыком.
Узнайте больше о том, что ожидать от вашего ребенка от рождения до пяти лет. Вы также можете узнать больше о том, как определить знаки.
Речевые расстройства
Язык состоит из слов, которые мы используем, чтобы делиться идеями и получать то, что хотим. Язык включает в себя говорение, понимание, чтение и письмо. У ребенка с языковым расстройством могут быть проблемы с одним или несколькими из этих навыков.
Признаки языковых проблем включают:
| Рождение – 3 месяца | Не улыбаться и не играть с другими |
| 4–7 месяцев | Не болтать |
| 7–12 месяцев | Издает всего несколько звуков. Не использовать жесты, например, махать рукой или указывать пальцем. |
| 7 месяцев–2 года | Непонимание того, что говорят другие |
| 12–18 месяцев | Сказать всего несколько слов |
| 1½–2 года | Два слова не складываются вместе |
| 2 года | Произнесение менее 50 слов |
| 2–3 года | Проблемы с игрой и разговором с другими детьми |
| 2½–3 года | Проблемы с ранним чтением и письмом. Например, ваш ребенок может не любить рисовать или рассматривать книги. Например, ваш ребенок может не любить рисовать или рассматривать книги. |
Вы можете помочь своему ребенку выучить язык по телефону
- Разговаривая, читая и играя с вашим ребенком.
- Слушайте и реагируйте на то, что говорит ваш ребенок.
- Разговаривайте с ребенком на том языке, который вам наиболее удобен.
- Научить вашего ребенка говорить на другом языке, если вы говорите на одном из них.
- Разговор о том, что вы делаете и чем занимается ваш ребенок в течение дня.
- Говорите с ребенком много разных слов.
- Использование более длинных предложений по мере взросления ребенка.
- Пусть ваш ребенок играет с другими детьми.
Нарушения речи Звук
Речь – это то, как мы произносим звуки и слова. Для маленьких детей нормально произносить некоторые звуки неправильно. Некоторые звуки не развиваются, пока ребенку не исполнится 4, 5 или 6 лет. Признаки нарушения звуков речи у детей раннего возраста включают:
| 1–2 года | Не говоря p, b, m, h, и w большую часть времени правильно произнося слова |
| 2–3 года | Не говорить k, g, f, t, d, и n в большинстве случаев правильно произносятся словами. Трудно понять даже людям, хорошо знающим ребенка. Трудно понять даже людям, хорошо знающим ребенка. |
Вы можете помочь своему ребенку научиться произносить звуки по номеру
- Как правильно произносить звуки, когда вы говорите. Вашему ребенку нужны хорошие модели речи.
- Не исправляются звуки речи. Ничего страшного, если ваш ребенок произносит некоторые звуки неправильно.
Заикание
Большинство из нас делают паузу или повторяют звук или слово, когда говорят. Когда это происходит часто, человек может заикаться. Маленькие дети могут некоторое время заикаться. Это нормально и со временем пройдет. Признаки того, что заикание не прекращается, включают:
| 2½–3 года |
|
Вы можете помочь своему ребенку, позвонив по телефону
- . Дайте ребенку время поговорить.
- Не перебивайте и не останавливайте ребенка, когда он говорит.
- Обратите внимание, если ваш ребенок расстраивается, когда заикается. Обратите внимание на то, как она говорит. Дети, которые заикаются, могут закрывать глаза или двигать лицом или телом во время разговора.
 Дайте ребенку время поговорить.
Дайте ребенку время поговорить.Нарушения голоса
Мы используем свой голос, чтобы издавать звуки. Наш голос может измениться, если мы используем его неправильно. Мы можем потерять голос, когда болеем или после того, как много разговариваем или кричим. Признаки того, что у вашего ребенка может быть нарушение голоса, включают:
- Хриплый, скрипучий или хриплый голос.
- Гнусавое звучание или как будто они говорят через нос.
Вы можете помочь своему ребенку:
- Обратитесь к врачу, если голос вашего ребенка звучит по-другому и не исчезает через короткое время.
- Скажите ребенку не кричать и не кричать.
- Держите ребенка подальше от сигаретного дыма.
Потеря слуха
У некоторых детей потеря слуха возникает при рождении. Другие теряют слух по мере взросления. Вот некоторые признаки того, что у вашего ребенка может быть потеря слуха:
| Дата рождения–1 год | Не обращая внимания на звуки |
| 7 месяцев–1 год | Не отвечает, когда зовешь ее по имени |
| 1–2 года | Не следуя простым указаниям |
| От рождения до 3 лет | Задержка речи и языка |
Вы можете помочь своему ребенку:
- Убедитесь, что ваш ребенок прошел проверку слуха у новорожденных.
- Отведите ребенка к врачу, если у него ушная инфекция.
- Обратитесь к аудиологу, если вы беспокоитесь о слухе вашего ребенка.
Действуйте сегодня
Лучше получить помощь заранее, чем ждать.