App Store: Яндекс — с Алисой
Описание
Быстрый поиск с умными подсказками и Алиса, которая ответит на любой вопрос. Ищите в Яндексе так, как вам удобно: текстовым запросом в строке поиска; голосом — здесь поможет Алиса; по фото, картинке и объектам окружающего мира — в Умной камере. А ещё приложение подскажет, кто звонит с незнакомого номера, поможет сэкономить на дорогих покупках, разобраться в сложных вопросах и решать другие повседневные задачи.
Текстовый и голосовой поиск. Ищите как вам удобно: привычными текстовыми запросами с быстрыми подсказками и мгновенными ответами или голосом, если набирать текст неудобно.
Умная камера. Наведите на что угодно и посмотрите, что будет. Умная камера распознаёт предметы, рассказывает о них и советует, где купить; переводит надписи, открывает QR-коды и даже заменяет собой сканер.
Алиса. Голосовой помощник Яндекса ответит на любой вопрос и поможет в повседневных делах: поставит таймер и напомнит о делах, подскажет погоду и пробки, поиграет с детьми, расскажет им сказку или споёт песенку.
Бесплатный автоматический определитель номера. Включите АОН в меню настроек или попросите: «Алиса, включи определитель номера». Он покажет, кто звонит, даже если номера нет в контактах. База данных из более 5 миллионов организаций и отзывы пользователей сэкономят время и защитят от нежелательных разговоров.
Поиск товаров. Спросите: «Алиса, где дешевле?» и расскажите, что хотите купить. Алиса найдёт ваш товар среди предложений десятков тысяч магазинов — от маркетплейсов и гипермаркетов до небольших магазинов в вашем городе или районе — сравнит цены и покажет лучшую. Вам останется перейти в магазин и оформить покупку, не тратя лишнего.
Приложение доступно для iPhone и iPad. Погода с точностью до района. Подробный почасовой прогноз на текущий день с динамической картой осадков, ветров, температуры и давления. И ежедневный — на неделю вперёд с детальной информацией о скорости ветра, атмосферном давлении и уровне влажности.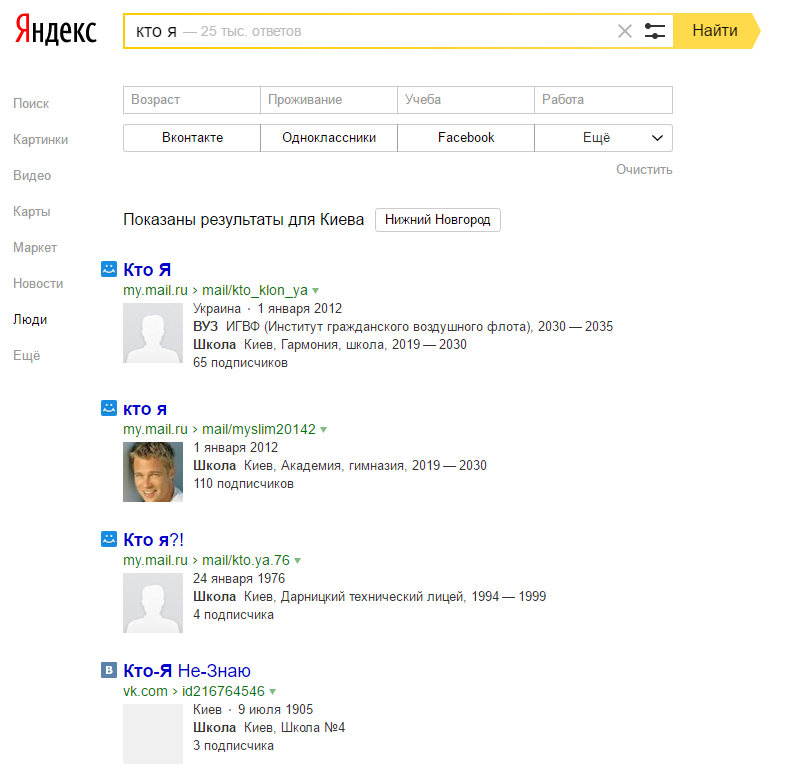
Приложение доступно для iPhone и iPad.
Загружая программу, Вы принимаете условия Лицензионного соглашения https://yandex.ru/legal/search_mobile_agreement/
Версия 23.1.8.61
Учли ваши отзывы и исправили мелкие ошибки. Теперь приложение работает лучше.
Оценки и отзывы
Оценок: 646,7 тыс.
Лучшие из лучших
Отличный сайт в Яндекс по запросу «Pepebonus». Спасибо большое разработчикам за внедрение синхронного перевода. Это большой труд и огромный вклад в развитие образовательной и не только сферы.
10 из 10.
 10 из 10.
10 из 10.Нам очень приятно, спасибо! Комментарии довольных пользователей вдохновляют добавлять новые фишки в приложение 💪😉
Алиса
В iOS 14 появились виджеты, добавьте пожалуйста Алису как отдельный виджет ☺️
Спасибо за идею. Быстрый доступ к Алисе уже есть в виджете приложения — вместе с погодой, пробками и всем остальным. Про отдельный виджет мы тоже подумаем — следите за обновлениями.
Только Яндекс
Я не пользуюсь никакими другими браузерами. Может быть я привыкла за столько лет, а может быть это на самом деле самый удобный поисковик!!! Нравится все, вплоть до Алисы)) Сири откровенно тупая по сравнению с ней🤷♀️
Спасибо! Приятно знать, что приложение вам понравилось.
 Рады, что вы с нами! 🙂
Рады, что вы с нами! 🙂Разработчик Yandex LLC указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
Следующие данные могут использоваться для отслеживания информации о пользователе в приложениях и на сайтах, принадлежащих другим компаниям:
- Геопозиция
- Контактные данные
- История поиска
- История просмотров
- Идентификаторы
- Данные об использовании
Связанные с пользователем данные
Может вестись сбор следующих данных, которые связаны с личностью пользователя:
- Финансовая информация
- Геопозиция
- Контактные данные
- Контакты
- Пользовательский контент
- История поиска
- История просмотров
- Идентификаторы
- Данные об использовании
- Диагностика
- Другие данные
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Yandex, LLC
- Размер
- 396,3 МБ
- Категория
- Утилиты
- Возраст
- 17+ Неограниченный доступ к Сети Малое/умеренное количество азартных игр Малое/умеренное количество использования или упоминания алкогольной и табачной продукции или наркотических средств Малое/умеренное количество контента сексуального или эротического характера Малое/умеренное количество медицинской или лечебной тематики Малое/умеренное количество сквернословия или грубого юмора
- Copyright
- © 2011-2023 Yandex LLC
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Поддерживается
Другие приложения этого разработчика
Вам может понравиться
Как Яндекс научился распознавать, что написано в рукописных архивах / Хабр
Привет, Хабр. Меня зовут Саша, в прошлый раз я рассказывал сообществу про поиск организаций в Яндексе. В этот раз мы вновь поговорим про поиск, но уже совершенно другого рода. Сегодня расскажем про «Поиск по архивам». Этот проект вырос из моего личного интереса к истокам семьи, но в итоге (хочется верить!) поможет тысячам других таких же пользователей чуть больше узнать о своих корнях.
Меня зовут Саша, в прошлый раз я рассказывал сообществу про поиск организаций в Яндексе. В этот раз мы вновь поговорим про поиск, но уже совершенно другого рода. Сегодня расскажем про «Поиск по архивам». Этот проект вырос из моего личного интереса к истокам семьи, но в итоге (хочется верить!) поможет тысячам других таких же пользователей чуть больше узнать о своих корнях.
Генеалогическое исследование — очень трудоёмкий процесс. Информация о родственниках разбросана по разным архивам, запросы на получение данных могут обрабатываться долго, а доступ даже в открытые архивы ограничен. Несмотря на то что оцифровка архивных документов ведётся уже более десяти лет, по ним не так-то просто искать — придётся отсматривать вручную множество сканов в надежде найти фамилию предка.
Чтобы упростить этот процесс, мы научились превращать в текст сканы архивных документов. Основная сложность этой задачки заключалась в том, что текст в архивах написан от руки. Машинописный текст всё-таки создан по предсказуемым правилам: автор использует набор уже известных шрифтов. А рукописный текст уникальный, потому что каждый человек пишет по-своему. Кроме того, архивные документы написаны не просто от руки, но и на дореволюционном русском языке, который существенно отличается от современного.
А рукописный текст уникальный, потому что каждый человек пишет по-своему. Кроме того, архивные документы написаны не просто от руки, но и на дореволюционном русском языке, который существенно отличается от современного.
Решению этой задачи мы и посвятим историю. А поможет мне с ней Таня @miryable из команды, которая уже много лет развивает в Яндексе технологию оптического распознавания символов (OCR).
С чего всё началось
Около двух лет я занимался поиском информации об истории своей семьи. За это время я не только смог найти данные о предках вплоть до второй половины XVII века, но и успел разочароваться в самом процессе «раскопок». Найти подходящий архив уже проблема. Для этого нужно или иметь профильное образование по архивному делу, или пообщаться с историками, которые подскажут направление.
Получить документы из архива тоже не всегда просто. Если у архива нет электронного доступа, то нужно записаться, приехать, получить какую-то небольшую порцию книг и отсмотреть их прямо на месте.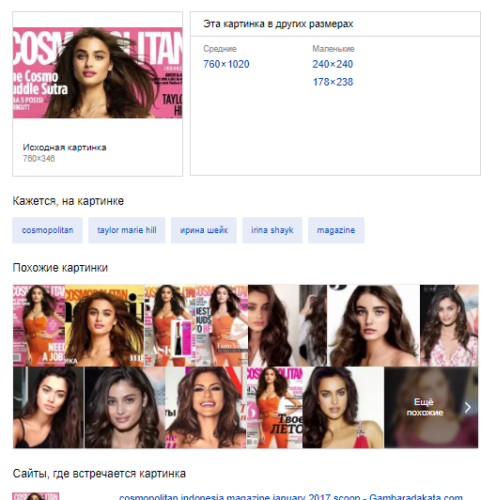 У некоторых архивов есть электронный доступ, но их вычислительные ресурсы и ширина канала связи часто ограничены, что сказывается на скорости загрузки таких сканов.
У некоторых архивов есть электронный доступ, но их вычислительные ресурсы и ширина канала связи часто ограничены, что сказывается на скорости загрузки таких сканов.
Неудивительно, что в какой-то момент родилась мысль упростить это дело с помощью наших технологий. Пришёл в команду, которая отвечает за OCR в Яндексе. Коллеги поддержали идею. Ну а дальше мы собрали на коленке прототип, показали его руководителям, получили благословение и отправились делать.
Подключаем архивы
Мы договорились с несколькими архивами, что возьмём их материалы для обучения нейросетей. Нас интересовали документы, которые связаны с историей семьи, другими словами — те, в которых могла содержаться генеалогическая информация:
Метрические книги — документы для актовых записей о рождении, браке или смерти в период с начала XVIII века по 1918 год.
Ревизские сказки — результаты проведения подушных переписей населения Российской империи в начале XVIII — 2-й половине XIX веков.
Исповедные ведомости — ежегодный отчёт по каждому приходу православной церкви в Российской Империи в XVIII — начале XX веков.

Сейчас мы работаем с документами из архива города Москвы, архивами Оренбургской и Новгородской областей. Надеемся, что к ним скоро присоединятся архивы из других регионов.
Разметка страниц
Модель для распознавания печатного текста можно обучить на синтетических данных, сгенерировав миллионы изображений. Однако для рукописного текста такой сценарий не работает: он более вариативен, искусственно промоделировать его невозможно.
Исторические тексты очень сложно читать, поэтому мы пригласили экспертов по работе с архивными документами. Они помогли расшифровывать тексты и разметить сканы. Для обучения модели нам нужно было выделить многоугольником каждую строку, ввести её текстовую расшифровку, а также сгруппировать все строки в смысловые блоки. Блоки нужны, в том числе и для того, чтобы текст из разных колонок не перемешивался, а получался связным.
На этом этапе было важно определить единое понятие «смыслового блока», потому что количество краевых случаев было просто безграничным. Порой на одной картинке получалось до 300 смысловых блоков, и ведь это даже не строки, которых ещё больше! А для каждой картинки из обучения нужно было разметить абсолютно все строки и блоки, чтобы не путать нейросеть неразмеченными текстами.
Пример полной разметки одной страницыВо время работы было место интересным открытиям и наблюдениям. Особенно наши расшифровщики и расшифровщицы обращали внимание на имена. Иногда можно было встретить что-то необычное: например, однажды они нашли Фиону, а до этого — Елпидофора.
В итоге мы получили первую обучающую выборку для нейросети из 2000 рукописных документов.
Работы над моделью автоматической расшифровки
Дальше началось самое интересное. Нам необходимо было сделать систему, способную автоматически расшифровывать старые документы.
Для рукописного текста из-за разнообразия почерков необходимо более глубокое знание о языковой модели. Если для печатных тестов возможно базовое распознавание с минимальными знаниями о языковой модели, то в случае рукописного текста зачастую сложно даже примерно понять, какое слово написано. Особенно без знания языка конкретного времени.
Если для печатных тестов возможно базовое распознавание с минимальными знаниями о языковой модели, то в случае рукописного текста зачастую сложно даже примерно понять, какое слово написано. Особенно без знания языка конкретного времени.
Ещё один вызов, с которым нам предстоит работать: одно и то же написание у разных писарей может означать разные буквы. Из-за этого нам необходимо учитывать глобальный контекст всего документа для распознавания каждого отдельного слова. Иногда, чтобы разобрать то или иное слово, нужно посмотреть, как у конкретного писаря выглядит определённая буква в других словах.
В Яндексе уже была своя технология распознавания текста, и первым делом мы, конечно же, решили начать с того, чтобы адаптировать ее под новую задачу. Тут можно выделить три крупных этапа: детекция строк, расшифровка отдельной строки и группировка полученных строк в смысловые блоки. Расскажем о них подробнее.
Детекция строк
Первый этап в распознавании документа — это детекция местоположения каждой отдельной строки.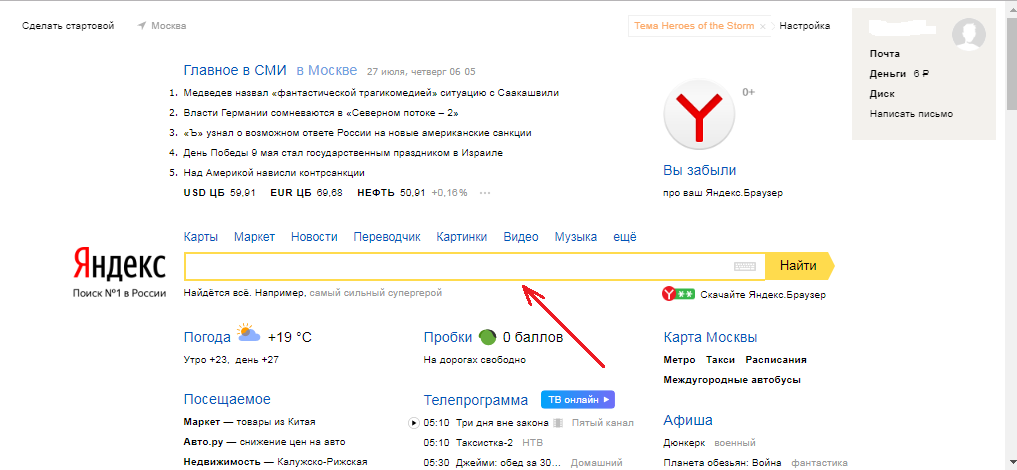 В отличие от классических задач Object Detection, где нужно найти на фотографии котика, собачку или припаркованные автомобили, строки текста бывают очень вариативными по соотношению сторон: может быть длинная строка на два разворота книги, а может быть одиночная цифра как номер страницы. Они также могут быть одновременно как горизонтальными, так и вертикальными на одной странице: например, в названии колонки.
В отличие от классических задач Object Detection, где нужно найти на фотографии котика, собачку или припаркованные автомобили, строки текста бывают очень вариативными по соотношению сторон: может быть длинная строка на два разворота книги, а может быть одиночная цифра как номер страницы. Они также могут быть одновременно как горизонтальными, так и вертикальными на одной странице: например, в названии колонки.
Из-за таких особенностей сильно ограничиваются возможности классических подходов к детекции. Как правило, они предсказывают уточнение позиций предопределённого набора «якорных прямоугольников». Но из-за такой вариативной структуры старого документа их было бы необычайно много.
Альтернативный подход — решать задачу сегментации. То есть предсказывать для каждого пикселя на изображении, относится ли он к тексту или нет, а потом брать компонент, состоящий из текста, и считать его строкой. Но такой вариант не подойдёт по двум причинам:
Но такой вариант не подойдёт по двум причинам:
для рукописных архивных данных из-за различных завитушек отдельные строки очень часто пересекаются;
недостаточно просто предсказать, является ли кусок текстом или нет, необходимо ещё объединить его в строку, а делать какую-то ручную постобработку всегда хуже, чем обучаемую.
В своём решении мы опирались на статью Character Region Awareness for Text Detection. Для каждого пикселя изображения мы предсказываем, является ли он текстом. Причём эти предсказания не бинарные, а Gaussian heatmap относительно центра символа: чем ближе к центру, тем выше должно быть предсказываемое значение, чтобы рядом стоящие строки не смешивались. Также мы предсказываем карту связей между символами в строке, что позволяет уйти от ручного постпроцессинга при склейке.
Для начала мы просто попробовали нашу версию детекции, обученную на печатных данных. К нашему удивлению, она вполне себе заработала и на рукописных.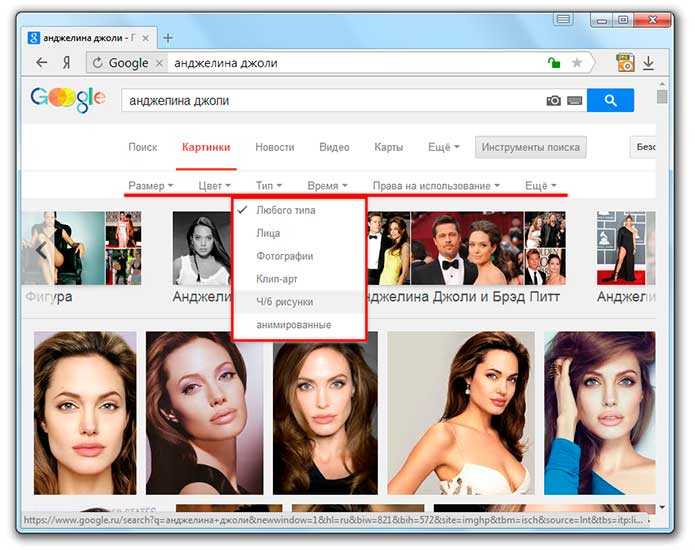 Пусть и с рядом недочётов: находилось много шума, разрывались строки. Но детекция училась на данных, в котором рукописного текста не было в принципе. То, что она заработала, говорит о том, что наша технология уже применима к очень широкому кругу задач.
Пусть и с рядом недочётов: находилось много шума, разрывались строки. Но детекция училась на данных, в котором рукописного текста не было в принципе. То, что она заработала, говорит о том, что наша технология уже применима к очень широкому кругу задач.
Далее мы обучили модель на тех данных, которые мы получили из расшифровки рукописных документов. Детекция стала чище и точнее.
Результат работы детектора, обученного на печатных текстахА это результат работы детектора, когда мы дообучили модель на 2000 реальных данных, полученных из размеченных рукописных страницПосле этого нужно было решить ещё одну проблему. Как я говорил, у архивных документов сложная структура: они могут быть записаны в виде таблиц или колонок, а ещё фрагменты разных текстов могут плотно стоять друг к другу. Поэтому очень часто детекция распознавала как одну строку то, что было написано в разных блоках.
Тут изображён текст в разных колонках, который детектор ошибочно склеил вместе. Цветом выделены строки, которые нашёл детекторЭту задачу мы решили на уровне модели группировки в абзацы — подробнее расскажу после раздела о расшифровке строк. На том этапе мы смирились с этой трудностью непосредственно для модели детекции строк и занялись решением другой проблемы — просветами текста на обороте страницы.
На том этапе мы смирились с этой трудностью непосредственно для модели детекции строк и занялись решением другой проблемы — просветами текста на обороте страницы.
На сканах часто был виден текст, который просвечивался с другой стороны: из-за подсветки сканера или пропечатавшихся чернил. А наш детектор оказался очень кропотливым и считал, что это текст, который он тоже должен находить. Само собой, такое распознавание было ложным, а из-за того, что оно подмешивалось к реальному распознаванию, в итоге мы получали не всегда связанный текст. Особенно остро эта проблема была видна на машинописных архивах, но и нередко встречалась на рукописных.
Пример просвета строкМы отправили примеры с просветами на дополнительную разметку непосредственно этой детекции. После обучения на новых данных модель стала показывать более чистый результат. Однако просвеченный текст всё ещё появляется в результатах — это то, что нам предстоит доработать.
Расшифровка строк
Следующий, и, пожалуй, самый сложный шаг — обучить модель расшифровывать то, что содержит вырезанная детектором строка. То есть распознать последовательность символов из последовательности пикселей строки, вырезанной в той области, которую нашёл детектор.
То есть распознать последовательность символов из последовательности пикселей строки, вырезанной в той области, которую нашёл детектор.
На этом этапе наши стандартные модели расшифровки не подошли. Во-первых, обученные на машинописных текстах модели почти никак не работают на рукописных данных. Во-вторых, имеют место и особенности языка тех времён.
В архивах часто встречаются документы, которые были составлены на церковнославянском языке. В нём были символы, которые сейчас мы не используем: например, буквы ѣ (ять), ѳ (фита), ѵ (ижица), юс большой и малый (Ѫ, Ѧ). Чтобы пользователь мог найти информацию в документах, нужно научить модель распознавать эти и другие буквы. И чем больше мы найдём разных вариантов написания этих символов, тем проще будет нашей нейросети.
Пример разных вариантов написания букв скорописью, которой в основном и велись документыК тому же мы заметили, что часто в документах некоторые слова, например, «месяц» или «сын», сокращали и писали через титло — небольшую волнистую или зигзагообразную линию. Было важно, чтобы модель могла распознавать этот символ, а не считать его за пыль или случайную черту.
Было важно, чтобы модель могла распознавать этот символ, а не считать его за пыль или случайную черту.
Ещё одна интересная особенность — выносные буквы. Они встречаются в документах XV — 1-й половины XVIII века. Это ещё один вариант сокращения слов, когда над строкой появлялась согласная. Этот момент тоже нужно учитывать при обучении модели.
Слово «месяца» на первой строке записано с титлом, а слово «восприемником» на второй и третьей строках — с выносомРешать задачу sequence-to-sequence распознавания можно несколькими способами:
Для каждого фрейма (в конкретной позиции по горизонтали) предсказывать, какой символ в нём изображён, например, с помощью свёрточной нейронной сети, и далее использовать CTC-loss. В этом случае для изображения, где написано «Марья», нейросеть предскажет, «МММ__аа_ррр___ььь_яя». Склеив одинаковые предсказания в соседних фреймах мы получим правильное предсказание.
Использовать подходы, в которых нейросеть сама предсказывает последовательность символов, не привязываясь к их геометрической позиции (такие как, например, RNN или TRANSFORMER-based).

Из-за описанных выше особенностей, таких как титло и выносные буквы, первый подход не работал, потому что в одной позиции по горизонтали может быть сразу несколько символов. Это подтвердилось и нашими экспериментами, поэтому в результате мы использовали второй подход, а именно — RNN based decoder with attention.
Для распознавания выносных букв мы также подавали на вход распознаванию не чёткую область детекции, а немного расширенный вариант. За счёт этого сеть получала информацию о контексте.
Далее мы провели ряд экспериментов и поняли, что качество получаемой модели сильно зависит от объёма данных, на которых она учится. Есть два варианта, как решить проблему нехватки данных: предобучить модель на синтетических данных или применить различные способы аугментации.
Аугментация, или генерирование новых данных на основе имеющихся, позволяет довольно просто и дешево решить часть проблем с обучающей выборкой подручными способами. Мы попробовали по-разному вырезать одни и те же строки, чтобы они немного отличались: например, исходя из того, как их нашел детектор или как наши коллеги разметили страницу.
Также мы пробовали зашумление картинок: размытость, расфокус, засветы, замену фона. Другими словами, мы пробовали хоть как-то разнообразить реальные тексты. В итоге мы получили датасет из 4 млн строк.
Расскажу ещё об одном интересном моменте. В одном из экспериментов мы обучили модель на очень небольшом количестве реальных данных. Записи в метрических книгах специфичны и однотипны, поэтому нейросеть научилась находить текст там, где его нет. Например, в каком-то шуме, или в узоре, который наш детектор строк ошибочно определил как строку текста, она могла прочитать какое-то слово или даже осмысленную строку.
Вот в этом узоре модель прочитала фразу «Рязанской губерніи»Это говорит о том, что в задаче распознавания рукописного текста большой вес имеет выучиваемая языковая модель.
И тут уже никак не поможет аугментация картиночных данных, которую мы использовали. В этом случае сам текст никак не меняется — меняется только картинка, и модель не учит из этого ничего нового в части языковой модели.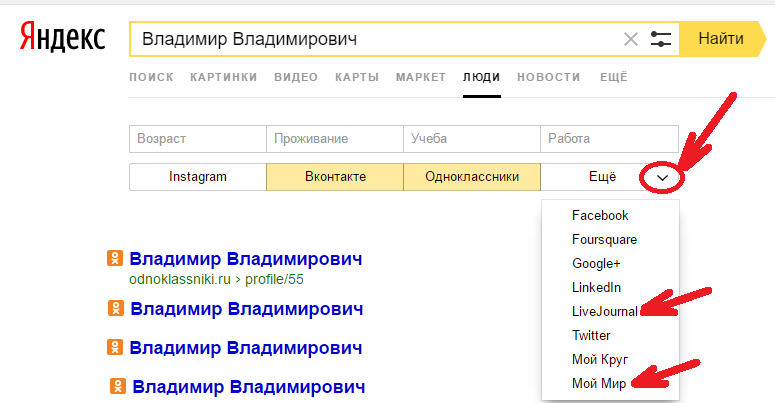
Чтобы исправить ситуацию, нам пришлось досыпать в обучение модели различных текстов, чтобы улучшить языковую часть. Для этого мы использовали синтетически сгенерированные изображения с текстами того времени — в основном художественную литературу, например, «Анну Каренину». С их помощью модель узнала, что тексты — это не только метрические книги, и таким образом получила представление о том, как был устроен язык тех времён.
Группировка в абзацы
Итак, мы нашли строки и распознали их — теперь нужно объединить полученное в семантически связанные фрагменты. Это объединение поможет нам получить связную по смыслу область текста, в которой мы сможем правильно обрабатывать переносы слов между строками и корректно искать информацию по тексту документа.
Для этого мы сделали отдельную модель, которая детектирует смысловые блоки на изображении. Но как мы помним, структура текста в архивных документах очень сложная и здесь недостаточно просто выделить прямоугольник — он может содержать сразу несколько смысловых блоков. Например, информация о семье и код, который относится к чему-то ещё. При этом, как и для детекции строк, рядом стоящие абзацы могут пересекаться.
Например, информация о семье и код, который относится к чему-то ещё. При этом, как и для детекции строк, рядом стоящие абзацы могут пересекаться.
Эту задачу мы решали как Instance Segmentation, когда необходимо для каждого блока предсказать не только прямоугольник, задающий область абзаца, но также маску внутри этого прямоугольника, которая более точно описывает конкретный абзац.
Вот пример страницы с блоками. Обратите внимание на нижний левый угол, где как раз есть пересечение bounding box — без маски тут никак не обойтисьЗдесь одна из проблем была в том, что у входного изображения большой размер — до 10 000 пикселей по одной стороне. Обучить модель на таком разрешении было бы очень сложно, потому что обучение требовало бы огромных ресурсов GPU.
Мы уже начали думать о вариантах разбиения картинки на части, но мы рисковали потерять общий контекст целого изображения. Мы составили план серии экспериментов, чтобы заставить это всё работать. И буквально ради шутки мы подумали: а что если очень сильно ресайзить картинку до стандартного размера и попробовать запустить как есть. Оказалось, что всё заработало на очень хорошем уровне.
Оказалось, что всё заработало на очень хорошем уровне.
На данный момент мы расшифровали и открыли для поиска около 2,5 млн страниц из архивных документов. Для этого коллеги даже применили «осовременивание» текстов, чтобы, например, по запросу «Петров» можно было найти документы с «Петровъ». Конечно, у нас ещё много нерешённых задачек и работы. Но то, что мы видим сейчас, по мнению людей, работающих с архивными документами, это уже большой шаг вперёд. На расшифровку одной страницы архивного рукописного текста специалист тратит около получаса, а нашей нейросети требуется всего несколько секунд.
Хочется верить, что так мы сделаем важные генеалогические сведения доступней и поможем тем, кто зашёл в тупик в поисках информации о своих предках.
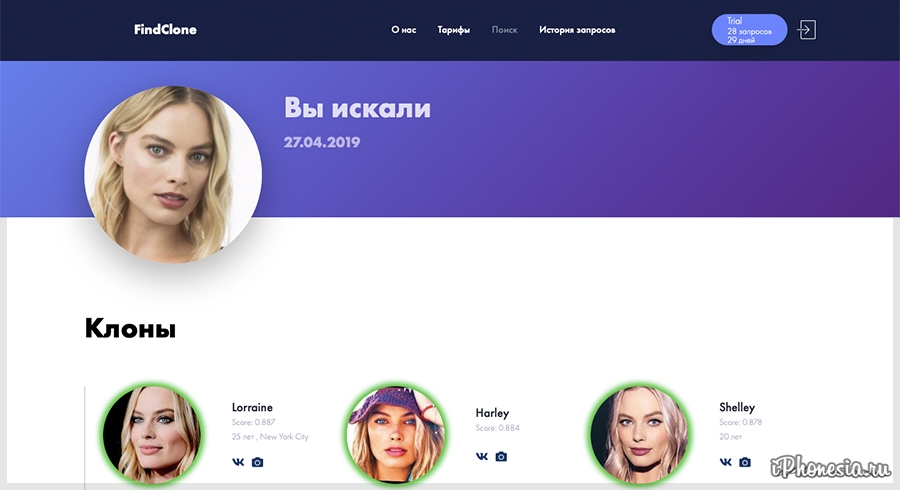
Поиск обратных изображений Яндекса и лучшие альтернативы [Список 2023]
Главная » Онлайн-сервисы » Поиск обратных изображений Яндекса и лучшие альтернативы [Список 2023]
все, что вам нужно сделать, это ввести слово или фразу в поисковую систему, такую как Google, и она покажет вам ссылки на веб-сайты, которые могут дать вам больше информации об этом. Что касается изображений, если вы хотите узнать имя человека по фотографии, это кажется невозможным, потому что вы не знаете его имени. Вы можете подумать, что единственное решение — опубликовать фото на форуме в надежде, что кто-нибудь узнает человека по фотографии и скажет вам имя.
Что касается изображений, если вы хотите узнать имя человека по фотографии, это кажется невозможным, потому что вы не знаете его имени. Вы можете подумать, что единственное решение — опубликовать фото на форуме в надежде, что кто-нибудь узнает человека по фотографии и скажет вам имя.
К счастью, есть так называемый обратный поиск изображений, где вы можете выполнить поисковый запрос на основе изображения, а не ключевого слова. Это может быть очень полезно для сценария, о котором мы упоминали выше, а также для веб-мастеров, чтобы увидеть, кто использовал ваши фотографии или изображения, защищенные авторским правом, без вашего разрешения.
Здесь у нас есть 5 онлайн-сервисов, которые можно использовать для бесплатного обратного поиска изображений.
1. Google Image Search
Google не только является ведущей поисковой системой для текстовых запросов, но и их обратный поиск изображений также является одним из лучших. Все, что вам нужно сделать, это посетить Google Images в своем веб-браузере, щелкнуть значок камеры (при наведении курсора мыши на значок появится метка «Поиск по изображению»), и вам будет предоставлена возможность вставить полный URL-адрес изображение, которое вы хотите найти или загрузить со своего компьютера.
Google Image Search может не только сообщить вам, какие веб-сайты ссылаются на искомое изображение, но и в нижней части результатов поиска также показывают изображения, которые визуально похожи. В качестве дополнительного совета веб-браузер Google Chrome позволяет вам удобно искать изображение на веб-сайте, щелкнув правой кнопкой мыши изображение и выбрав «Найти это изображение в Google».
Посетите Поиск картинок Google
2. Яндекс Картинки
Яндекс — самая популярная поисковая система в России, похожая на Google, у них тоже есть функция поиска картинок. В отличие от Google Image Search, который имеет интеллектуальный алгоритм, который пытается угадать человека на изображении, Яндекс показывает только, где используется изображение, а также список разных размеров. Если изображение не найдено, то Яндекс попытается показать любые похожие изображения.
Выполнение обратного поиска картинок в Яндексе очень похоже на поиск картинок Google.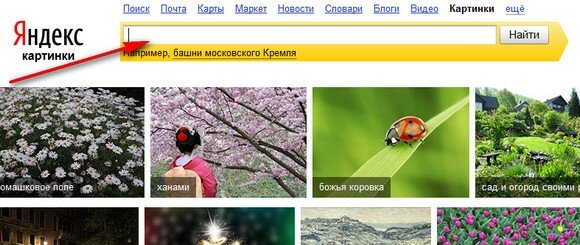 Нажмите на значок камеры, расположенный в крайнем правом углу панели поиска, и вы сможете либо загрузить изображение, либо выполнить поиск по URL-адресу.
Нажмите на значок камеры, расположенный в крайнем правом углу панели поиска, и вы сможете либо загрузить изображение, либо выполнить поиск по URL-адресу.
Посетите Yandex Images
3. TinEye
TinEye — первая веб-система обратного поиска изображений, которая, вероятно, была запущена примерно в 2008 году и на данный момент проиндексировала почти 8 миллиардов изображений. Вы можете искать изображение, загрузив его со своего компьютера или вставив URL-адрес изображения или даже веб-страницы, где будут автоматически отображаться все изображения со страницы.
Если вы довольно часто используете TinEye, вы можете установить подключаемый модуль браузера TinEye, доступный для Firefox, Chrome, Safari, Internet Explorer и Opera, чтобы упростить процесс поиска изображений. Приятная функция TinEye — это возможность сортировать результаты на основе наиболее подходящего, наиболее измененного, самого большого изображения, самого нового и самого старого. Существует также полезная функция сравнения, с помощью которой вы можете легко проверить разницу между вашим изображением и найденным изображением одним щелчком мыши. Обратите внимание, что TinEye бесплатен для некоммерческого использования, а платная версия позволяет использовать API.
Существует также полезная функция сравнения, с помощью которой вы можете легко проверить разницу между вашим изображением и найденным изображением одним щелчком мыши. Обратите внимание, что TinEye бесплатен для некоммерческого использования, а платная версия позволяет использовать API.
Посетите TinEye
4. MyPicGuard
MyPicGuard — еще одна система обратного поиска изображений, целью которой является поиск тех, кто использует ваши изображения. Вам нужно будет зарегистрировать бесплатную учетную запись, которая автоматически дает вам 100 кредитов бесплатно, чтобы начать использовать. Обратный поиск по одному изображению израсходует 1 кредит. MyPicGuard кажется новым сервисом (вероятно, все еще находится в стадии бета-тестирования), и мы не смогли найти способ пополнить кредиты, даже если бы захотели. Шаги для начала использования MyPicGuard немного сложны и длинны по сравнению со службой изображений обратного поиска, о которой мы упоминали выше.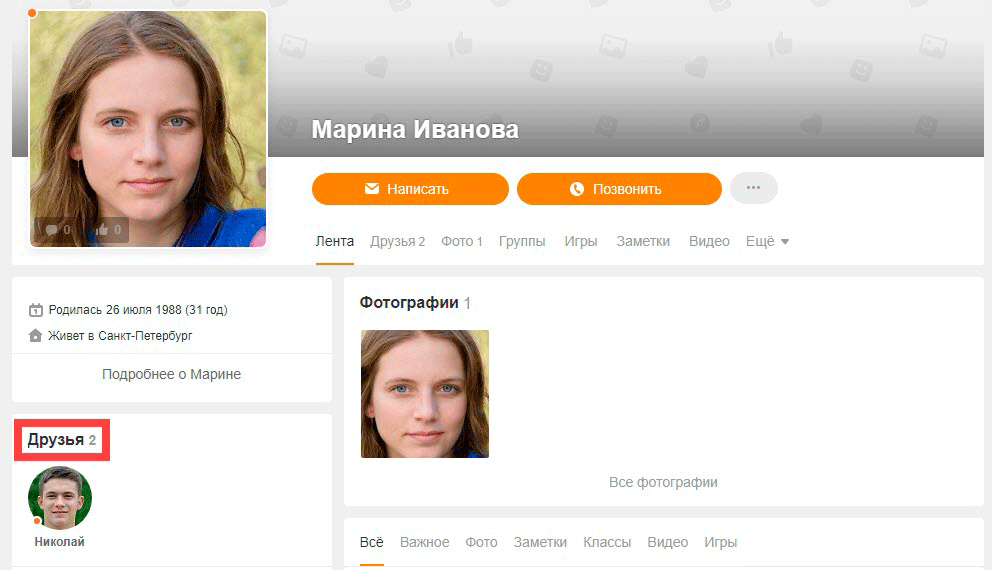
После регистрации войдите в систему и перейдите на страницу сканирования. Разверните «Изображения» и щелкните папку «Сканировать». Чтобы загрузить файлы, щелкните значок диска и просмотрите файл на своем компьютере. После того, как файл будет загружен в папку сканирования, нажмите кнопку в правом нижнем углу с надписью «Нажмите для сканирования». Затем вам будет предложено выполнить автоматическое сканирование, например, один раз в день, два раза в неделю, один раз в месяц или просто однократное сканирование, нажав кнопку «Начать обычное сканирование».
Теперь вы можете закрыть окно и дождаться уведомления по электронной почте о завершении сканирования (обычно сканирование занимает всего пару секунд). Посетите страницу результатов, и число, указанное в правом верхнем углу, представляет собой количество ссылок, найденных с использованием загруженного изображения.
Посетите MyPicGuard
5. Image Raider
Как и большинство систем обратного поиска изображений, Image Raider позволяет вам указать URL-адрес или загрузить изображение с вашего компьютера, чтобы проверить в Интернете, кто использует изображение. Image Raider использует кредитную систему, при которой новая регистрация автоматически награждает вас 300 кредитами бесплатно, и каждый поиск изображения использует 1 кредит.
Image Raider использует кредитную систему, при которой новая регистрация автоматически награждает вас 300 кредитами бесплатно, и каждый поиск изображения использует 1 кредит.
Image Raider не имеет собственного алгоритма обратного поиска изображений или робота, который сканирует Интернет и индексирует обнаруженные изображения. Он просто собирает результаты поиска изображений из Google, Bing и Яндекс, представляя вам консолидированный результат, содержащий такую информацию, как имя домена с метрикой, называемой полномочием домена, количество изображений и страниц. Вы также можете щелкнуть значок белого списка, чтобы скрыть определенный домен из результатов.
Посетите Image Raider
Приложение для поиска изображений в App Store
Описание
«Поиск изображений» позволяет искать изображения с помощью Google Image Search, Bing Image Search и Yandex Image Search. Это приложение поможет вам проверить, являются ли чьи-то фотографии реальными или просто скопированы из Интернета.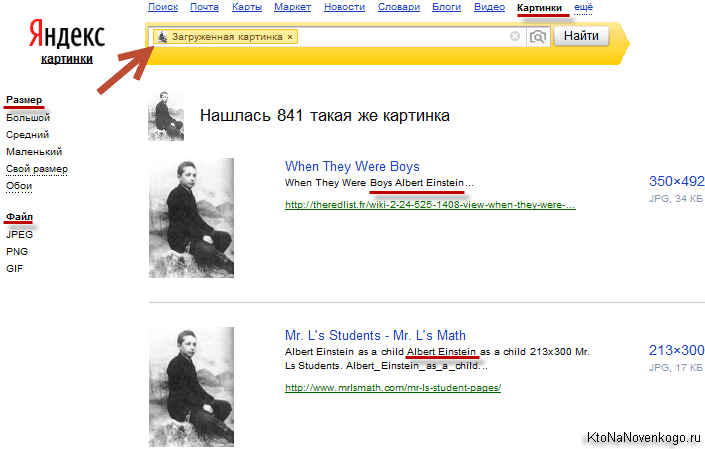
# Основные функции
● Обратный поиск изображений через Google / Bing / Yandex
● Поиск изображений по фотографиям/изображениям из Галереи или Фотопленки
● Поиск изображений по веб-адресу изображения / URL-адресу
● Поиск изображений путем вставки изображения из буфера обмена
● Редактирование и обрезка изображений перед поиском
● Поиск похожих изображений и получение информации о ком-либо по фотографии
Версия 1.5
◉ Исправление ошибок
Рейтинги и обзоры
593 Оценки
Рад, что скачал.
Работает лучше большинства.
Единственная реальная жалоба заключается в том, что кнопка «Назад» возвращает вас к выбору изображения для поиска вместо результатов поиска.
Здравствуйте! Спасибо за ценный отзыв. Мы будем работать в этом направлении в следующих обновлениях.
РАЗДРАЖАЮЩИЙ
На мой взгляд, работает не очень хорошо. О, одна звезда, потому что я искренне верю, что любой, кто пытается придумать полезное приложение, которое поможет людям узнать, что что-то потенциально может быть или не быть, является отличной идеей. приложение просит меня оценить его, прежде чем я на самом деле его использовать. Я искал два элемента и до сих пор нашел то, что только что нашел, нашел другое, но, поскольку это приложение так сильно хочет ленту «Я участвовал», что это стало раздражать меня, я дал ему один ».
Хорошо, почему бы и нет, я оставил хорошо продуманный отзыв для всеобщего ознакомления. Хотя, поверьте мне, просто нажмите кнопку «Мне нравится», «Поделитесь», «Нравится», Расскажите людям, как удивительно полезен был для вас мой отзыв. Вам даже не нужно это читать, просто примите мои слова за это. Я это прикрыл!
Я могу поискать еще кое-что, а затем вернуться с хорошо написанным документом, в котором точно описывается, как это работает.
Привет! Нам очень жаль, что ваш опыт не оправдал ваших ожиданий. Вы можете обновить свои оценки, как только попробуете и найдете это приложение полезным.
Приложение заблокировано и на мне
Это приложение работало у меня первые три раза, когда я пытался исследовать предмет. Однако в последний раз, когда я щелкнул изображение, которое я нашел в их «галерее» возможных предложений, я больше не смог загрузить свои изображения другого предмета, который я хотел исследовать.
Я не знаю, как выйти из этой петли.
Кто-нибудь, пожалуйста, помогите.
 Я только что получил сообщение, что «Я, Джейн, нет доступных токенов», я могу купить что-нибудь и получить неограниченное количество токенов», или что я могу получить два жетона, если захочу поделиться»???
Я только что получил сообщение, что «Я, Джейн, нет доступных токенов», я могу купить что-нибудь и получить неограниченное количество токенов», или что я могу получить два жетона, если захочу поделиться»???Здравствуйте! В соответствии с вашим предложением мы удалили логику токена. Обновите приложение и сообщите нам, если обнаружите какие-либо проблемы. Пожалуйста, обновите свой отзыв, если вы найдете это приложение полезным.
Разработчик, Ханджа Деви, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, используемые для отслеживания вас
Следующие данные могут использоваться для отслеживания вас в приложениях и на веб-сайтах, принадлежащих другим компаниям:
- Покупки
- Идентификаторы
- Данные об использовании
- Диагностика
Данные, связанные с вами
Следующие данные могут быть собраны и связаны с вашей личностью:
- Покупки
- Идентификаторы
- Данные об использовании
- Диагностика
Данные, не связанные с вами
Могут быть собраны следующие данные, но они не связаны с вашей личностью:
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста.
