9 видеоуроков по работе с Facebook Marketing API на языке R
6823 https://ppc.world/uploads/images/63/75/5ef5e6352464b-classic-car-1209334-1280.jpg 2020-07-21 2020-07-21 Другое Facebook + Instagram Таргет Аналитика ppc.world https://ppc.world/ https://ppc.world/build/resources/img/logo-v2.png 160 31- Аналитика 1
- Таргет 1
- Аналитика 1
- 21.
 07.2020
07.2020 - 2449
- Для экспертов
 07.2020
07.2020Избранное
Руководитель аналитики в агентстве Netpeak Алексей Селезнев записал девять уроков для работы c Facebook Marketing API на языке R. Они помогут авторизоваться в приложении, загрузить данные из рекламных кабинетов и выгрузить статистику в Power BI, Google Analytics и Яндекс.Метрику.
Алексей Селезнёв Netpeak
API Facebook — один из наиболее сложных из тех, с которыми в ходе многолетней практики мне приходилось работать. К тому же найти что-то в его справке тоже довольно трудно. При этом API помогает автоматизировать рутинные операции, в том числе составление отчетов по рекламным кампаниям.
При этом API помогает автоматизировать рутинные операции, в том числе составление отчетов по рекламным кампаниям.
Несколько лет назад я написал библиотеку rfacebookstat. Она избавляет от необходимости изучать огромную и плохо структурированную справку Facebook Marketing API.
В этой статье девять видеоуроков, которые помогут начать работать с API Facebook без погружения в документацию и без опыта в программировании. Длительность каждого — от 3 до 13 минут, так что много времени на изучение этого материала не потребуется.
Основные возможности пакета rfacebookstat
- Авторизация через вшитое в пакет приложение.
- Авторизация через ваше собственное приложение.
- Загрузка списка объектов (кампаний, групп объявлений, объявлений и т. д.) из рекламного кабинета.
- Загрузка статистики из рекламных кабинетов.
- Загрузка данных о расходах для дальнейшей передачи в Google Analytics.
Работу над интерфейсом библиотеки я вел несколько лет, постепенно делая ее удобнее и проще в использовании. И сейчас ее возможности и интерфейс стали достаточно стабильны и в ближайшем времени не будут изменяться.
И сейчас ее возможности и интерфейс стали достаточно стабильны и в ближайшем времени не будут изменяться.
Какой софт понадобится
Вам нужны:
- Язык R
- Среда разработки RStudio
И сам интерпретатор R, и среда разработки — бесплатное программное обеспечение.
С установкой на Windows никаких сложностей у вас не возникнет, но на всякий случай оставлю ссылку на видеоинструкцию.
Banner
Видеоуроки по работе с Facebook Marketing API
Плейлист со всеми видео уроками также доступен на YouTube.
Простая авторизация в Facebook Marketing API
Авторизация в Facebook Marketing API через собственное приложение
Автоматическая авторизация через файл .Renviron
Так-с.
 .. Мы вас не узнаём! Зайдёте под своим аккаунтом?
.. Мы вас не узнаём! Зайдёте под своим аккаунтом?Уже захожу Зарегистрировать аккаунт
Вы сможете:
- читать все материалы на ppc.world;
- добавлять лучшие статьи в Избранное;
- оставлять комментарии;
- получать рекомендации актуальных материалов.
Читайте также
Ко всем статьям
Импорт данных из Facebook в Google BigQuery при помощи языка R
376
10 мин.
В этой статье речь пойдет о том, как с помощью R можно с легкостью загружать данные из Facebook, приводить их к нужному виду и передавать в Google BigQuery, затем строя информативные отчеты в Data Studio.
В целом, данный метод универсален для любого источника данных, который имеет свой API. Достаточно погрузившись в изучение R, вы сможете применять эти принципы для похожих задач, модифицируя и совершенствуя функционал.
Перед тем, как приступить к написанию кода программы в RStudio, необходимо выполнить несколько подготовительных этапов:
- создание проекта в Google Cloud Platform;
- авторизация в Facebook с нужного аккаунта;
- подключение необходимых библиотек в RStudio.

О том, как начать работать с RStudio, можно узнать более подробно из этой статьи.
Для того, чтобы начать работать с GBQ, сначала необходимо обзавестись Google-аккаунтом, затем перейти по ссылке cloud.google.com и совершить ряд следующих действий:
- Нажимаем на кнопку «Get started for free».
- Указываем всю необходимую информацию в форме регистрации.
Данная процедура необходима для того, чтобы Google Cloud Platform смогла предоставить вам доступ к триал-версии с бонусными 300$ на ваш счет на период три месяца, чтобы вы могли протестировать все интересующие вас продукты. В процессе вас попросят указать номер кредитной карты, но не беспокойтесь — средства с вашей карты без подтверждения списаны не будут.
- После того, как все данные успешно внесены, вас попросят подтвердить указанную карту. Для этого нужно перейти, нажав на кнопку «Proceed to verification».
Затем загрузите указанные файлы (фото карты и фото паспорта владельца карты).![]()
После успешной загрузки этих файлов вас перенаправит на следующую страницу.
- Теперь перезагружаем страницу из шага 3 и попадаем на вкладку с информацией о платежном профиле.
- Открываем меню и переходим на вкладку «Home».
- Теперь нужно открыть выпадающий список и нажать на кнопку «New project». Вы можете увидеть, что Cloud Platform уже создала для вас первый проект, но я создам новый для того, чтобы показать все шаги.
- Далее необходимо указать название проекта. Организацию добавлять необязательно и можно оставить поле со значением по умолчанию.
Будьте внимательны, поскольку идентификатор проекта после создания нельзя изменять!
- После создания проекта видим уведомление об успешности операции. Выбираем созданный проект.
- Видим, что проект в выпадающем списке поменялся на только что созданный. Теперь можем перейти на вкладку Google BigQuery и перейти в рабочее пространство SQL.

- Перейдя на страницу рабочего пространства SQL, видим следующую картину:
В данный момент наш проект находится в режиме так называемой “песочницы”. Это означает, что все таблицы в наших наборах данных имеют максимальное время жизни 60 дней, после чего они будут автоматически удалены. Но не переживайте, как только ваш платежный профиль пройдет верификацию, вы сможете перейти к полноценной работе, нажав на кнопку “Upgrade”:
- Теперь нужно создать набор данных (dataset), в который далее будем загружать таблицы с данными:
Указываем название для набора данных и выбираем сервер, на котором он будет хранится. Остальные настройки советую оставить по умолчанию:
По умолчанию GBQ автоматически определит наиболее оптимальное расположение сервера.
- После того, как набор данных создан, можем увидеть его в выпадающем списке проекта.
Можно считать, что первый этап подготовки пройден. Теперь перейдем к вопросу авторизации в Facebook.
О том, как должен проходить процесс авторизации в Facebook со всеми подробностями можно узнать из этой статьи, здесь же я просто расскажу о ключевых моментах.
В первую очередь убедитесь в том, что профиль Facebook имеет все необходимые доступы к рекламным кабинетам, из которых вы хотите запросить данные.
Далее следует авторизоваться с вашего компьютера под этой учетной записью и получить токен, который понадобится для вызова API.
После этих операций можно приступать к работе внутри RStudio.
Если Вы еще не работали с R и RStudio — настоятельно рекомендую прочитать данную статью.
Итак, открываем новый файл в RStudio и начинаем устанавливать все необходимые пакеты. Нам понадобиться четыре библиотеки:
- rfacebookstat;
- bigrquery;
- dplyr;
- stringr.
Для их установки выполняем следующий код:
В процессе установки в консоле можем наблюдать сообщения про успешность операции:
Когда установлены все необходимые пакеты, нужно подключить четыре соответствующих библиотеки. Для этого выполняем следующий код:
Для этого выполняем следующий код:
После подключения библиотек приступаем к написанию кода нашей программы.
Для лучшего понимания поделим программу на несколько частей и поговорим о каждой отдельно:
- настройка пользовательских параметров;
- подключение к Facebook API;
- загрузка данных из Facebook и их форматирование;
- подключение к GBQ API;
- загрузка данных в GBQ.
Настройка пользовательских параметров
В этой части программы зададим определенные значения, которые часто будем использовать по ходу программы. Это нужно на случай корректировок. Например, вы захотите изменить диапазон дат: изменения вносим только в одном месте, а не везде, где эти значения используются. Это не обязательно, но упрощает нам работу.
Выглядит это так:
Подключение к Facebook API
Этот шаг подробно описан в статье про импорт расходов из Facebook в Google Analytics. Если коротко: вызываем функцию fbAuth() и получаем токен для работы с API.
Загрузка данных из Facebook и их форматирование
В пакете rfacebookstat существует довольно много полезных функций, которые позволяют загружать различные отчеты (о рекламных кампаниях, их расходах и т.п.). За каждый такой отчет отвечает вызов определенной функции из этого пакета. Подробнее о том, какие параметры нужно задавать функциям и в каком формате они предоставляют данные, можно узнать, выполнив простой запрос в консоле. Рассмотрим это на примере функции fbGetAccounts().
Как видим, после выполнения команды RStudio демонстрирует полную информацию об указанной функции.
Теперь вызовем функцию fbGetAccounts() и присвоим результат выполнения переменной my_accs.
Посмотрим на содержимое этой переменной, нажав на ее название в нашем окружении:
В этой переменной находится таблица, в которой приведена краткая полезная информация о доступных аккаунтах. Здесь нам интересно получить идентификатор нужного аккаунта (именно значение из колонки id. , а не account_id).
, а не account_id).
Я продемонстрирую выгрузку таких данных на примере своего аккаунта. Для этого скопирую идентификатор и присвою его переменной my_acc. Данная переменная понадобится для вызова следующей функции.
Далее будем рассматривать загрузку данных с информацией о рекламных расходах. Для этого нужно вызвать функцию fbGetCostData() и присвоить результат ее выполнения переменной cost_data.
После выполнения данной функции можно увидеть, что переменная cost_data была добавлена в окружение и содержит определенный набор данных:
Казалось бы, что уже сейчас можно приступать к отправке данных в GBQ, но есть один нюанс. Сейчас имена столбцов в таблице cost_data имеют вид “ga:SomeData”. Такой формат не подходит, если мы хотим загрузить данные в GBQ, поскольку название столбцов должно быть написано слитно, например, SomeData или Some_Data. Поэтому слегка отформатируем имена столбцов, убрав ненужные нам “ga:”. С этим нам поможет пакет stringr. Подробно описывать выполняемый код я не буду, так как это выходит за рамки данной статьи. Если вы проделали все этапы так, как это указано выше, то достигнете нужного результата. Собственно сам код, который следует выполнить:
С этим нам поможет пакет stringr. Подробно описывать выполняемый код я не буду, так как это выходит за рамки данной статьи. Если вы проделали все этапы так, как это указано выше, то достигнете нужного результата. Собственно сам код, который следует выполнить:
После выполнения получаем таблицу с нужным нам форматом.
Подключение к GBQ API и загрузка данных
Вот мы и приблизились к моменту загрузки данных в GBQ. Для отправки таблицы cost_data необходимо выполнить следующий код:
Функция bq_table() формирует список из значений, который с помощью конвейерного оператора будет передан в качестве значения параметра x функции bq_table_upload(). Конвейерный оператор нужен здесь только для упрощения кода. Подобный вариант тоже допустим:
В качестве значения project передаем идентификатор проекта GBQ. Значением параметра dataset служит название набора данных в этом проекте, а значение параметра table — это название таблицы в этом наборе данных.
Далее следует заполнить параметры функции bq_table_upload(). В параметр values передаем таблицу с данными cost_data, параметр create_disposition должен иметь значение “CREATE IF NEEDED” (если такой таблицы нет, то нужно ее создать), а параметр write_disposition должен иметь значение “WRITE_APPEND” (добавить данные к существующим).
В целом, это не исчерпывающий набор параметров, да и их значения могут меняться, в зависимости от целей. Подробнее об этом можно узнать из документации к соответствующему пакету.
Как только данный набор функций будет вызван, вас перенаправит в браузер для прохождения авторизации. Авторизуйтесь под нужным аккаунтом и дайте необходимые разрешения.
После этого в консоле вы можете увидеть предложение сохранить токен для дальнейшего использования. Рекомендую согласиться: в дальнейшем не придется проходить процесс авторизации повторно.
Теперь повторно выполните этот код и посмотрите в консоль. Если все выполнено правильно, то увидите соответствующее сообщение:
Осталось только проверить, все ли правильно передалось. Для этого перейдем в нужный проект и набор данных. Там видим только что созданную таблицу facebook_cost_data, которая содержит выгруженные из Facebook данные.
Для этого перейдем в нужный проект и набор данных. Там видим только что созданную таблицу facebook_cost_data, которая содержит выгруженные из Facebook данные.
Построение отчетов в Data Studio
Для получения возможности построения отчетов внутри Data Studio нужно добавить в качестве источника данных конкретную таблицу GBQ. Для этого переходим в Data Studio и создаем новый отчет. Также можно добавить источник данных в уже существующий отчет.
Добавляем коннектор BigQuery и в нем выбираем нужную нам таблицу:
Вуаля! Получаем источник данных, на основе которого строим любые отчеты!
24 сентября 2021
rfacebookstat package — RDocumentation
⚠️There’s a newer version (2.8.0) of this package. Take me there.
CRAN
For English speaking users
For use inside package manual run: help( package = "rfacebookstat")
Краткое описание.
Пакет для загрузки данных из Marketing API Facebook в R, а так же с помощью пакета вы можете управлять доступами пользователей к рекламный аккаунтам на Facebook.
Достижения
- rfacebookstat попал в top 40 пакетов, опубликованных на CRAN в августе 2018 года.
Видео уроки по работе с пакетом
rfacebookstatДля того, что бы вам было проще понять как работать с пакетом я записал 6 коротких видео уроков, все они доступны на YouTube в этом плейлисте.
- Простая авторизация
- Авторизация через собственное приложение
- Автоматическая авторизация через файл .Renviron
- Автоматическая авторизация через переменные среды на Windows
- Опции пакета и загрузка объектов из рекламных кабинетов.
- Загрузка статистики рекламы из рекламных кабинетов Facebook в R и визуализация данных.
- Как загрузить статистику рекламных кампаний из Facebook в Power BI.
- Как загрузить данные о расходах на рекламу из Facebook в Google Analytics
- Как загрузить данные о расходах и кликах из Facebook в Яндекс.Метрику.
- Как запрашивать данные из бизнес менеджера Facebook.
- Как разбить запрос статистики по рекламе Facebook на подзапросы по временным интервалам.
Установка пакета rfacebookstat
Для установки пакета запустите приведённый ниже код в RStudio или R консоли. Установка из главного репозитория CRAN:
install.packages("rfacebookstat")Устновка наиболее актульной dev версии пакета:
if(!"devtools" %in% installed.packages()[,1]){install.packages("devtools")}
devtools::install_github('selesnow/rfacebookstat')Пример кода
# переменные среды для авторизации
Sys.setenv("RFB_USER" = "selesnow",
"RFB_TOKEN_PATH" = "C:/Users/Alsey/fb_authdata")
# подключение пакета
library(rfacebookstat)
# опции
options(rfacebookstat.accounts_id = c("act_000000000", "act_1111111111),
rfacebookstat.business_id = 0000000000)
# авторизация в API
# краткосрочный токен
fbAuth()
# Загрузка объектов API
# бизнес менеджеры
my_fb_bm <- fbGetBusinessManagers()
# рекламные аккаунты
my_fb_acs <- fbGetAdAccounts()
# Объекты рекламного аккаунта
# кампании
my_fb_camp <- fbGetCampaigns()
# группы объявлений
my_fb_adsets <- fbGetAdSets()
# объявления
my_fb_ads <- fbGetAds()
# контент объявлений
my_fb_ad_content <- fbGetAdCreative()
# страницы связанные с рекламными аккаунтами
my_fb_page <- fbGetPages()
# приложения связанные с рекламными аккаунтами
my_fb_apps <- fbGetApps()
# ###################
# загрузка статистики
# ###################
my_fb_stats <- fbGetMarketingStat(level = "campaign",
fields = "account_name,campaign_name,impressions,clicks",
breakdowns = "device_platform",
date_start = "2018-08-01",
date_stop = "2018-08-07",
interval = "day")
Переменные среды
Как правило в rfacebookstat переменные среды используются для автоматизации процесса авторизации.
- RFB_TOKEN_PATH — Путь к папке в которой у вас хранится файл с раширением .rfb_auth.rds, в котором хранятся учётные данные;
- RFB_USER — Имя пользователя Facebook, который вы указали в аргументе username при прохождении авторизации с помощью функции
fbAuth(); - RFB_API_TOKEN — Полученный с помощью функции
fbAuth()токен доступа к API.
Опции
Опции используются для минимизации дублирования кода, и позволяют регулировать поведение пакета в ходе конкретной R сессии или одного скрипта. Как правила с помощью опций регулируют список рекламных аккаунтов и бизнес менеджеров с которыми будет вестись работа в ходе скрипта.
- rfacebookstat.api_version — Версия API к которой пакет будет направлять запросы, не рекомендуется изменять эту опцию;
- rfacebookstat.access_token — Ваш токен доступа, также не рекомендуется хранить его текстом в ваших скриптах;
- rfacebookstat.accounts_id — ID аккаунтов которые вы используете в скрипте по умолчанию, можно задавать вектором;
- rfacebookstat. business_id — ID бизнес менеджера который вы планируете использовать в скрипте по умолчанию
- rfacebookstat.token_path — Путь к папке, где хранятся файлы с учётными данными;
- rfacebookstat.username — Имя пользователя facebook;
- rfacebookstat.app_id — ID созданного вами приложения в Facebook для авторизации;
- rfacebookstat.app_secret — Секрет созданного вами приложения в Facebook.
 business_id — ID бизнес менеджера который вы планируете использовать в скрипте по умолчанию
business_id — ID бизнес менеджера который вы планируете использовать в скрипте по умолчаниюВиньетки
- ВИньетка про авторизацию в Facebook API:
vignette('rfacebookstat-authorization', package = 'rfacebookstat') - Виньетка посвящённая загрузке статистическим данных из рекламных аккаунтов:
vignette('rfacebookstat-get-statistics', package = 'rfacebookstat')
Статьи
- Как загрузить статистику рекламных кампаний из API Facebook с помощью языка R
- Как загрузить статистику из рекламных систем в Google BigQuery
- Импорт данных о расходах в Google Analytics с помощью R
Ссылки
- Документация по работе с пакетом rfacebookstat.
- Баг репорты, предложения по доработке и улучшению функционала rfacebookstat оставлять тут.
- Видео уроки по работе с пакетом rfacebookstat
- Список релизов.
- Группа в Вконтакте.
Автор пакета
Алексей Селезнёв, Head of analytics dept. at Netpeak Telegram Channel: R4marketing email: [email protected] facebook: facebook.com/selesnow blog: alexeyseleznev.wordpress.com
Copy Link
Link to current version
Version
Version
2.8.02.7.02.6.22.5.02.4.02.3.02.2.22.1.92.1.72.1.12.1.02.0.32.0.22.0.12.0.01.10.11.10.01.9.11.9.01.8.3
Down ChevronInstall
install.packages('rfacebookstat')Monthly Downloads
Version
2.5.0
License
MIT + file LICENSE
Homepage
https://selesnow.github.io/rfacebookstat/
Maintainer
Alexey Seleznev
Last Published
December 16th, 2021
Functions in rfacebookstat (2.
 5.0)
5.0)Search functions
Быстрый старт | Пророк
Python API
Prophet следует API модели sklearn . Мы создаем экземпляр класса Prophet , а затем вызываем его методы fit
predict . Входные данные для Prophet всегда представляют собой кадр данных с двумя столбцами: ds и y . Столбец ds (отметка даты) должен иметь формат, ожидаемый Pandas, в идеале ГГГГ-ММ-ДД для даты или ГГГГ-ММ-ДД ЧЧ:ММ:СС для отметки времени. 9Столбец 0005 y должен быть числовым и представляет измерение, которое мы хотим спрогнозировать.
В качестве примера рассмотрим временной ряд ежедневных просмотров страниц журнала для страницы Википедии для Пейтона Мэннинга. Мы собрали эти данные с помощью пакета Wikipediatrend в Р. Пейтон Мэннинг представляет собой хороший пример, поскольку он иллюстрирует некоторые особенности Пророка, такие как множественная сезонность, изменяющиеся темпы роста и возможность моделировать особые дни (такие как участие Мэннинга в плей-офф и в Суперкубке). CSV доступен здесь.
CSV доступен здесь.
Сначала мы импортируем данные:
1 2 3 | # Питон импортировать панд как pd от пророка импорт Пророк |
1 2 3 | # Питон
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
дф.голова()
|
| дс | г | |
|---|---|---|
| 0 | 10.12.2007 | 9.5 |
| 1 | 2007-12-11 | 8.519590 |
| 2 | 12.12.2007 | 8.183677 |
| 3 | 13.12.2007 | 8.072467 |
| 4 | 2007-12-14 | 7,893572 |
Мы подгоняем модель, создавая экземпляр нового объекта Prophet . Любые настройки процедуры прогнозирования передаются в конструктор. Затем вы вызываете его метод
Любые настройки процедуры прогнозирования передаются в конструктор. Затем вы вызываете его метод fit и передаете исторический фрейм данных. Примерка должна занять 1-5 секунд.
1 2 3 | # Питон м = Пророк() m.fit(df) |
Прогнозы затем делаются для фрейма данных со столбцом ds , содержащий даты, для которых должен быть сделан прогноз. Вы можете получить подходящий фрейм данных, который простирается в будущее на указанное количество дней, используя вспомогательный метод Prophet.make_future_dataframe . По умолчанию он также будет включать даты из истории, поэтому мы также увидим, что модель подходит.
1 2 3 | # Питон будущее = m.make_future_dataframe (периоды = 365) будущее.хвост() |
| дс | |
|---|---|
| 3265 | 15. 01.2017 01.2017 |
| 3266 | 2017-01-16 |
| 3267 | 17.01.2017 |
| 3268 | 2017-01-18 |
| 3269 | 2017-01-19 |
Метод предсказания назначит каждую строку в будущее предсказанное значение, которое он называет yhat . Если вы передадите исторические даты, это обеспечит подгонку в выборке. Объект прогноза здесь представляет собой новый фрейм данных, который включает в себя столбец и с прогнозом, а также столбцы для компонентов и интервалов неопределенности.
1 2 3 | # Питон прогноз = m.predict (будущее) прогноз[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail() |
| дс | йхат | yhat_lower | yhat_upper | |
|---|---|---|---|---|
| 3265 | 15. 01.2017 01.2017 | 8.211542 | 7.444742 | 8.5 |
| 3266 | 2017-01-16 | 8.536553 | 7.847804 | 9.211145 |
| 3267 | 17.01.2017 | 8.323968 | 7,541829 | 9.035461 |
| 3268 | 2017-01-18 | 8.156621 | 7.404457 | 8.830642 |
| 3269 | 2017-01-19 | 8.168561 | 7.438865 | 8. 8 |
Вы можете построить прогноз, позвонив в Метод Prophet.plot и передача вашего кадра данных прогноза.
1 2 | # Питон fig1 = m.plot(прогноз) |
Если вы хотите увидеть компоненты прогноза, вы можете использовать метод Prophet.. По умолчанию вы увидите тенденцию, годовую сезонность и недельную сезонность временного ряда. Если вы включите праздники, вы также увидите их здесь. plot_components
plot_components
1 2 | # Питон fig2 = m.plot_components (прогноз) |
Интерактивный рисунок прогноза и компонентов может быть создан с помощью plotly. Вам нужно будет установить plotly 4.0 или выше отдельно, так как по умолчанию он не будет установлен вместе с Prophet. Вам также потребуется установить пакеты Notebook и ipywidgets .
1 2 3 4 | # Питон из Prophet.plot импорта plot_plotly, plot_components_plotly plot_plotly (м, прогноз) |
1 2 | # Питон plot_components_plotly (м, прогноз) |
Дополнительные сведения о параметрах, доступных для каждого метода, доступны в строках документации, например, через help(Prophet) или help(Prophet. . Справочное руководство по R в CRAN содержит краткий список всех доступных функций, каждая из которых имеет эквивалент в Python. fit)
fit)
Р API
В R мы используем обычный API подбора модели. Мы предоставляем функцию Prophet , которая выполняет подгонку и возвращает объект модели. Затем вы можете вызвать , предсказать и , построить на этом объекте модели.
1 2 | # Р библиотека (пророк) |
1 2 3 | R [запись в консоль]: Загрузка требуемого пакета: Rcpp R [запись в консоль]: Загрузка требуемого пакета: rlang |
Сначала мы считываем данные и создаем результирующую переменную. Как и в API Python, это кадр данных со столбцами ds и y , содержащими дату и числовое значение соответственно. Столбец ds должен быть ГГГГ-ММ-ДД для даты или ГГГГ-ММ-ДД ЧЧ:ММ:СС для метки времени. Как и выше, здесь мы используем логарифмическое количество просмотров страницы Википедии Пейтона Мэннинга, доступное здесь.
Как и выше, здесь мы используем логарифмическое количество просмотров страницы Википедии Пейтона Мэннинга, доступное здесь.
1 2 | # Р
df <- read.csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
|
Мы вызываем функцию Prophet , чтобы соответствовать модели. Первый аргумент — исторический фрейм данных. Дополнительные аргументы управляют тем, как Prophet соответствует данным, и описаны на последующих страницах этой документации.
1 2 | # Р м <- пророк (df) |
Прогнозы выполняются в кадре данных со столбцом ds , содержащим даты, для которых должны быть сделаны прогнозы. Функция make_future_dataframe берет объект модели и количество периодов для прогнозирования и создает подходящий фрейм данных. По умолчанию он также будет включать исторические даты, чтобы мы могли оценить соответствие в выборке.
По умолчанию он также будет включать исторические даты, чтобы мы могли оценить соответствие в выборке.
1 2 3 | # Р будущее <- make_future_dataframe(м, периоды = 365) хвост (будущее) |
1 2 3 4 5 6 7 | дс 3265 2017-01-14 3266 2017-01-15 3267 2017-01-16 3268 2017-01-17 3269 2017-01-18 3270 2017-01-19 |
Как и в большинстве процедур моделирования в R, для получения нашего прогноза мы используем общую функцию прогнозирования . объект прогноза представляет собой кадр данных со столбцом yhat , содержащим прогноз. Он имеет дополнительные столбцы для интервалов неопределенности и сезонных компонентов.
1 2 3 | # Р
прогноз <- прогноз (м, будущее)
хвост (прогноз [c ('ds', 'yhat', 'yhat_lower', 'yhat_upper')])
|
1 2 3 4 5 6 7 | ds yhat yhat_lower yhat_upper 3265 14. |
 01.2017 7.8183597,071228 8,550957
3266 15.01.2017 8.200125 7.475725 8.869495
3267 16.01.2017 8.525104 7.747071 9.226915
3268 17.01.2017 8.312482 7.551904 9.046774
3269 18.01.2017 8.145098 7.3
01.2017 7.8183597,071228 8,550957
3266 15.01.2017 8.200125 7.475725 8.869495
3267 16.01.2017 8.525104 7.747071 9.226915
3268 17.01.2017 8.312482 7.551904 9.046774
3269 18.01.2017 8.145098 7.3 Вы можете использовать общую функцию plot для построения прогноза, передав модель и кадр данных прогноза.
1 2 | # Р сюжет(м, прогноз) |
Вы можете использовать функцию Prophet_plot_components для просмотра прогноза с разбивкой на тренд, недельную сезонность и годовую сезонность.
1 2 | # Р Prophet_plot_components (м, прогноз) |
Интерактивный график прогноза с использованием Dygraphs можно создать с помощью команды dyplot.prophet(m, прогноз) .![]()
Более подробная информация о параметрах, доступных для каждого метода, доступна в строках документации, например, через ?prophet или ?fit.prophet . Эта документация также доступна в справочном руководстве по CRAN.
Редактировать на GitHub
Интеллектуальный анализ данных Facebook с использованием R
В этом уроке мы увидим, как извлекать и анализировать данные Facebook с помощью R. Facebook пересек более 1 миллиарда активных пользователей. Facebook собрал самый обширный набор данных о поведении человека. В R мы можем извлекать данные из Facebook, а затем анализировать их. Майнинг в социальных сетях — одна из самых интересных частей науки о данных. Вы можете анализировать отношение к важному событию, извлекая информацию о событии из Facebook и получая информацию из данных в R.
| Извлечение данных Facebook с использованием R |
Шаг за шагом: Gustract Data из Facebook
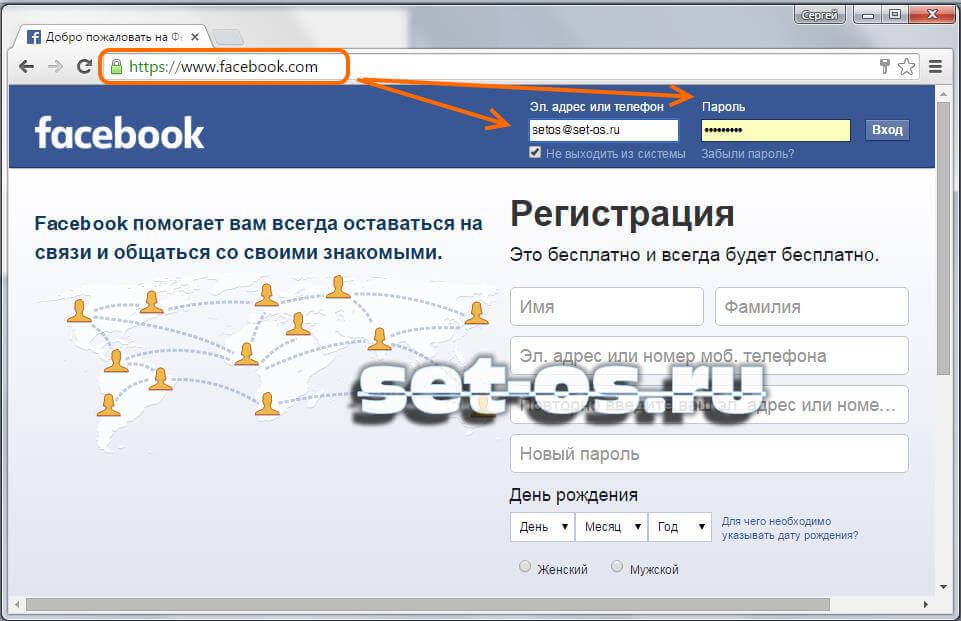
Шаг I: Facebook. Developers.facebook.com и зарегистрируйтесь, нажав кнопку Начать в правом верхнем углу страницы (см. снимок ниже). После этого откроется форма для регистрации, которую вам нужно заполнить, чтобы зарегистрироваться.
Developers.facebook.com и зарегистрируйтесь, нажав кнопку Начать в правом верхнем углу страницы (см. снимок ниже). После этого откроется форма для регистрации, которую вам нужно заполнить, чтобы зарегистрироваться.
| Регистрация разработчика Facebook |
Шаг II: Добавить новое приложение
. Как только вы закончите с регистрацией, как показано на стадии 1, вам нужно щелкнуть на . посмотрите снимок ниже). Затем выберите Добавить новое приложение из раскрывающегося списка.
| Facebook: Мои приложения |
Тогда вам нужно написать Отобразите имя приложения с идентификатором (введите любое имя) и выберите раскрывающийся список в категории ( Выберите «Образование»). нажмите кнопку Создать идентификатор приложения .
нажмите кнопку Создать идентификатор приложения .
| Создайте новое приложение |
ниже).
| Идентификатор приложения Fb и секрет приложения |
Шаг 4: Настройки OAuth
- В меню слева нажмите Добавить продукт Кнопка
- Нажмите на Facebook Войти ссылка
- Убедитесь, что в разделе «Настройки» выбрано значение «ДА» для входа клиента OAuth.
- Введите http://localhost:1410/ в Действительные URI перенаправления OAuth поле
- Нажмите кнопку Сохранить изменения
| URI перенаправления OAuth |
Если вы введете информацию неправильно, вы получите следующую ошибку:
Не удается загрузить URL-адрес: домен этого URL-адреса не включен в домены приложения.
 Чтобы иметь возможность загрузить этот URL-адрес, добавьте все домены и поддомены вашего приложения в поле «Домены приложений» в настройках вашего приложения.
Чтобы иметь возможность загрузить этот URL-адрес, добавьте все домены и поддомены вашего приложения в поле «Домены приложений» в настройках вашего приложения. Шаг 5: Напишите сценарий R
1. Установите необходимые пакеты
Перейдите в R и установите пакеты Rfacebook и RCurl . Запустите следующий код, чтобы установить их.
install.packages("Rfacebook")
install.packages("RCurl")
Пакет Rfacebook позволяет вам получить доступ к приложению Facebook через R.
библиотека (Rfacebook)
библиотека (RCurl)
3. Вставьте идентификатор приложения и секрет приложения ниже
. fb_oauth <- fbOAuth(app_id="183xxxxxxxx3748", app_secret="7bfxxxxxxxxxcf0",extended_permissions = TRUE)
Нажмите ENTER в R Console или CTRL+ENTER в R Studio.
Будет возвращено следующее сообщение:
Скопируйте и вставьте URL-адрес сайта в настройках приложения Facebook: http://localhost:1410/
Когда закончите, нажмите любую клавишу, чтобы продолжить...
Waiting for authentication in browser...
Press Esc/Ctrl + C to abort
| Authentication in Browser |
| Authentication Status |
4. Проверьте информацию об учетной записи профиля
я <- getUsers("me",token=fb_oauth, private_info=TRUE)
me$name
[1] "Deepanshu Bhalla"
Исправление: Ошибка
Вы получаете следующую ошибку?
Ошибка в callAPI(query, token): Для запроса информации о текущем пользователе необходимо использовать активный токен доступа.
Недавно Facebook внес изменения в API, которые вызывают ошибку в функциях пакета Rfacebook. См. метод ниже, чтобы исправить это.
Шаг 1: Запустите следующую программу
fbOAuth <- function(app_id, app_secret, extension_permissions=FALSE, legacy_permissions=FALSE, scope=NULL)
{
## получение URL-адреса обратного вызова
full_url <- oauth_callback()
full_url <- gsub("(.*localhost:[0 -9]{1,5}/).*", x=full_url, replace="\\1")
message <- paste("Скопируйте и вставьте URL-адрес сайта в настройках приложения Facebook:",
full_url, " \nПо завершении нажмите любую клавишу, чтобы продолжить...")
## предлагает пользователю ввести URL-адрес обратного вызова на странице приложения
invisible(readline(message))
## упрощенная версия примера в пакете httr
facebook <- oauth_endpoint(
authorize = "https://www.
access = "https ://graph.facebook.com/oauth/access_token")
myapp <- oauth_app("facebook", app_id, app_secret)
if (is.null(scope)) {
if (extended_permissions==TRUE){
scope <- c("День рождения_пользователя", "родной_город пользователя", "местоположение_пользователя", "отношения_пользователя",
"publish_actions","user_status","user_likes")
}
else { scope <- c("public_profile", "user_friends")}
if (legacy_permissions==scope TRUE) < - c "read_stream")
}
}if (packageVersion('httr') < "1.2"){
stop("Rfacebook требует httr версии 1.2.0 или выше")
}## с ранними версиями httr
if (packageVersion('httr') <= "0.2"){
facebook_token <- oauth3.0_token(facebook, myapp,
scope=scope)
fb_oauth <- sign_oauth3.0(facebook_token$access_token)
if (GET("https://graph.
}
}## меньше ранних версий httr
if (packageVersion('httr') > "0.2" & packageVersion('httr') <= "0.6.1"){
fb_oauth < - oauth3.0_token(facebook, myapp,
scope=scope, cache=FALSE)
if (GET("https://graph.facebook.com/me", config(token=fb_oauth))$status==200){
message("Аутентификация прошла успешно")
}
}## версия httr от 0,6 до 1,1
if (packageVersion('httr') > "0.6.1" & packageVersion('httr') < "1.2"){
Sys.setenv("HTTR_SERVER_PORT" = "1410/")
fb_oauth <- oauth3.0_token(facebook, myapp,
scope=scope, cache=FALSE)
if (GET("https://graph.facebook.com/me", config(token=fb_oauth))$status==200 ){
message("Аутентификация прошла успешно")
}
}## версия httr после 1.2
if (packageVersion('httr') >= "1.
fb_oauth <- 6oauth3.0_token scope=scope, cache=FALSE)
if (GET("https://graph.facebook.com/me", config(token=fb_oauth))$status==200){
message("Аутентификация прошла успешно")
}
}## определение версии API токена
error <- tryCatch(callAPI('https://graph.facebook.com/pablobarbera', fb_oauth),
error = function(e) e)
if (наследует(ошибка, 'ошибка')){
class(fb_oauth)[4] <- 'v2'
}
if (!inherits(ошибка, 'ошибка')) {
Class (fb_oauth) [4] <- 'v1'
}return (fb_oauth)
}
 facebook.com/dialog/oauth",
facebook.com/dialog/oauth",  facebook.com/me", config=6{{= 2)0$status «Аутентификация прошла успешно.»)
facebook.com/me", config=6{{= 2)0$status «Аутентификация прошла успешно.»)  2"){
2"){ Шаг 2: Запустите FBOAut номер перед использованием кода ниже
fb_oauth <- fbOAuth(app_id="183385******33748", app_secret="7bf18f8********4cf7def77cf0",extended_permissions = TRUE)
Теперь функция getUsers() будет работать.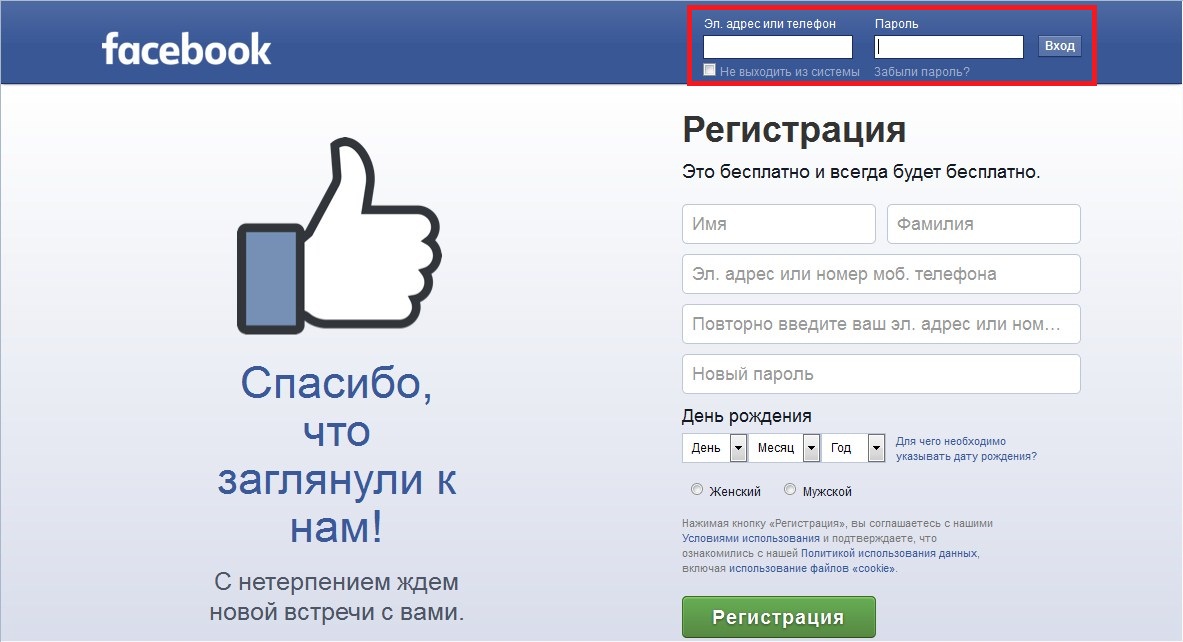
5. Список всех страниц, которые вам понравились
Предположим, вы хотите увидеть все страницы, которые вам нравились в прошлом.
лайки = getLikes(user="me", token = fb_oauth)
пример(likes$names, 10)
Функция sample() используется для перечисления примерно 10 случайных страниц, которые вам понравились.
[1] «Индус» «ADGPI — Индийская армия» «Мозговой юмор»
[4] "Уголок шуток" "Нью-Йорк Таймс" "Эй! Дополнительная ручка, хай?"
[7] "So You Think You Can Dance" "Shankar Tucker" "Rihanna"
[10] "Lindsey Stirling"
updateStatus("это просто тест", token=fb_oauth)
7. Поиск страниц, содержащих определенное ключевое слово
страницы <- searchPages(string="trump", token=fb_oauth, n=200)
В приведенном выше коде мы говорим R искать все страницы, которые содержат «козырь» в качестве ключевого слова. n= 200 относится к количеству возвращаемых страниц.
n= 200 относится к количеству возвращаемых страниц.
Возвращает 16 переменных. См. список переменных -
[1] "id" "about" "category"
[4] "description" "general_info" "likes" 0622 [7] «Ссылка» «Город» «Город»
[10] «страна» «широта» «долгота»
[13] «Имя» «Talking_about_count» «Имя пользователя»
[16] «
глава (страницы $ имя)
[1] «Дональд Дж. Трамп» «Иванка Трамп»
[3] «Фан-клуб президента Дональда Трампа» «Президент Дональд Дж. Трамп»
[5] «Дональд Трамп — мой президент» «Дональд Трамп на пост президента»
8. Извлечение списка сообщений со страницы Facebook
См. статус, опубликованный BBC News. Название страницы BBC News в Facebook — bbcnews.
page <- getPage(page="bbcnews", token=fb_oauth, n=200)
| Сведения о сообщениях |
Изображение выше обрезано. Он возвращает всего 11 переменных. См. список переменных -
[1] "from_id" "from_name" "message" "created_time"
[5] "тип" "ссылка" "id" "история"
[9] "likes_count" "comments_count" "shares_count
9. Получить все сообщения за определенную дату
Вы также можете указать дату начала и окончания сообщений, которые вы хотите извлечь.
page <- getPage("bbcnews", token=fb_oauth, n=100,
с='01.06.2016', until='20.03.2017')
10. Какой из этих постов получил наибольшее количество лайков ?
Чтобы узнать самую популярную публикацию BBCNews, вы можете отправить следующую строку кода.
summary = page[what.max(page$likes_count),]
summary$message
[1] «Могут ли взлететь круговые взлетно-посадочные полосы? (через BBC World Hacks)»
11. Какой из этих постов набрал максимум Комментарии?
Некоторые посты не так популярны с точки зрения лайков, но они собирают максимальное количество комментариев. Возможно, потому, что они противоречивы.
сводка1 = страница[которая.max(страница$comments_count),]
«Когда Ангела Меркель встретила Дональда Дж. Трампа, ее реакция говорила громче слов?
12. Каким постом чаще всего делились? сводка2 = страница[которая.max(страница$shares_count),]
«Ислам станет крупнейшей религией в мире к 2070 году, предполагает новое исследование».
13. Извлечь список пользователей, которым понравились максимально понравившиеся сообщения
С точки зрения маркетинга или развития веб-сайта очень важно знать о пользователях, которым понравился определенный пост.
post <- getPost(summary$id[1], token=fb_oauth, comments = FALSE, n.likes=2000)
Для просмотра списка людей:
likes <- post$likes
head(likes)
Result -
from_name from_id
Tommy Johnson 10154527932013108
Mirtunjay Raj 3994
Sony Joseph 1425572027
Note - I have edited the IDs to maintain privacy
14 . Извлечение комментариев FB к определенному сообщению
Чтобы узнать, что пользователи думают о публикации, важно проанализировать их комментарии.
post <- getPost(page$id[1], token=fb_oauth, n.comments=1000, likes=FALSE)
comment <- post$comments
fix(comments)
15. Какой комментарий получил больше всего лайков?
comments[what.max(comments$likes_count),]
16. Какие имена чаще всего встречаются в списке пользователей?
Какие имена чаще всего встречаются в списке пользователей?
глава (сортировка (таблица (users $ first_name), dec = TRUE), n = 3)
Дэвид Джон Дэниел
14 13 10
17. Извлечь реакции на последнюю публикацию
В Facebook больше, чем просто кнопка «Нравится». В прошлом году он запустил emoji (смайлики). Если пост получил 1 тыс. лайков, это не значит, что всем действительно нравится комментарий. Реакция может быть счастливой, грустной или злой.
post <- getReactions(post=page$id[1], token=fb_oauth)
love_count = 60, haha_count = 286, wow_count = 62, sad_count = 169,angry_count = 532
18. Получить сообщения определенной группы
Во-первых, функция searchGroup() ищет идентификатор группы, из которой вы хотите вытащить сообщения. Позже идентификатор группы используется в качестве входного значения в функции getGroup() .
# Извлечение сообщений из группы Machine Learning Facebook
id <- searchGroup(name="machinelearningforum", token=fb_oauth)
group <- getGroup(group_id=ids[1,]$id, token=fb_oauth, n=25)
В случае, если функция searchGroup() не смогла найти идентификатор группы. Вы можете найти его на веб-сайте lookup-id .
Конец примечаний
Интеллектуальный анализ текста (социальный) вызвал большой интерес за последние пару лет. Каждая компания начала анализировать мнение клиентов о своих продуктах и то, что клиенты говорят о компании в мире социальных сетей. Это помогает команде маркетинга определять маркетинговые стратегии, а команде разработчиков изменять будущие продукты на основе отзывов клиентов.
Об авторе:
Deepanshu основал ListenData с простой целью — сделать аналитику простой для понимания и использования. Он имеет более чем 10-летний опыт работы в области науки о данных. За время своего пребывания в должности он работал с глобальными клиентами в различных областях, таких как банковское дело, страхование, частный капитал, телекоммуникации и управление персоналом.
За время своего пребывания в должности он работал с глобальными клиентами в различных областях, таких как банковское дело, страхование, частный капитал, телекоммуникации и управление персоналом.
Facebook с открытым исходным кодом Многоязычная модель распознавания речи XLS-R с двумя миллиардами параметров
Домашняя страница InfoQ Новости Facebook открывает исходный код многоязычной модели распознавания речи XLS-R с двумя миллиардами параметров
ИИ, машинное обучение и инженерия данных
QCon London (27–29 марта 2023 г.): используйте правильные новые тенденции для решения своих инженерных задач.
Этот пункт в Японский
Закладки
18 января 2022 г. 2 мин читать
по
Энтони Алфорд
Напишите для InfoQ
Присоединяйтесь к сообществу экспертов. Повысьте свою видимость.
Повысьте свою видимость. Развивайте свою карьеру.Подробнее
Facebook AI Research (FAIR) XLS-R с открытым исходным кодом, модель ИИ для межъязыкового распознавания речи (SR). XSLR обучается на 436 000 часов звукового сопровождения речи на 128 языках, что на порядок больше, чем у крупнейших предыдущих моделей, и превосходит текущий уровень техники в нескольких нижестоящих задачах SR и перевода.
FAIR объявила о выпуске в своем блоге. XLS-R основан на wav2vec 2.0, самоконтролируемом подходе к изучению представлений речевого звука. Модель обучается на нескольких общедоступных наборах аудиоданных, включая VoxPopuli, недавно выпущенный корпус, содержащий аудиозаписи Европейского парламента. В целом модель была обучена на 128 европейских, азиатских и африканских языках, в том числе на 88 91 238 малоресурсных 91 239 языках, каждый из которых содержит менее 100 часов аудиоданных. XLS-R достиг нового современного уровня производительности в нескольких тестах, включая VoxLingua107, CommonVoice, VoxPopuli и несколько языков BABEL, а также перевод на английский язык на CoVoST-2. По данным команды FAIR,
По данным команды FAIR,
Мы верим, что это [исследование] позволит приложениям машинного обучения лучше понимать всю человеческую речь и станет катализатором дальнейших исследований, чтобы сделать речевые технологии более доступными во всем мире, особенно среди малообеспеченных групп населения. Мы продолжим улучшать наши алгоритмы, разрабатывая новые способы обучения с меньшим контролем и масштабируя наш подход к более чем 7000 языкам по всему миру.
Для обучения модели распознавания речи с глубоким обучением требуется большой набор данных, содержащий аудиоданные с соответствующими расшифровками текста. Получение такого набора данных может быть затруднено для языков с низким уровнем ресурсов из-за отсутствия легкодоступных данных. В этой ситуации исследователи обращаются к трансферному обучению: точной настройке моделей, предварительно обученных на большом общедоступном наборе данных. Предыдущая работа FAIR в этой области привела к созданию XLSR-53, модели с 300 миллионами параметров, обученной на 50 000 часов аудиоданных на 53 языках.
источник изображения: https://arxiv.org/abs/2111.09296
XLS-R основан на архитектуре wav2vec 2.0, которая использует функцию кодировщика сверточной нейронной сети (CNN) для преобразования звука в скрытое речевые представления, которые квантуются, а затем подаются в преобразователь. Во время обучения интервалы ввода маскируются, и цель модели состоит в том, чтобы идентифицировать квантованное представление замаскированного ввода. Полученная обученная модель представляет собой кодировщик аудиовхода; для нисходящих задач выходные данные кодера могут быть отправлены на линейный уровень для классификации и распознавания речи или на декодер для перевода.
Команда FAIR сравнила производительность XLS-R с базовыми моделями в нескольких тестовых задачах, включая автоматический перевод речи (AST), автоматическое распознавание речи (ASR), идентификацию языка и идентификацию говорящего. Для задачи AST по переводу с других языков на английский модель превзошла предыдущую работу в среднем на 7,4 BLEU. При переводе с английского язык XSL-R работает аналогично базовым вариантам; авторы предполагают, что это «вероятно, потому что данные на английском языке преобладают в обучающем корпусе» предыдущих моделей. В BABEL, самой сложной задаче, по мнению авторов, XSL-R превзошел базовые показатели «даже на языках, для которых XLS-R не добавляет никаких данных для предварительной подготовки», демонстрируя преимущества межъязыкового переноса. В целом авторы обнаружили, что XLS-R «лучше всего работает для языков с низким и средним уровнем ресурсов».
При переводе с английского язык XSL-R работает аналогично базовым вариантам; авторы предполагают, что это «вероятно, потому что данные на английском языке преобладают в обучающем корпусе» предыдущих моделей. В BABEL, самой сложной задаче, по мнению авторов, XSL-R превзошел базовые показатели «даже на языках, для которых XLS-R не добавляет никаких данных для предварительной подготовки», демонстрируя преимущества межъязыкового переноса. В целом авторы обнаружили, что XLS-R «лучше всего работает для языков с низким и средним уровнем ресурсов».
В ходе обсуждения работы в Твиттере читатель спросил соавтора Алексис Конно о подходах к обеспечению безопасности XSL-R в отношении предвзятости. Конно ответил,
Зависит от последующих задач и предубеждений, которые вы имеете в виду. Во время предварительной тренировки вы можете отфильтровать немаркированные данные. Во время тонкой настройки предстоит проделать массу работы по управлению генерацией (ASR/AST), и сложно сделать исчерпывающий итог.
